

March 15, 2021
Experts Disagree on the Utility of Large Language Models

(Ryzhi/Shutterstock)
Large language models like OpenAI’s GPT-3 and Google Brain’s Switch Transformer have caught the eye of AI experts, who have expressed surprise at the rapid pace of improvement. However, not everybody is jumping onto the bandwagon, and others see significant limitations in the new technology, as well as ethical implications.
There’s a veritable arms race occurring in the world of natural language processing (NLP), as large neural networks continually raise the bar on computer understanding of the written word. Over a matter of months, as OpenAI released GPT-3 last summer to Google Brain’s launch of Switch Transformer earlier this year, the number of parameters in these specialized transformer networks has gone from the hundreds of millions into the trillions.
Trained upon huge corpuses of words, these language models have displayed marked improvement in the capability to understand how words go together to express higher-level ideas. Simultaneously, the generative models have also shown greater skill in outputting text, to the point where it can be difficult to tell whether a chunk of prose (or a length of verse) was written by man or machine.
The sudden advance in NLP capabilities has caught the eye of AI practitioners as well as industry observers. Vaibhav Nivargi, who uses NLP technology to develop an automated IT ticketing system as the CTO and co-founder of Moveworks, says he was surprised by what large language models like GPT-3 could do.
Today, Moveworks relies in part on BERT to power the NLP capabilities of its automated communication system–a chatbot that has some understanding of common IT problems, if you will. The company has started playing around with the GPT-3 API, and Nivargi is confident that his company will be able to take advantage of the advances at some point.

