

November 6, 2020
Is Kubernetes Really Necessary for Data Science?

(Mia-Stendal/Shutterstock)
It seems almost preordained at this point: Thou Shalt Run Thy Data Science Environment On a Cloud-Native Kubernetes Platform. This is 2020, after all. How else could it possibly run? But Tyler Whitehouse, a data scientist who worked at DARPA and IARPA, and his associates from Johns Hopkins University have a very different view on how to manage and distribute resources for data scientists. It does feature containers, but it doesn’t involve Kubernetes.
To hear Whitehouse tell it, the whole data science community has zigged, without ever considering whether they should have zagged. The community somehow came to the collective conclusion, he says, that software for managing and governing data science work – let’s call them data science platforms – should be centralized and should run in a cloud-native manner. That invariably means Kubernetes.
But that’s not how Whitehouse sees it. While Kubernetes is great for managing massive clusters running in the cloud, it’s not so good for managing the environments that data scientists do 90% of their day-to-day work in. For some reason, the industry seems to have willingly adopted inflexible a SaaS-based data science environment as its standard operating environment, and it’s getting in the way of progress.
Wrangling Data Science Workloads
The story behind Whitehouse’s startup, called Gigantum, starts about four years ago, when the data science community was trying to solve the reproducibility problem. The problem was, as more and larger machine learning models started getting deployed in the real world, data scientists needed better tools for managing their work environments, for tracking code, for proving providence, and lineage.
“Everybody in academia said ‘Hey, let’s just do what the commercial people are doing. Let’s just build cloud platforms,’” Whitehouse says. “And everybody else was like ‘Yeah, that’s a great idea!’ We, on the other hand, said nobody is going to use that.”
Data scientists desire the freedom to work with different systems (Bloomicon/Shutterstock)
“We” includes Whitehouse’s associates from Johns Hopkins, including Dean Kleissas, Randal Burns, Dean Kleissas, Jacob Vogelstein, and Joshua Vogelstein, who are his co-founders at Gigantum. The problem with cloud-native data science platforms built on Kubernetes, they decided, was that they don’t really solve the problems that data scientists actually need solved. Yes, data scientists need better tools for managing their work. But forcing them to use a data science platform that demands an underlying Kubernetes environment introduces even bigger problems along the way.
“Everybody is focused on providing automation around the cluster experience,” Whitehouse says. “Our insight was, that’s all well and good, but 90% of actual work happens a single instance. So the things you should automate…are the things that they find painful: Git versioning, best practices, environment configuration, transfer, interacting with GPUs–all the stuff that they have to do all the time, that eats up anywhere from 60% to 80% of their time. Just make that easy for them.”
Kubernetes isn’t necessarily bad. But in the context of data science, it makes workflows inflexible and doesn’t allow users to work in an ad-hoc manner. As a creative enterprise, data science is a messy, ad-hoc endeavor at its core.
“Kubernetes can be elastic, but it can’t be ad-hoc. The degree of freedom there is basically totally pre-determined from the instantiation of it,” Whitehouse tells Datanami. “You can have elasticity and clusters can come up and you can have all kind of stuff going on with nodes. But how are you just going to include a random workstation in Kubernetes? The answer is, you’re not.”
Rethinking the Architecture
Gigantum’s solution to this problem was to re-think the architecture. Containers are good, because they take away a lot of the complexity of standardizing the data science environment. The company decided to build its system atop Docker, which is the standard for containers.
But from that point on up, Gigantum’s solution looks quite different than a typical data science platform. Instead of relying on Kubernetes to handle the movement of data science workloads from workstations and laptops (where models are developed) to large GPU clusters in the cloud (where models are trained), the company decided that a simpler approach was better.
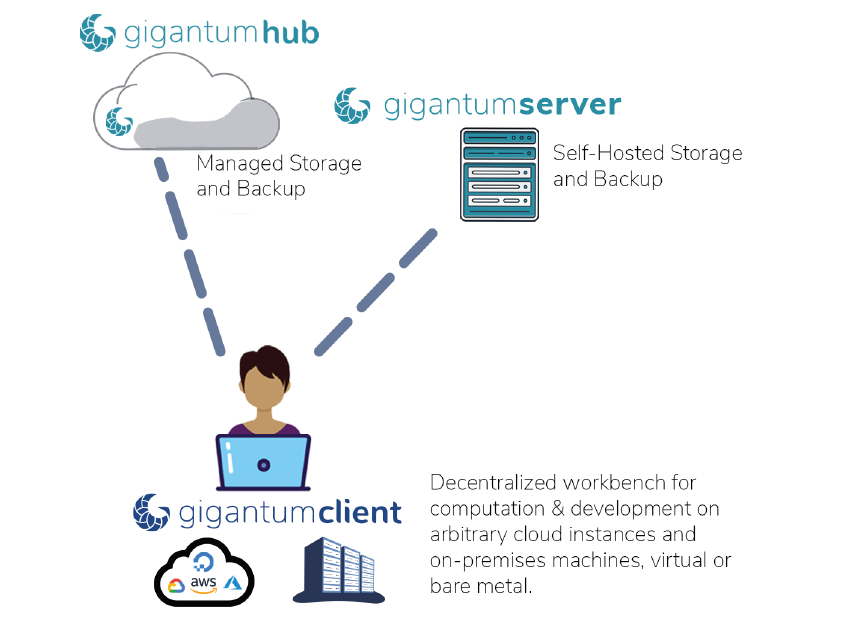
Gigantum has a different take on data science environments
Gigantum’s approach is loosely based on the model introduced by Git, the version control software, and GitHub and GitLab, which provide distributed implementations of Git for handling work among teams of disparate users. Like GitHub and GitLab, Gigantum allows data scientists to work locally on their choice of machines, and then reach out to external resources as needed.
“Basically, we just have a little cloud platform that runs in Docker, right in your laptop, and because we have this remote model for moving work back and forth, it means we can just push work back and forth between different people, working on different machines,” Whitehouse says. “But instead of just handling versioning of files, we’ll handle centralization of workflows. We’ll handle automating interactions with GPUs.”
From their workstations, Gigantum users have access to a range of data science resources, including Python libraries, Jupyter notebooks, and RStudio. If a data scientist finds she needs to move a model from her laptop to a larger cluster, perhaps to train the model or test it, then she simply opens an SSH client and remotely logs in.
“They sync their work, they run on the GPU for two to three hours. As soon as they’re done, they sync their work back to the other machine, and they move to their laptop,” Whitehouse says. “If you want to run on something that has a terabyte of RAM? Easy. You want to run on something that has 16GB of RAM? Easy. You want it to be bare metal? Fine. The idea is, it’s a containerized SaaS approaches that deploys anywhere and is super uniform.”
Gigantum adopted Nvidia’s CUDA to enable it to push data science workloads out to GPUs, which can be running on-prem or in the cloud. The software pushes the data scientist’s work out in Docker containers, which run in all the major cloud platforms. This gives the customer freedom to run wherever they want.
“The idea is self-determination and decentralization allow you to right-size the environment,” he says. “Because we provide these kinds of containerized work environments, this completely changes the game.”
A Bottoms-Up Approach
Gigantum’s software is agnostic to the actual machine learning framework and software that the data scientist chooses to use. So whether the users chooses PyTorch or TensorFlow, Spark or Kubeflow, it doesn’t really matter–Gigantum’s software will help data scientists manage those files as they’re moved among laptops and GPU systems for training.

