

November 17, 2020
Snowflake Extends Its Data Warehouse with Pipelines, Services

Customers running atop Snowflake’s cloud data warehouse soon will find new functionality, including the ability to build ETL data pipelines , as well as the ability to expose pre-built analytic routines as data services. The company is also providing more granular security controls, and talking more publicly about its plan to provide analysis of unstructured data.
Snowflake today kicks off Data Cloud Summit 2020, the company’s first major public event since it raised $3.4 billion in a much-watched IPO two months ago. The summit offers a vehicle for Snowflake to publicize the engineering work it’s doing behind the scenes to boost the data analysis capabilities of its cloud, which is used by more than 3,100 customers.
The first of the “four pillars” of new features unveiled today is Snowpark, which the company is positioning as a new “developer experience” for enabling data engineers, data scientists, and developers to develop data routines, such as ETL/ELT, data preparation, and feature engineering pipelines. The routines can be written in multiple languages besides SQL, and are executed on Snowflake’s data cloud.
Customers can develop against the Snowpark DataFrame APIs using not only SQL, but also through Java and Python, according to Christian Kleinerman, SVP of product for Snowflake. It’s the first time these languages have been accepted on the platform.
“It’s a brand new way to program data in Snowflake,” Kleinerman said during a press briefing on Monday. “We now expect customers to go through any workflow that they want, whether data lake or data warehouse, or data engineering or data science–with the choice that they want. It could be SQL or it could be Python, all of it single platform, single copy of the data, all consistent, centrally data governed.”
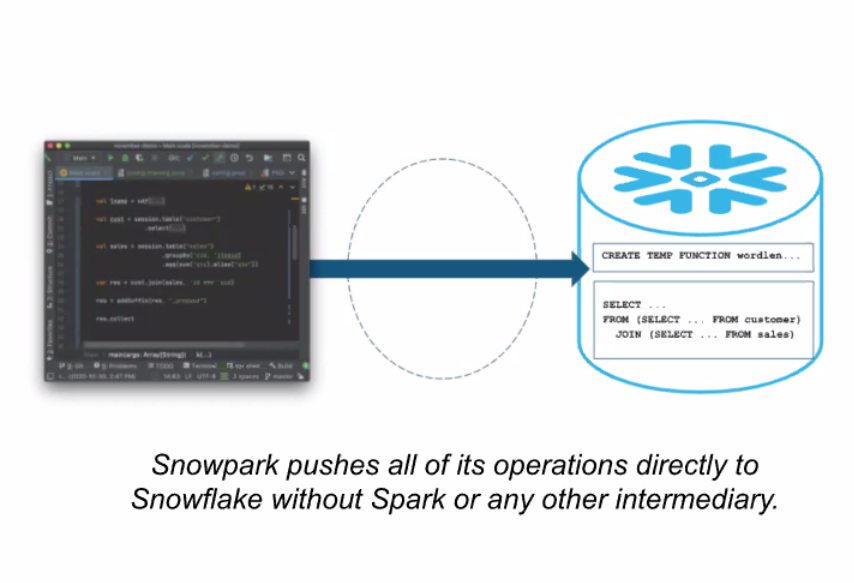
Snowpark lets users develop data processing tasks in Python, Java, and Scala, using a common DataFrame API, much like Spark
According to the company, Snowpark eliminates the need for customers to use other processing systems (i.e. Apache Spark) to execute common data science, data engineering, and data prep tasks. (It didn’t say it, but it also is a way to push back against Databricks, which is moving aggressively to build up its SQL data warehousing capabilities.)
Snowflake has not been shy about its goals to become the centralized store that customer and partners can use for buying and selling data. But now it’s allowing partners to sell access to data processing tasks that it has automated in the platform. Dubbed Data Services, the tasks allow partners to expose analytics that are running on its Data Marketplace
“We see our data sharing not just about sharing data or data sets or raw transactions,” Kleinerman said. “There are many use cases where what I want to offer to my customers, as a service provider, is an end-point, business logic where some data-powered experience can be made available to others without to having to share the actual data.”
For example, a service provider could build a job that analyzes whether somebody is involved in financial crime, Kleinerman said. Provided a name, the Data Service could return an answer to that question, without sharing all of the data that went into the answer.
The service has the potential to revolutionize access to data analysis services, Kleinerman said. “It’s not about just making data available, but also making data-powered services available,” he says.
