

November 23, 2020
Data Headaches Targeted with a Dose of .BIG

Working with large numbers of files–and large files–remains a roadblock to productivity for data professionals around the world. Now a software startup named Exponam says it has come up with a potential solution to the problem with a new data file format called .BIG.
The co-founders of Exponam, Herman Weintraub and Roger Dunn, created the .BIG file format to address the data management headaches they experienced while serving the IT needs of financial services firms. While the public clouds finally enabled their clients to complete their petabyte-scale analyses in the timeframe allotted, they were still running into trouble getting results of those large queries into the hands of individual analysts for further study.
“They were declaring victory, but there was a part that was missing for a lot of the use cases that needed to be delivered to an end user, either for their own analysis purposes or for archival purpose, or bundling up and handed it off to a regulator,” says Dunn, who is the president of Exponan.
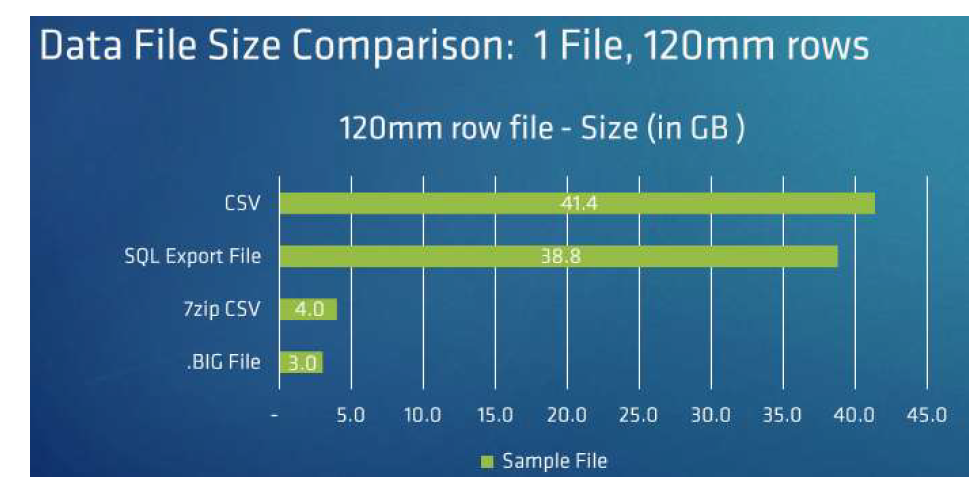
.BIG files boasts a compression advantage over other file types, Exponam says
“They’d say, well this is great, we have 100 million rows of data of security analysis data and we need to deliver it to Herman,” Dunn continues. “Herman says, thanks very much for the 100 million row CSV file. I double click on it, Excel goes away for half an hour, then comes up with an error saying I can only show you the first million rows. So you’ve given me nothing.”
Splitting the 100 million row CSV file into 100 different workbooks was one solution, but it created its own set of problems. So Dunn and Weintraub put their heads together and came up with a different solution: the .BIG file format.
.BIG is a column-oriented file format, similar in some respects to Parquet, which Dunn describes as the “grandad” of column-oriented formats. Data stored in the .BIG format is compressed and encrypted, using industry standard compression and encryption algorithms. But the real benefit of the format, and what they have invested much of their time in building, is how it maintains and tracks lineage.
Exponam provides a .BIG file viewer that allows users to view files that contain more than a billion rows of data. What’s unique is that users can sort and filter hundreds of millions of rows at a time from this viewer, and export the results to a BI tool or Excel for further analysis.
It’s all about giving data analysts, data scientists, and data engineers the ability to do their jobs, says Weintraub, who is the CEO of Exponam.![]()
“Roger and I have spent the last 20 years each in financial services technology spaces,” Weintraub says. “But no matter what type of project we’re doing, we end up coming back to fundamental issues of data security, the size, the efficiency of moving data around, the provenance of data, the lineage of data, the accessibility of data. And all of those different types of problems that we have come back down to this basic fundamental building blocks that we use when we move data, and interchange it and store I and archive it within all the different tools.”
According to Weintrab, it all boils down to relying on a handful of basic delimited data file formats, “most often CSVs or close derivatives, from JSON to XML or Parquet,” he says. “But the impact of using these basic formats is actually what cause a vast number of the headaches that we have when we implement various data solutions.”