Tyler Whitehouse is CEO and co-founder of Gigantum
That agnosticism is part and parcel of Gigantum’s ideology. “That kind of decision [about what frameworks to use] is best left to the user,” Whitehouse says. “You just want to make sure that whatever the user does, that they don’t have to deal with any of the technical nonsense around configuring machines, configuring environments, versioning–none of that. We do all that.”
In a way, Gigantum has flipped the script on data science environments. Whereas many vendors in the space have built their systems with a lot of top-down control built in and use Kubernetes as the ticket for scaling out horizontally, Gigantum has taken a bottoms-up approach that starts with the local data scientist working on a laptop as the starting point, with the possibility to scale up to large GPU systems via Docker if needed.
The advantage of the bottoms-up approach is that it maintains choice for the user, Whitehosue says. “If you try to move the other direction, if you’re trying to move from the cluster framework down to a single instance, or you want to add another instance or bare metal–that’s a disaster. That’s a huge engineering problem. That’s a complicated software development process, where they have to have a top down method of controlling it.
“That’s what people don’t understand,” he continues. “They think that by running on cluster, it’s distributed. Well, it’s distributed computation, but it’s top-down control, whereas we are decentralized control.”
Out of Stealth
Gigantum has been developing its platform for the last couple of years. It currently has around 400 users working on its platform on a weekly basis, and is about to pop above the radar and begin the sales process.
![]() The primary targets will be companies that can’t run in the cloud, such as banks and healthcare companies. They have been forced to try and develop their own solution to manage workloads, and it hasn’t worked out well, Whitehouse says.
The primary targets will be companies that can’t run in the cloud, such as banks and healthcare companies. They have been forced to try and develop their own solution to manage workloads, and it hasn’t worked out well, Whitehouse says.
“The big banks are forced to roll their own solutions and they know it’s a bad idea because, one, they don’t really know what they’re doing; two, they know they can be overcome by events quickly; three, it’s expensive; and it’s easy to get wrong. But they do it because they can’t they use any of these things,” i.e. other data science platforms.
Whitehouse admits that Gigantum is very new. But that freshness allows it to have another viewpoint on the problem, one that could result in a potential solution to a nagging problem.
“We chose this very unorthodox deployment methodology, and again everybody said you’re crazy,” he says. “We have a very different take on the economics of it all. We have a very different take on the user experience, and we have a very different take on the whole Gartner-ification of cloud-native platforms. We have this very different ideology. [But] it’s not just an ideology–it works, and in fact it works better in hybrid situations.”
Related Items:
The Biggest Reason Not to Go All In on Kubernetes
The Curious Case of Kubernetes In the Enterprise
Applications:
Artificial Intelligence
Vendors:
Gigantum
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States