

July 13, 2020
Three Privacy Enhancing Techniques That Can Bolster the COVID-19 Response

(Kat-Ka/Shutterstock)
The COVID-19 pandemic has shown us two things: The critical importance of healthcare data in fighting the spread of the disease, and our documented inability to harness it in a timely manner. And while it’s true that stringent regulations such as HIPAA pose an impediment to timely analytics, new privacy-enhancing techniques like homomorphic encryption, federated learning, and differential privacy can help us use data for the greater good without sacrificing individual data rights.
Homomorphic encryption is a relatively new computer science technique that allows mathematical and statistical functions to be performed on encrypted data. Even though the user cannot see the clear-text values of the data used as the input to the equation, she can be assured that the output will contain the correct answer.
It may sound a bit like magic, but Alon Kaufman, the co-founder and CEO of Duality Technologies and an expert in homomorphic encryption, assures us that the technique works as advertised.
“What you call magic or what I call math, that’s kind of the secret behind the science,” Kaufman tells Datanami. “It’s like you put this data in a locked box, and the operations are done without opening the box ever. But when you open the box, you do find the right answer there.”
Kaufman is a trained data scientist who worked for many years at RSA Security. He monitored the development of homomorphic encryption for years, but progress was slow.

(wk1003mike/Shutterstock)
“The math was proven about 11 years ago. It was a huge breakthrough, but it wasn’t practical for commercial use. It was very, very, very slow,” says Kaufman, who has a PhD in Computational Neuroscience and machine learning from the Hebrew University of Jerusalem. “But four years ago, I met the co-founders of Duality and I saw it was really ready to be commercialized and that’s what we finally tried to do.”
The real value of homomorphic encryption is that it enables teams of researchers to collaborate on sensitive data. In the case of the novel coronavirus, laws like HIPAA prevent researchers from sharing data that discloses the sensitive medical data of individuals. To protect privacy, researchers typically must undergo draconian steps to ensure that it’s devoid of any sensitive health data. That effectively puts the kibosh on a lot of potential analyses and modeling work that could be performed.
But by providing a relatively quick and easy method for shielding the disclosure of sensitive data, homomorphic encryption opens the door for researchers to resume sharing and collaborating with sensitive data, including healthcare data and other sensitive information, like location or financial data.
Duality Technologies has worked with banks to implement homomorphic encryption to enable contact tracing in anti-money laundering (AML) projects, where the banks want to collaborate to track down beneficial ownership, but they’re legally prevented from sharing their clients’ sensitive data.
“They know what algorithms they want to run. They know what models they want to run,” Kaufman says. “So everything is agreed upon–the structure, the models. The only thing they don’t want to share is actual raw data.”![]()
There are some limitations to homomorphic encryption. Users must be very familiar with the schema of the data, and the type of data that will be analyzed. And not all types of data analysis is a good fit for homomorphic encryption. For example, it can’t be used for exploring sensitive data sets.
“The minute you want data scientists to look into the data, to look for outliers, to look for specifics, that’s where it breaks down,” Kaufman says. “If you don’t need eyeballs, if it’s all algorithms, we know how to do it.”
There’s nothing preventing traditional machine learning algorithms, such as logistic regression and even more advanced neural network approaches from being used with homomorphic encryption. Duality doesn’t work with images or image recognition models, however.
The company, which is based in New Jersey and Israel, is currently working with one U.S. state on a COVID-19 project, but Kaufman was unable to provide many details.
Federated Learning
Another privacy enhanced technique is federated learning. This technique leverages the fact that machine learning models are essentially functions of the data they have been trained on, but don’t contain the actual field-level data that can violate individuals’ privacy rights. (They also have the advantage of being much smaller in size, and thus much more portable.)
According to Sri Ambati, the CEO and founder of H2O.ai, federated learning helps his clients in the healthcare space collaborate on data while still abiding by federal data regulations.
“One hundred and sixteen hospitals in the U.S. use H2O to fight sepsis and improve the operational efficiency of each of these hospitals without shipping data,” Ambati tells Datanami. “HIPAA prevents them from shipping data, even though they own most of these organizations. So they actually ship the models that are essentially capturing the best practices, rules that come out of the machine learning models.”
COVID-19 has devastated countries around the world, and there are many instances where data has not been used effectively, including difficulties with contact tracing. But COVID-19 is also forcing healthcare professionals to re-evaluate what works and try new things with data, which is a good thing, Ambati says.