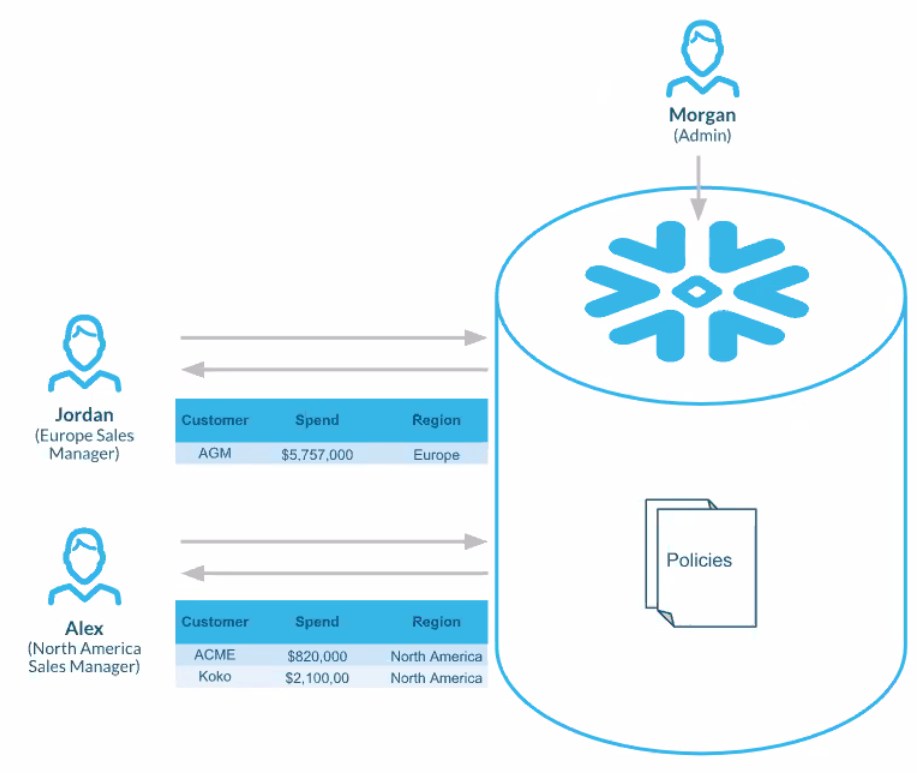
Snowflake has bolstered the row access control policies in its cloud data warehouse
Snowflake announced the concepts of tasks about a year ago. Now it’s enabling customers to take those repeatable jobs and run them in a serverless manner. According to Kleinerman, serverless tasks eliminate the need for the developer to allocate resources, such as storage or server instances, required to execute the task.
“They can say, here’s the transformation I want. Snowflake, you take care of resources, allocations, spinning up, spinning down,” he said. “It’s all in light of our constant obsession of simplifying user experience and reducing decisions that customers have to make in terms of embrasure and having the focus on data and getting value out of data.”
As data analysis is more widely shared, there is the potential for it to be more widely abused. On that vein, Snowflake is beginning to roll out a new row-based access control policy, which will bolster the ability of its customers to restrict what portions of a returned query specific groups are allowed to see.
The new feature, which is expected to entire private preview later this year, is an extension of a security capability it unveiled earlier this year, Kleinerman said.
“In June, we announced dynamic data masking as a way to conditionally redact, or partially redact, a column based on who’s querying,” he said. “What we’re announcing [today] is a complement to that policy, which is a row access policy, where now you can conditionally display or stop or hide a row depending on who’s querying.”
Snowflake’s final major announcement is around a topic that it has been mulling for some time: support for unstructured data. Data warehouses like Snowflake’s primarily are used to store highly structured and normalized data. In Snowflake’s case, it uses the snowflake schema, which is the format that it enforces across its Data Cloud.
But there are opportunities around analyzing unstructured data too, and Snowflake is now getting serious about moving that data into its cloud.
“Snowflake has exceled at both structured and semi-structured data from its inception,” Kleinerman said. “Many of our customers have said, I want you to take over our entire portfolio of data. I want you to deal with unsecured data, or file data.”
According to Kleinerman, the company is “far along in the support for files as a first-class concept in Snowflake,” and already has a few customer in its private preview, which it unveiled today.
The unstructured file support includes audio, video, and imaging files, as well as PDFs. According to the company’s press release, unstructured data management in Snowflake means “customers will be able to avoid accessing and managing multiple systems, deploy fine-grained governance over unstructured files and metadata, and discover new revenue opportunities thanks to gaining more complete insights.”
Related Items:
Snowflake Pops in ‘Largest Ever’ Software IPO
What Is a Data Cloud? And 11 Other Snowflake Enhancements
Snowflake Cashes In on Shift to Cloud Data Warehousing
Editor’s note: This story has been corrected. Snowpark did not launch with Python support. Datanami regrets the error.
Applications:
Enterprise Analytics
Tags:
cloud data warehouse, Data engineering, data science, Data Services, DataFrame, ELT, ETL, Java, machine learning, python, scala, sql
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States