

March 22, 2021
Machine Learning for COVID Diagnosis Falls Short

(Rost9/Shutterstock)
In the earliest days of the pandemic, machine learning showed exceptional promise for COVID-19 diagnosis. Reliably, early machine learning models outperformed doctors in recognizing the telltale COVID-induced pneumonia on CT scans from hospitalized patients. However, more conventional testing methods quickly lapped machine learning-based methods, detecting the onset of COVID well before hospitalization and with greater accuracy. Now, a year later, a team of researchers led by the University of Cambridge has concluded a review of COVID diagnosis ML models, finding that even in 2021, none of the proposed models are suitable for clinical use.
The researchers whittled down 2,212 studies, eventually focusing on 62 studies – most of which were not peer-reviewed – published between January 1st and October 3rd of 2020, all of which presented machine learning models for diagnosing or predicting COVID-19 infection based on X-rays and/or CT scans. These 62 studies collectively described more than 300 such models – and the researchers found all of them substantially lacking.
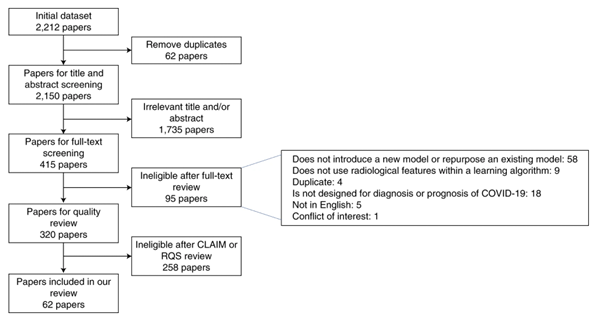
Image courtesy of the researchers.
“The international machine learning community went to enormous efforts to tackle the COVID-19 pandemic using machine learning,” said James Rudd, one of the senior authors of the review and a member of Cambridge’s Department of Medicine. “These early studies show promise, but they suffer from a high prevalence of deficiencies in methodology and reporting, with none of the literature we reviewed reaching the threshold of robustness and reproducibility essential to support use in clinical practice.”
The issues were wide-ranging: some studies suffered from poor data quality, while others were not reproducible and yet more exhibited biases in their design. By way of example, the authors pointed out that some of the datasets used to train some of the machine learning models included scans from children. “Since children are far less likely to get COVID-19 than adults, all the machine learning model could usefully do was to tell the difference between children and adults, since including images from children made the model highly biased,” explained Michael Roberts, a member of Cambridge’s Department of Applied Mathematics and Theoretical Physics.
Other datasets were too small, some were poorly labeled. Some models used the same data for training and testing. And, overwhelmingly, the designers of the models failed to meaningfully incorporate input from radiologists and clinicians who might have insight into the real-world implications of the data and diagnoses at hand. “Whether you’re using machine learning to predict the weather or how a disease might progress,” Roberts said, “it’s so important to make sure that different specialists are working together and speaking the same language.”
Better late than never, though, and to that end, the reviewers have some recommendations for machine learning model developers working on COVID diagnosis: know the data you’re working with, especially when it comes to public datasets; work with diverse, large datasets; and, crucially, include better documentation to allow for reproducibility.
To read the review article, click here.
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States