

January 5, 2021
Presto Poised for a Breakout Year as Data Explosion Continues
Presto, the federated SQL query engine developed at Facebook as a follow-on to Apache Hive, appears to be on the cusp of breaking out in a big way. That’s good news for customers who want to analyze a wide variety of data stored across on-prem and cloud locations, as well as vendors selling Presto software and services.
Facebook was an early user of Apache Hadoop, and the company in fact still uses Hadoop components to manage the data behind its massive social media empire. In 2010, technologists at the company developed a SQL engine called Apache Hive to run atop HDFS and utilize MapReduce, the dominant data processing engine at the time.
While Hive was great for running massive batch analytic jobs, it couldn’t replicate the ad hoc performance of traditional data warehouse platforms, which was a primary factor in the development of Presto. Facebook also unhooked its new SQL engine from MapReduce, enabling it to run outside of the Hadoop environment.
The most unique aspect of Presto’s architecture is its federated approach to analytics. While traditional and cloud data warehouses require the data to be stored in its own data store (usually a column-oriented relational database, also known as a MPP warehouse), Presto has no underlying data store (although it does require the Hive Metastore to store information about tables and partitions, similar to other big data technologies, including Spark SQL).![]()
This freedom allows Presto users to query multiple remote data sources with a single command. With connectors for everything from on-prem HDFS clusters and NoSQL stores to cloud-based object stores and relational databases, Presto has the potential to significantly reduce or eliminate the engineering and ETL effort required to get data moved and prepped for analysis, which continues to be a major obstacle to big data productivity.
That ease-of-use gives Presto users a big advantage, says Martin Traverso, a co-creator of Presto and the CTO at Starburst Data, one of the first vendors to offer Presto software and services.
“It basically means that with Presto and Starbust, you can kind of mediate all that, so users don’t have to think about how I’m going to organize my data, where am I going to place it. You put it where it’s more suitable to your business and your use case,” Traverso tells Datanami. “With Presto and Starburst, you can read data from your data lake, from your data warehouse. You can correlate them together without having to go through these expensive, complex ETL and curation processes before you can make any sense of that.”
Presto Rising
Presto emerged from Facebook in 2013, and has been a player in the big data scene for years, alongside other big data query technologies like Hive, Hive Tez, Spark SQL, and Impala. But for a variety of reasons, 2020 seemed to mark an uptick in Presto’s fortunes.![]()
The signs of Presto’s ascent come from multiple places: increased competition among software vendors, cloud service providers, and even open-source Presto foundations; rising interest in from venture capitalists keen on investing in Presto startups; a surge in use of cloud data warehouses; and other metrics, like Presto usage and project activity.
Starburst Data, which spun out of Teradata in 2017, enjoyed relatively little competition in the Presto world for its first three years. It landed blue chip customers, including Verizon, Comcast, Walmart, and the Financial Industry Regulatory Authority (FINRA), not to mention online firms like GrubHub and Zalando.
That changed in the middle of 2020 when a company called Ahana emerged to offer another commercial option for Presto users. Ahana, which debuted its first hosted Presto offering on AWS last month, is betting on the explosion in cloud data storage, says Steven Mih, the company’s CEO.
“The data explosion is really happening on the data lake,” Mih says. “The data lake is not just structured data. It’s semi-structured. It’s unstructured data. It’s all the data. This is 1,000x more than the data over here [traditional data warehouses]. Presto queries all of those things.”
Ahana is not only going head-to-head with Starburst Data on the commercial front. It’s also competing at the open source software foundation level. Ahana is a backer of the Presto Foundation, which launched in September 2019 under the auspices of The Linux Foundation. The Presto Foundation backs PrestoDB, which is the original version of Presto that came out of Facebook.
