

September 15, 2020
How to Build a Fair AI System

AI is being rapidly deployed at companies across industries, with businesses projected to double their spending in AI systems in the next three years. But AI is not the easiest technology to deploy, and even fully functional AI systems can pose business and customer risks. One key risk highlighted by recent news stories on AI in credit-lending, hiring, and healthcare applications is the potential for bias. As a consequence, some of these companies are being regulated by government agencies to ensure their AI models are fair.
ML models are trained on real-world examples to mimic historical outcomes on unseen data. This training data could be biased for several reasons, including limited number of data items representing protected groups and the potential for human bias to creep in during curation of the data. Unfortunately, models trained on biased data often perpetuate the biases in the decisions they make.
Ensuring fairness in business processes is not a new paradigm. For example, the U.S. Government prohibited discrimination in credit and real-estate transactions in the 1970s with fair lending laws like Equal Credit Opportunity Act (ECOA) and The Fair Housing Act (FHAct). In addition, the Equal Pay Act, Civil Rights Act, Rehabilitation Act, Age Discrimination in Employment Act, and Immigration Reform Act all provide broad protections against discrimination towards certain protected groups.
Building a fair AI requires a two-step process: (1) Understand Bias and (2) Address Potential Bias. In this article, we’re going to focus on the first topic.
Understanding Bias
Before you can address an issue, you need to first identify its existence. No company starts with a malicious intent of biasing its AI system against its users; instead, bias is inadvertently introduced due to a lack of awareness and transparency in the model development life cycle.
The following is a list of best practices to better understand and reduce the potential for bias during the ML development lifecycle.