The .BIG format offers 40% better compression than Parquet, the company says. Write speed is about the same as Parquet, but reads of .BIG files can be orders of magnitude faster, the company says. However, Parquet files are non-human readable and require specific software to open, whereas the .BIG files can be opened by anybody using its free file viewer. What’s more, data can be manipulated while it is compressed in the .BIG format, Exponan says
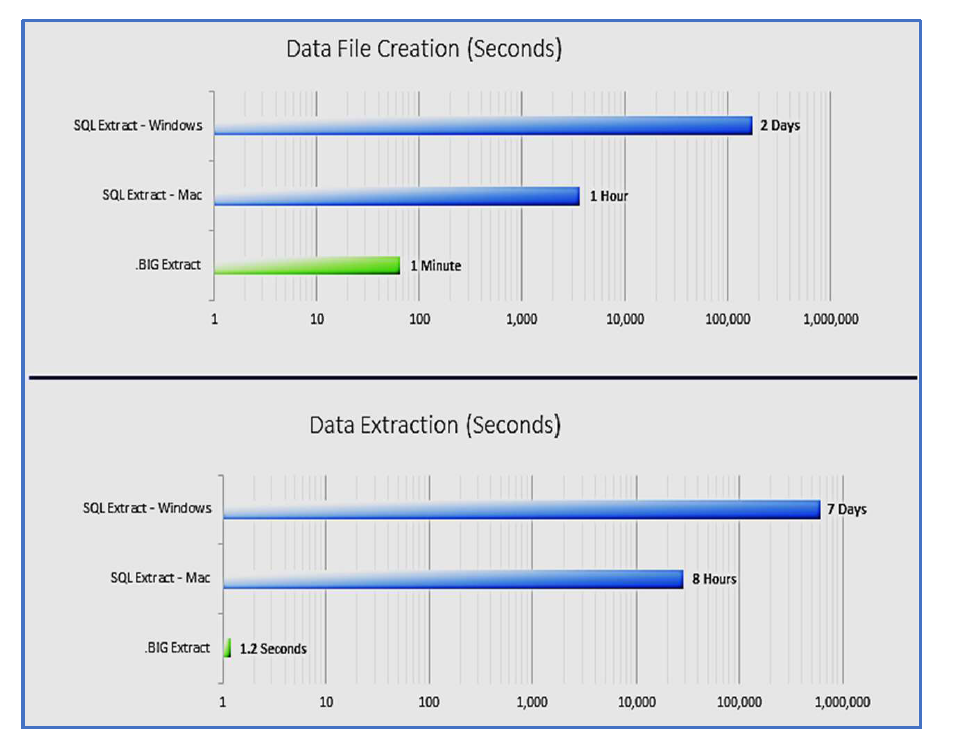
.BIG files versus other file types (Source: Exponam)
The .BIG format essentially is to CSV what a PDF file is to text data, the company says. “We can deliver that 100 million rows to a user in a payload that is small, tamper proof, and secure. It carries with it its provenance, any other metadata or associative properties that the producer of that file wants to bundle with it,” Dunn says.
“And when the user opens it locally, it opens in the data equivalent of Adobe Acrobat,” he continues. “It just opens instantly. It doesn’t matter that it’s 100 million rows. It opens instantly. And If the user wants, he can navigate around it as effortlessly as if he were working with a 100 million row file in Excel. If he wants to filter and sort and do the basic data and mining operation that you would normally do, more power to them.”
The goal is not to replace Excel or the other BI tools that users often use to work with data, Dunn says, but instead to accelerate the delivery of data into these tools.
“We’re not trying to be Excel. Excel does a great job being Excel,” says Dunn, who spent 18 years at Microsoft. “What we do is we kind of solve the last mile problem, where we can get the data out of these enormous data repositories that have obviously proliferated and exponentiate every day all around the world. We can get that data to the user so he can now use the tools that he loves. It could be Excel. It could be Spark. It could be Kx Systems. It could be any analysis tool that he wants. He can put it into Burt. He can use Pentaho or Informatica to move it there.”
Exponam, which is based in New York and New Hampshire, provides its .BIG file viewer free of charge. It’s always free to consume .BIG files. The company allows users to create .BIG files containing up to 3 million rows of data free of charge. Beyond that, it charges a fee for its software.
Related Items:
Big Data File Formats Demystified
Big Data Is Still Hard. Here’s Why
Editor’s note: This article was corrected. Exponam is based in the US, not the UK. Datanami regrets the error.
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States