Vaibhav-Nivargi, the CTO and founder of Moveworks, sees a lot of promise in large language models
What’s different about the large language models emerging today is how well they understand the basic characteristics of language, including words occur together, what words don’t go together, what is the right sequence of words, Nivargi said. From pairs of words to sentences to paragraphs to entire documents, the scalability and broad understanding demonstrated by the large models is what caught his eye.
“You start enabling an understanding of language in a mathematical sense. That’s what word-embedding ends up being,” Nivargi told Datanami. “Then these models start remembering things and memorizing things and understanding what is syntactically correct language and what are semantically accurate representations. What are these high-level concepts that come up? What ends up becoming domain-specific or domain-agnostic? The architectures of these models are then amenable to these last-mile fine tunings.”
The fine-tuning aspect of “these monster models” like BERT, RoBERTa, Google’s T5 make then amenable to last-mile fitting by the user, Nivargi said. “You can train them to do question and answering, or build up to more advanced use cases like fake news detection or text summarization,” he said. “But A, you don’t have to have a lot of data to do that, and B, you don’t have to have the infrastructure to train these fully from scratch.”
The capabilities of the large transformer models advanced so quickly that it led Forrester analyst Kjell Carlsson to say that we’re one step closer to achieving artificial general intelligence (AGI). “We do seem to be changing the art of the possible with these technology advances,” Carlsson told Datanami last month.
“We had transfer learning before, but that only worked when you’re in the same domain,” he said. “Now this is working going across domains and you end up with these bizarre instances where you end up with the model that has suddenly learned to count even though nobody ever trained it to count.”
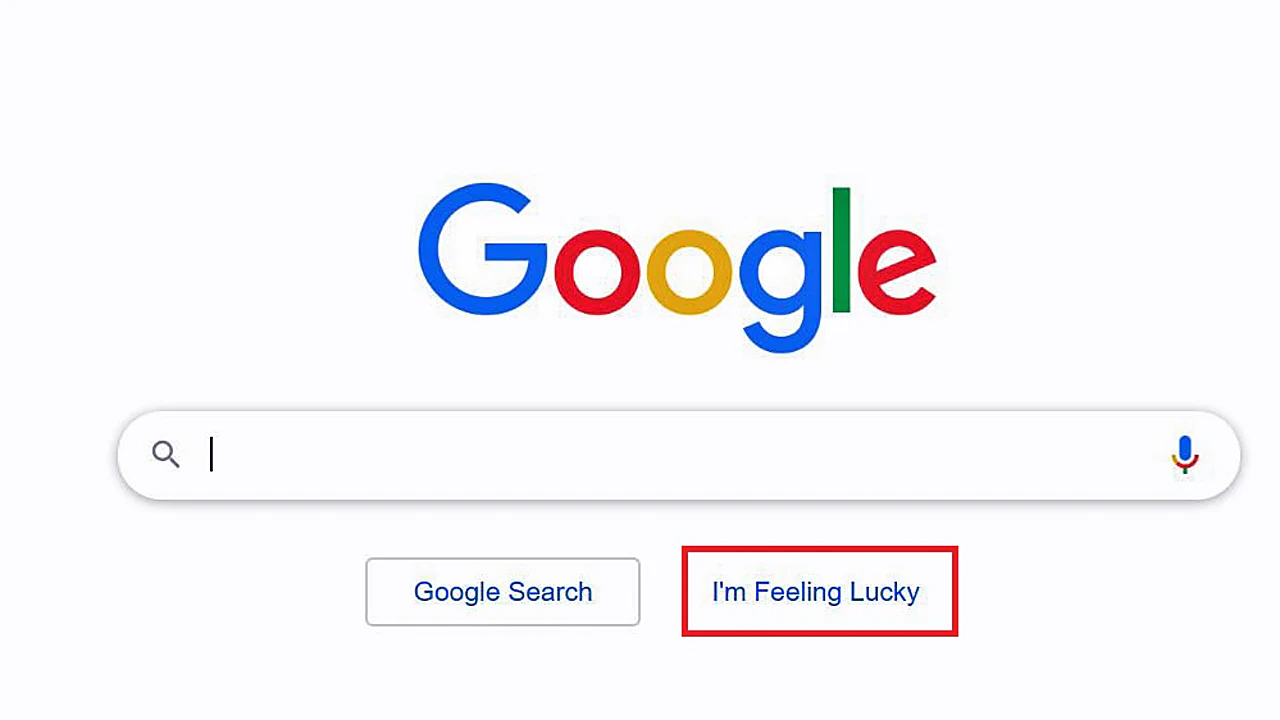
When asked, GPT-3 generated a Web page like this
Computer programming languages are also fair game for these large language models. Nivargi recounts how someone instructed GPT-3 to generate a Web page with a text box and two buttons, one that said “search” and another that said “I’m feeling lucky.”
“The user just described what he wanted, and GPT-3 did a pretty decent first attempt at a Google-style homepage,” he said. “So it was able to output a programming language.”
But these accomplishments (some would call them “parlor tricks”) don’t impress other AI experts, who express skepticism at whether these large language models are really pushing the bar as high as some people claim, and also whether the achievements in language models can be pushed outside of the language domain, such as into tabular data.
You can count Michelle Zhou, who invented IBM Watson Personality Insights at the Almaden lab and is the founder and CEO of Juji, among the skeptics.
“Yes, large scale language model will help AI become smarter in certain tasks, what we call the social and chit-chat tasks,” Zhou said. “But when it really come to the task that requires fine-grained knowledge, it’s not going to work. At least, not at the [current] state of the technology yet.”
There are still many unanswered questions in AI in general, let alone the narrower field of NLP and conversational AI, Zhou said. For example, even if an AI can understand what a person is asking with a relatively high degree of certainty, that doesn’t mean the AI will be able to respond to it.