(Kyokyo/Shutterstock)
Attain buy-in from key stakeholders
An unfair system is akin to a security risk that can have a material business impact. Implementing a fairness governance process requires material resources. Without support from the leadership team, the necessary
tasks needed to realize the process might not receive sufficient development capacity over other business priorities. A robust fairness-centric AI process therefore begins with buy-in from all stakeholders of the AI
system including the management team.
Appoint an ‘Internal Champion’
After securing buy-in, appoint a champion responsible to establish a fairness process. The champion communicates across teams including legal and compliance representatives to draft guidelines that are relevant to the company’s domain (e.g., healthcare, recruiting, etc.) and the team’s particular use case (e.g., recommending hospital readmission, determining insurance premium, assessing credit worthiness, etc.). There are several bias metrics like Equal Opportunity, Demographic Parity, etc. Choice of a fairness metric is use-case-dependent and lies in the hands of the practitioner.
After finalizing the guidelines, the champion educates the involved teams on the process. For it to be actionable, an AI fairness workflow warrants both data and model bias. In addition, it requires access to protected attributes that fairness is being assessed against, such as gender and race. In most cases it’s difficult to collect protected attributes, and in most cases it’s illegal to utilize them directly within models.
However, even when protected attributes are not used as model features, there could be proxy bias–another data field like Zip Code could be correlated to the protected attribute like race. Without having and measuring against protected attributes it becomes difficult to identify bias. One way that teams are solving this gap is by inferring the protected attributes, such as using census data to infer gender and race in the case of loan underwriting modeling.
Measure Bias
Next, we need to measure bias. Unfortunately, the inherent opaqueness of many types of machine learning models makes measuring their bias difficult. AI explainability, a recent research advancement, unlocks the AI black-box so humans can understand what’s going on inside AI models. This leads to a transparent assessment of bias to ensure AI-driven decisions are accountable and trustworthy.
Below is a sample fairness report for an ML model:
This particular report is for a model assessing risk to make lending decisions. It has additional metadata on the protected ‘race’ attribute. Using this report, a user can review group fairness and disparate impact using a wide range of fairness metrics. Applying the domain needs of a use case, users are recommended to focus on a particular metric (e.g., ‘False Positive Rate’) and a particular privileged class (e.g., Caucasian) to measure bias against.
In addition to tabular models like the lending one above, bias can also occur in text and image models. For example, the below image shows a text model that is measuring the toxicity of user-generated comments.
The sample bias report below shows how this model is assessing toxicity across racial and religious segments.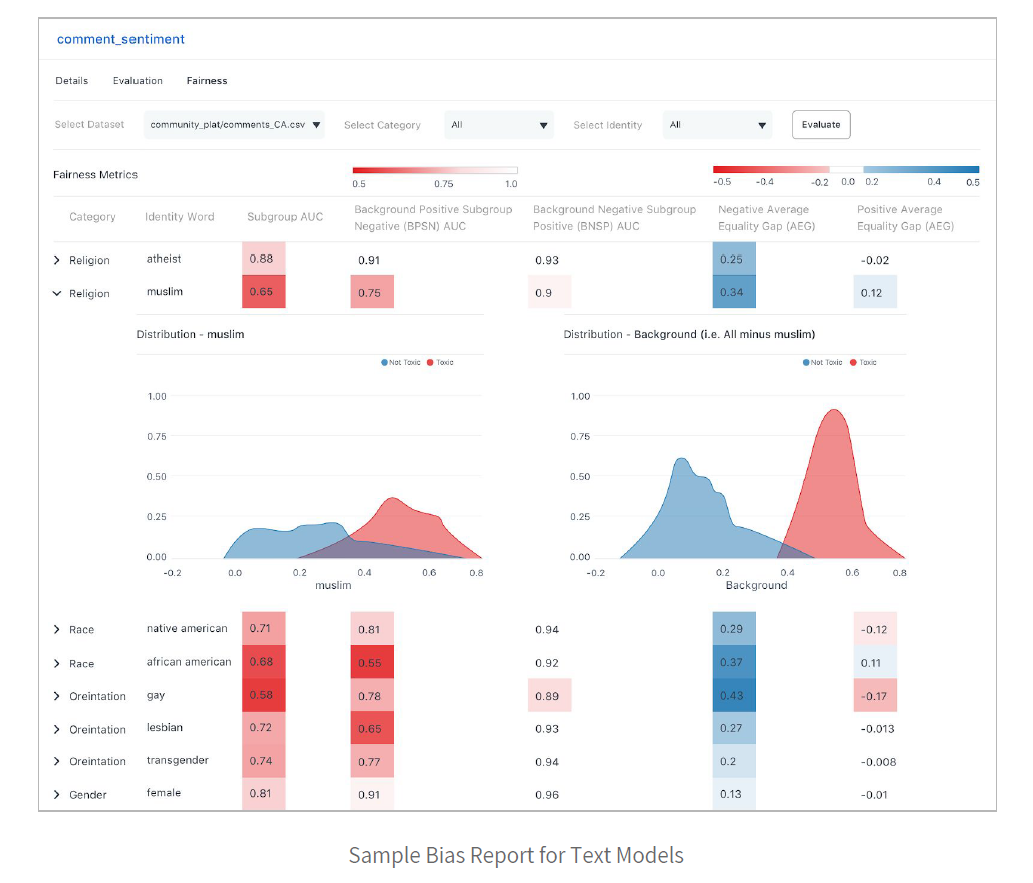
Notice how the heatmap identifies that the model is far less biased against ‘female’ and ‘atheist’ identity groups compared to the others. In this case, the ML developer might want to add more representative examples of the biased identity groups to the training set.
Fairness considerations for production models
Regardless of whether bias existed prior to deployment, it’s possible for bias to occur once the model is serving live traffic. Changes in bias typically occur as a result of the deployed model being fed input data that statistically differs from the data used to train it. It is thus best practice to monitor the model for relevant bias metrics after deployment. The screenshot below depicts what monitoring model accuracy metrics (one of the relevant types of metrics to track for potential bias) would look like.
In summary, AI presents a unique opportunity to quantify and thereby address bias in decision systems that were hitherto human-led and opaque decision systems.
About the author: Amit Paka is the founder and CPO at Fiddler. Previously, Amit was the senior director of product management at Samsung Mobile and the CEO and founder of Orange Peel Labs (acquired by Samsung). Amit also worked at PayPal, Microsoft, and Expedia.
Related Items:
LinkedIn Unveils Open-Source Toolkit for Detecting AI Bias
Opening Up Black Boxes with Explainable AI
Keeping Your Models on the Straight and Narrow
Sectors:
Financial Services
Vendors:
Fiddler Labs
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States