Starburst, for its part, has backed a fork of Presto called PrestoSQL, which has been governed by an organization called the Presto Software Foundation. That changed in late December, when Traverso and his Presto co-creators, Dain Sundstrom and David Phillips (who are also Starburst co-CTOs), announced a name change: PrestoSQL is now Trino, which is backed by the Trino Software Foundation.![]()
But even bigger news may be coming from Starburst. According to a December story in The Information, the Boston, Massachusetts company is reportedly in the middle of a Series C funding round that seeks to raise up to $118 million at a valuation of $1.6 billion. That is three times higher than the last round of funding in July 2020, which brought in $42 million to the company.
A representative from Starburst confirms that a Series C round is in the works, but says the figures in The Information’s story are “not quite accurate.” (Editor’s note: On Wednesday January 6, Starburst announced a $100-million Series C round that valued the company at $1.2 billion; click here to read the article).
But Starburst and Ahana won’t have the Presto market to themselves for long. In December, an Israeli company called Varada announced the availability of its cloud-based data analytics platform that features (you guessed it) Presto. Specifically, Varada, which launched in 2017, is a backer of the Presto SQL distribution, which is now named Trino.
There’s one more Presto vendor you may have heard of that’s starting to get traction too: Amazon Web Services. The company is banking on its Presto data warehousing service, called Amazon Athena, to help bolster its lake house strategy.
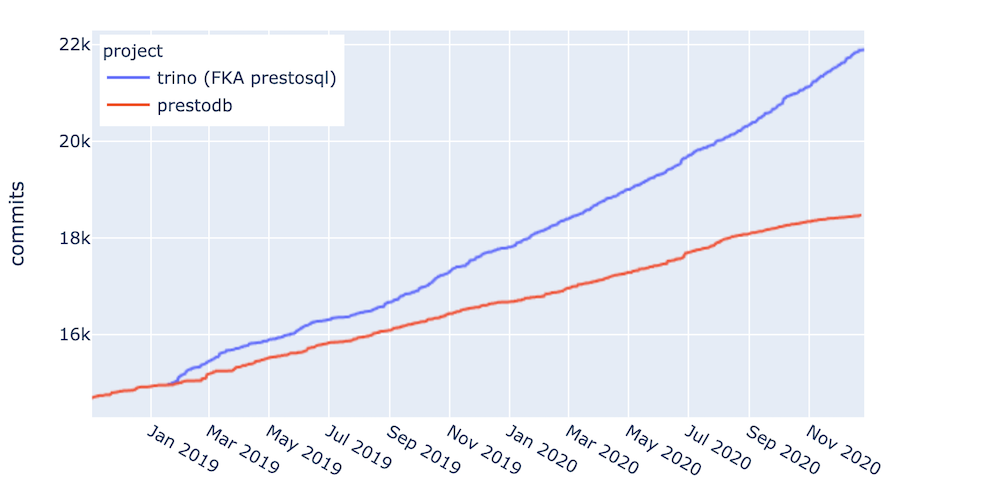
Presto commits are increasing for both Presto distros (graphic courtesy Trino)
Presto is moving its way up the database rankings, too. According to DB-Engines.com, Presto was the 40th most popular database, behind Snowflake, Impala, and dBase, and ahead of Greenplum and MarkLogic. That is up three places from a year ago. Activity in the open source realm is also increasing. A graph shared by Trino shows commits for both Trino (and PrestoSQL) and PrestoDB rising steadily from January 2019.
All told, 2020 is lining up to be a solid year for Presto, including the companies that use it and the vendors that provide software and services around it. As the big data boom and cloud data surges continue to reverberate across the industry, the prospects for mass centralization of data decreases, which increases the need for federated approaches. Presto isn’t the only game in town, but it’s increasingly looking like it’s one that many organizations will be hitching their big data wagons to.
Related Items:
Starburst Rides Presto to a $1.2B Valuation
Will the Presto Community Ever Be United Again?
Building Presto Business No Magic Trick for Starburst
Editor’s Note: This story was updated with a comment from Starburst Data, and with information about its Series C round of funding, which valued the company at $1.2 billion.
Applications:
Enterprise Analytics
Technologies:
Middleware
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States