

August 20, 2020
Rush to Cloud Exposes Budgetary Pitfalls
(a-image/Shutterstock)
As the steady migration to the cloud became a stampede under COVID-19, it’s exposed some of the shortcoming in the shared computation model, particularly when it comes to individual spending. Now companies are taking a hard look at their cloud commitments in an attempt to lower financial exposure, particularly when it comes to big data analytics.
The COVID-19 pandemic has changed many aspects of life, including where companies get their computing power and where they store their data. While the amount of on-premise computing capacity still dwarfs the cloud, public clouds are growing quicker, and momentum to cloud has grown under COVID-19.
Data from Synergy Research Group shows that, during the second quarter ended June 30, spending on cloud infrastructure services exceeded $30 billion, which is a $7.5 billion increase, or 33% more than the second quarter of 2019. “As enterprises struggle to adapt to new norms, the advantages of public cloud are amplified,” Synergy Research’s Chief Analyst John Dinsdale said in a research brief.
The average company has increased its cloud spending by 59% from 2018 to 2020, according to a recent survey by IDG. Controlling costs has emerged as the number one concern about the public cloud, according to the IDG survey, with 40% of respondents in its survey declaring it the top challenge.
IT decision-makers are more concerned about spending than a host of data privacy, security, and governance concerns, it found. That jibes with the experience of ParkMyCloud, a Virginia-based company that helps companies manage their investments in, and exposure to, public cloud infrastructure.
“Five to 10 years ago, it was really focused on security–how secure is the cloud, are they going to get access to my data–all these kinds of things,” says Jay Chapel, vice president with ParkMyCloud. “Then there was a lot of problems related to governance and who has access to data sources.”
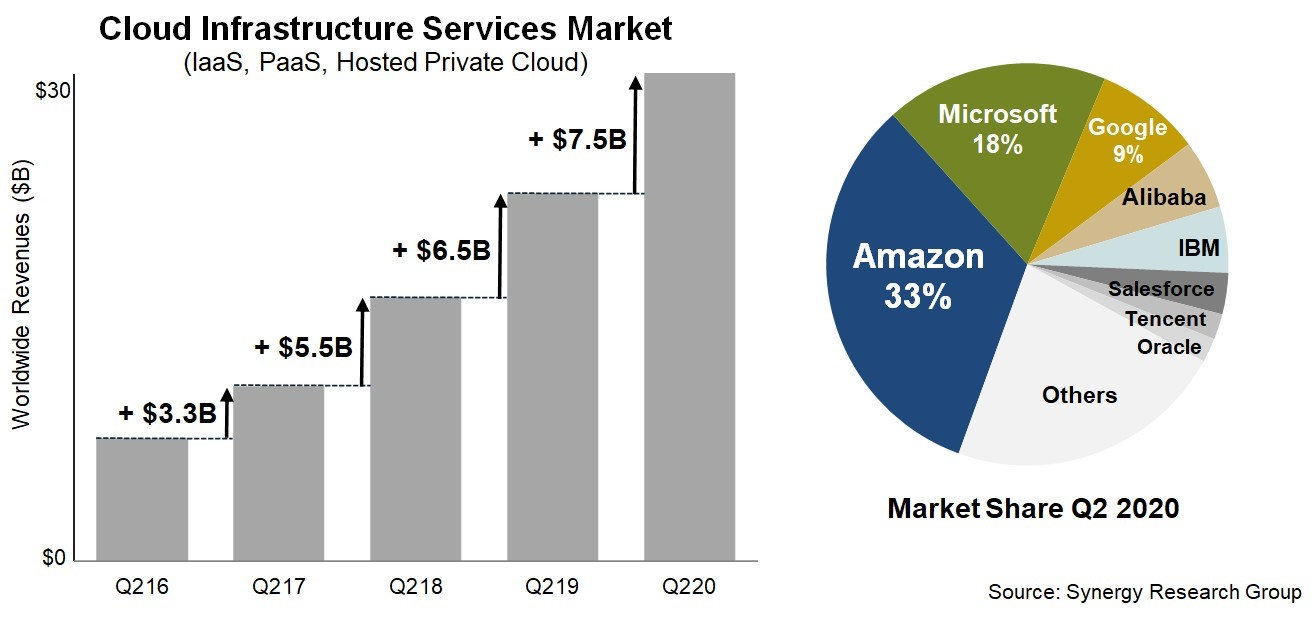
(Source: Synergy Research Group)
The conversation has changed, and today the top concern that customers express is keeping on top of spending, he says. “Now when we talk to people who are new in the cloud, they really have got the optimization message,” Chapel says.
While they’re aware of the spending problem, that doesn’t necessarily translate into action. According to Chapel, cloud customers are still overprovisioning their cloud resources, and paying way too much because of it.
“We analyzed all the resources in our platform and, generally speaking, customers are using less than 10% of what they provisioned in terms of capacity,” Chapel says. “Almost every customer we talk to that’s large, they found they’re spending more money than they expected.”
Overprovisioning is nothing new. Companies have been doing it with on-prem resources for years. It was not unusual to see X86 servers running at less than 10% of capacity (customers running expensive midrange and mainframe “big iron” gear traditionally have been better at sizing their servers).
Perhaps it’s not strange, then, that overprovisioning has continued in the cloud. But what is the source of this overprovisioning? That is a question that Chapel has asked.
“A lot of them haven’t done a proper sizing and scoping as they migrate to the cloud,” Chapel says. “Each size increase [from EC2 small to medium, for example] is a 50% price increase, basically. If you have overprovisioned your resource, that’s a huge increase the price vis a vis what you thought you had on prem when you’re moving to the cloud.”

(Source: IDG)
ParkMyCloud helps companies find the appropriately sized cloud resource to match their applications. They also help to reduce their clients’ cloud spending by identifying workloads that can be turned off at night and on weekends, which is another place to save money in the cloud.
For example, the company has a number of customers that run big data workloads through Databricks on the Azure cloud. ParkMyCloud can detect when data scientists start accessing Databricks and Azure resources in the morning, and when they’re done for the day.
“We see tens of thousands of those workloads spun up, burst up during the day, disappear at night, then come back tomorrow,” Chapel says. “That’s the way the cloud has been built, for elasticity. It reduces costs, and you’re essentially doing everything on demand. Not everything can be run like that. But we see a lot of that with big data.”
Apache Spark, on which the Databricks cloud is based, is a very powerful in-memory framework for big data analytics, but it’s notoriously hard to tune. With that in mind, it’s not surprising that Databricks has taken steps to help shield clients from excessive cloud bills. Databricks, which was founded by the creators of Spark, formed a close partnership with Microsoft in 2017, and rolled out its Azure service along with Microsoft in early 2018.
Spark plays prominently in big data analytics–and it’s also the culprit in some cloud wastage. Last month, Pepperdata released a study that found companies were essentially wasting 60% of their memory in Spark clusters. All told, Pepperdata estimated that companies would waste $17.6 billion on the cloud this year (across all clouds and workloads).
Companies can save the most money in the cloud by keeping a close eye on compute resources (as opposed to storage). They can invest in third-party tools that automatically turn off unused instances at night and on weekends, which can cut costs by upwards of 65%, according to Chapel.
But it’s not easy to manipulate other parts of the stack, like storage, which requires greater persistence of the underlying resource. “What are you going to do to it? You can’t shrink it. You can’t turn it off,” Chapel says. “So it’s just going to grow.”
Related Items:
Big Data Apps Wasting Billions in the Cloud
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States