Michelle Zhou, the founder and CEO of Juji, is skeptical about large language models
This “requires what I call not just understanding the language, but also the social, emotional intelligence,” Zhou said. “That’s why you see certain conversations go very smoothly and others very abruptly interrupted, even if you understand perfectly what the other person said.”
Figuring out how to imbue AI models with the social and emotional intelligence that enables them to converse more naturally and successfully with humans will require understanding the underlying unspoken words that aren’t said in a given conversation, Zhou said. This contextual understanding will be critical to getting computers to achieve the next leap forward in precision, and being able to use words precisely and with context.
Zhou provided this example:
“I grew up China. I know Chinese well,” she said. “[But] sometimes now, because I haven’t lived in China for a long time, I piece together certain words. I know every single word. But when they get together, I don’t understand what it means, because I’m not in the context!”
That is similar to how language models understand text right now, she said. “This large language model can compose some [words] together,” Zhou said. “Some look like they’re very intelligently created. But people may have a hard time understanding exactly what it means.”
Andrea Vattani, the chief scientist and founder of Spiketrap, is another AI expert who has reservations about the supposed breakthroughs of the large language models.

AI developers hope to use large language models to create more intelligent chatbots, including better question-answering and text summarization (a-image/Shutterstock)
“Those models are great and they’re very promising in certain fields, especially in language generation,” Vattani said. “But in terms of language understanding, they’re still very much behind.”
Spiketrap develops language understanding models that help its clients stay on top of what consumers are saying about their brands on the Internet and in social media. The need for precision in this work requires Spiketrap to develop proprietary models that are trained to identify specific pieces of text, and to be able to discern meaning at a higher level of accuracy than an out-of-the-box language model can achieve.
“For example, you might want to track a game called Among Us or something called FIFA, and distinguish from the game or the organization,” Vattani said. “Or you might want to track a TV show, Friends. Okay, so every time they say ‘friends’ are they talking about the TV show or are they talking about their friends? There’s a ton of those examples.”
Spiketrap eschews pre-built language models like BERT in favor of developing its own models, using technologies like TensorFlow and PyTorch. “I cannot give you too much of the secrete sauce we have,” Vattani allowed. “But you can say that a GPT-3 is probably less intelligent than a three-year-old.”

Andrew Vittani, the chief scientist and founder of Spiketrap, says large language models have hit a wall
And like with any three-year-old, GPT-3 has already developed its share of biases. “The world that they learn about is really the data set that you’re feeding to them,” he said. “If the data that you’re feeding to them is biased, they’re going to learn biases.”
Vattani won’t deny that GPT has shown improvement from the first to the second to the third, generation, but the increases have been accompanied with diminishing returns. When you pair that with the enormous size and expense of actually running GPT-3, the utility quickly deteriorates.
“Now we’re at a point where GPT-3 is already so huge that no small company would be able to run it on their own unless they had tons of servers,” he said. “They showed promise. But now they’re hitting a wall. And they’re [fulfilling] all the fears that people had [about bias and understanding]. Basically, we’re seeing the limits.”
If there’s one thing that Vattani, Zhou, Nivargi, and Carlsson can agree on, it’s that no single technology will single-handedly lift the entire field of AI to the next level. While these experts may disagree on whether language models represent an unexpected leap or are just another expected mile marker on AI’s long road, they all agreed that language models will achieve more when surrounded with supporting technologies.
In Carlsson’s case, he characterized the transformer models as the sharp point of a spear that also benefits from supporting cast members like synthetic data, reinforcement learning, federated learning, and causal inference. Vattani and Nivargi both cited the potential for large language models to be paired with knowledge graphs to bolster their capability to discern semantic meaning that’s more in tune with humans. And Zho sees language models as one part of a hybrid approach to lifting the AI bar.
“Computer science has been with us for 100 years,” Zhou said. “I have never seen anything have a leap where you use just one technology. Computers are just not smart.”
Related Items:
One Model to Rule Them All: Transformer Networks Usher in AI 2.0, Forrester Says
Three Tricks to Amplify Small Data for Deep Learning
OpenAI’s GPT-3 Language Generator Is Impressive, but Don’t Hold Your Breath for Skynet
Applications:
Artificial Intelligence
Technologies:
Middleware
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States