“COVID has actually brought a lot of innovation on how to better use our data, how to better collaborate across hospitals,” he says. “Doctors have been able to reuse or at least learn from the experience of different treatment regimes. We’re seeing less impact this time around, a little higher success rate for intubated patients, mostly because of data, experience being shared.”
There will always be an advantage to centralizing the data–centralizing the shared experiences of many people–into one place. But federated approaches can provide a compelling alternative when the laws of data gravity or data privacy laws prevent organizations from amassing data in a central location for analysis or AI.
“I think there’s always going to be a batch mode of learning from data that you’re centralizing at the corporation level,” Ambati says. “But there’s also value for learning at the edge and federating the whole AI effort at the business unit-level or department level or the banking ATM level, then collect the models, which is a far more compressed form, and use them as an effective way to federate ML.”
Differential Privacy
Synthetic data is another privacy enhanced technique that has the potential to help the COVID-19 response.
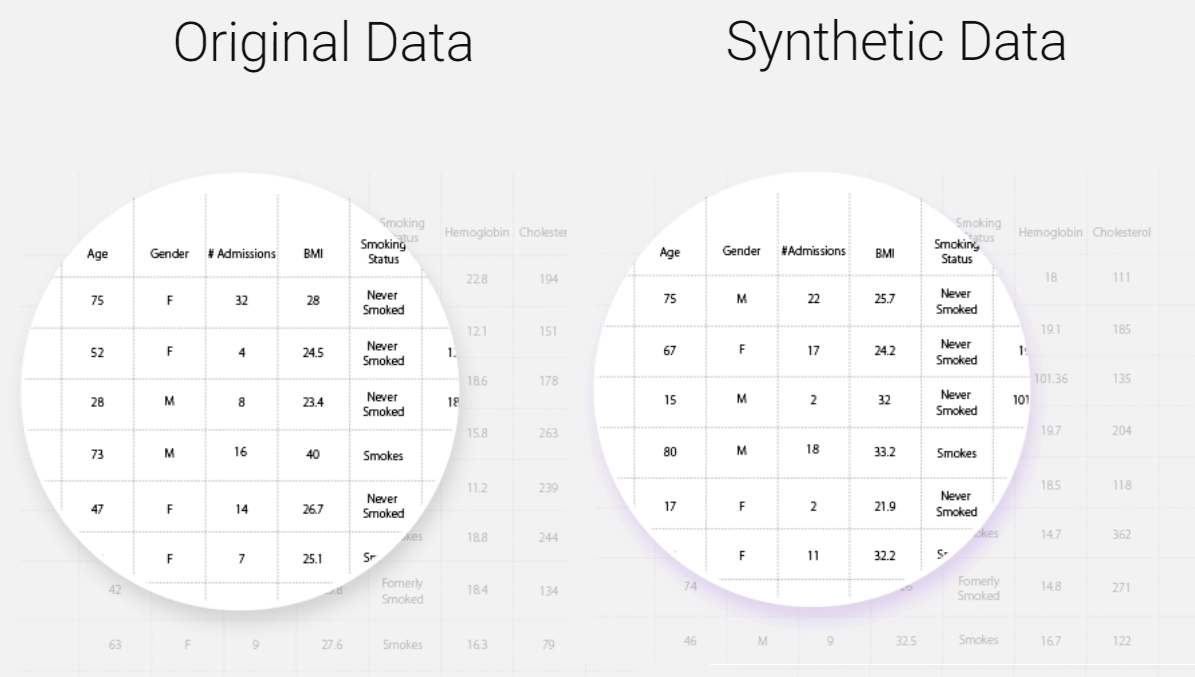
MDClone creates synthetic data that has the same properties as original data (Image courtesy MDClone)
Synthetic data is created by taking the actual values related to individual patients and creating a statistical representation, considering the various distributions and correlations. The actual values are then removed completely, and the statistical representation is used to produce new fictitious patients, which maintains the same statistical properties as the original, but no identifying information. Studies have proven that analytics performed on synthetic data systems yield the correct results but don’t expose the privacy of patients.
One of the purveyors of synthetic data in the healthcare space is MDClone. The Israeli company develops a complete big data analytics system that enables customer to analyze and build models with sensitive healthcare data without the risk of exposing individuals’ data.
“We know how to generate data that is not real but gets you the same exact statistical result and represent the real universe, but with no real patients involve,” says Ziv Ofek, the founder and CEO at MDClone.
MDClone’s application, which is based on Cloudera’s big data platform and uses its Impala database, brings together several components that collectively helps customers build analytical systems based on differential privacy concepts. It includes a longitudinal data engine that helps users connect disparate data sets together; a data discovery component that’s used to create cohorts that will help downstream users test hypothesis; as well as a synthetic data engine that generates statistically valid data from source data sets that are too sensitive to use in a clear-text manner.
MDClone users do not need to know what analyses or models they’re going to run the synthetic data through, Ofek says. That’s not the case with other differential privacy tools, which require new data to be generated for each query or analytics project, he says.
“This is one of the unique advantages in our patent,” Ofek says. “We are very agnostic. We don’t even know what the question you’re going to ask. We don’t even know what model you’re going to run.”
Another advantage is that users don’t have to be Hadoop experts or even analysts to work with the system, according to Robert Wartenfeld, MDClone’s chief medical officer. That lets a larger pool of users ask questions and interrogate the data in a healthcare setting, he says.![]()
“If I’m a physician or administrator, I have a question now. I don’t want to wait for weeks or months to get my answer because I just don’t have time,” Wartenfeld says. “I need the answer now. I need to make a change. I need to apply that knowledge to treat the patients.”
The speed-to-insight can be important in a clinical setting. But it’s critical in a pandemic situation, like we’re currently in with COVID-19. MDClone is actively assisting hospitals analyze healthcare data in support of their COVID-19 efforts, including running assessments for individuals presenting COVID-19 symptoms and modeling occupancy for beds in the ICU, Wartenfeld says.
Synthetic data has the potential to transform how the healthcare industry works with data, says Ofek, a serial entrepreneur who has worked in the healthcare space for two decades (Ofek also founded dbMotion, which was acquired by Allscripts for $235 million in 2013).
In the past, the sheer difficulty of working with healthcare data presented a substantial obstacle to effectively using it.
“Any question requires many different and time consuming and very long and expensive process to get answers to your question,” Ofek says. “In a previous life, they had to beg for someone to help them get data. The IT team [was] always busy, but you convince them after six months to get the data set. But it’s the wrong data sets. They forgot something.”
It wasn’t uncommon for it to take upwards of nine months for researchers to get access to data after they first requested it, he says. But with differential privacy, that timeline can be compressed substantially.
“What can happen to an organization? Instead of having two people ask two questions during 200 days, all of a sudden the paradigm shifts, and now you can have 200 people asking 200 questions every single day,” he says. “So all of a sudden, everything is different.”
And yet, the data remains the same.
Related Items:
COVID-19 Gives AI a Reality Check
For Data Lovers, COVID-19 Is the Best, Worst of Times
Yes, You Can Do AI Without Sacrificing Privacy
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States