

February 26, 2020
The Future of Computing is Distributed

(Frank Rohde/Shutterstock)
Distributed applications are not new. The first distributed applications were developed over 50 years ago with the arrival of computer networks, such as ARPANET. Since then, developers have leveraged distributed systems to scale out applications and services, including large-scale simulations, web serving, and big data processing. In my own career, which started more than 20 years ago, I have worked on distributed systems in the context of the internet, peer-to-peer networks, big data, and now, machine learning.
However, until recently, distributed applications have been the exception, rather than the norm. Even today, undergraduate students at most schools do very few projects involving distributed applications, if any. However, that is changing quickly.
Distributed Applications Will Soon Become the Norm, Rather Than the Exception
There are two major trends fueling this transformation: the end of Moore’s Law and the exploding computational demands of new machine learning applications. These trends are leading to a rapidly growing gap between application demands and single-node performance which leaves us with no choice but to distribute these applications.
Moore’s Law Is Dead
Moore’s Law, which has fueled the unprecedented growth of the computer industry over the past 40 years, has ended. Under Moore’s Law, processor performance famously doubled every 18 months. Today, however, it grows at a paltry 10-20% over the same period.
While Moore’s Law may have ended, the demand for increased compute has not. To address this challenge, computer architects have focused their attention on building domain-specific processors that trade generality for performance.

(Robert Lucian Crusitu/Shutterstock)
Domain-Specific Hardware Is Not Enough
As the heading suggests, domain-specific processors are optimized for specific workloads at the cost of generality. The canonical example of such a workload is deep learning, which is revolutionizing virtually every application domain, including financial services, industrial control, medical diagnosis, manufacturing, system optimization, and more.
To support deep learning workloads, companies have raced to build specialized processors, such as Nvidia’s GPUs and Google’s TPUs. However, while accelerators like GPUs and TPUs bring more computational power to the table, they essentially help to prolong Moore’s Law further into the future, not to fundamentally increase the rate of improvement.
The Triple Whammy of Deep Learning Application Demand
The demands of machine learning applications are increasing at a breakneck speed. Here are examples of three important workloads.
1. Training
According to a famous OpenAI blog post, the amount of computation required to achieve state-of-the-art machine learning results has roughly doubled every 3.4 months since 2012. This is equivalent to an increase of almost 40x every 18 months, which is 20x more than Moore’s Law! Thus, even if Moore’s Law hadn’t ended, it would still fall way short of satisfying the demands of these applications.
This explosive growth is not exclusive to esoteric machine learning applications, such as AlphaGo. Similar trends hold for mainstream application areas like computer vision and natural language processing. For example, consider two state-of-the-art neural machine translation (NMT) models, the seq2seq model from 2014 and a pretraining approach on tens of billions of sentence pairs from 2019. The ratio between the computational resources required by the two is over 5,000x (seq2seq takes approximately 0.09 PetaFLOPS-days as reported here, while per our estimates the latter approach takes 460 PetaFLOPS-days[1]). This corresponds to an annual increase of 5.5x. Similarly, consider ResNet 50 versus the ResNeXt 101 Instagram model, two state-of-the-art object recognition models which were published in 2015 and 2018, respectively. The ratio between the training times of the two is a staggering 11,000x (58min using 16 NVIDIA V100 GPUs for ResNet 50 vs 22 days using 336 GPUs for ResNetXt 101)[2]. This corresponds to an annual increase of 22x! These values dwarf Moore’s law, which suggests an increase of just 1.6x every year.
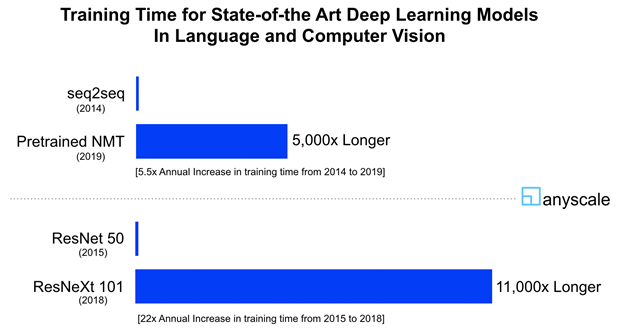
The growing gap between these demands and the capabilities of even specialized processors leaves system architects no choice but to distribute these computations. Recently, Google unveiled TPU v2 and v3 Pods that consist of up to 1,000 TPUs connected by a high-speed meshed network. Interestingly, while TPU v3 pods are 8x more powerful than TPU v2 pods, only 2x of this improvement is due to faster processors. The rest is due to TPU v3 pods becoming more distributed, i.e., employing 4x more processors than TPU v2 pods. Similarly, Nvidia has released two distributed AI systems, DGX-1 and DGX-2 with 8 and 16 GPUs, respectively. Furthermore, Nvidia recently acquired Mellanox Technologies, a premier network vendor, to bolster the connectivity between its GPUs in a datacenter.
2. Tuning
It gets worse. You don’t train a model just once. Typically, the quality of a model depends on a variety of hyperparameters, such as the number of layers, the number of hidden units, and the batch size. Finding the best model often requires searching among various hyperparameter settings. This process is called hyperparameter tuning, and it can be very expensive. For example, RoBERTa, a robust technique to pretrain NLP models, uses no fewer than 17 hyperparameters. Assuming a minimal two values per hyperparameter, the search space consists of over 130K configurations, and exploring these spaces, even partially, can require vast computational resources.
Another example of a hyperparameter tuning task is neural architecture search which automates the design of artificial neural networks by trying different architectures and picking the best performing one. Researchers are reporting that designing even a simple neural network can take hundreds of thousands of GPU computing days.
3. Simulations
While deep neural network models can typically leverage the advances in specialized hardware, not all ML algorithms can. In particular, reinforcement learning algorithms involve a large number of simulations. Due to their complex logic, these simulations are still best executed on general-purpose CPUs (they leverage GPUs only for rendering), so they do not benefit from the recent advances in hardware accelerators. For instance, in a recent blog post, OpenAI reported using 128,000 CPU cores and just 256 GPUs (i.e., 500x more CPUs than GPUs) to train a model that can defeat amateurs at Dota 2.
While Dota 2 is just a game, we are seeing an increase in the use of simulations in decision making applications, with several startups, such as Pathmind, Prowler, and Hash.ai emerging in this area. As simulators try to model the environment ever more accurately, their complexity increases. This adds another multiplicative factor to the computational complexity of reinforcement learning.
Summary
Big data and AI are fast transforming our world as we know it. While with any technology revolution there are dangers along the way, we see tremendous potential for this revolution to improve our lives in ways we scarcely could have imagined 10 years ago. However, to realize this promise we need to overcome the huge challenges posed by the rapidly growing gap between the demands of these applications and our hardware capabilities. To bridge this gap, we see no alternative but to distribute these applications. This calls for new software tools, frameworks, and curricula to train and empower developers to build such applications. This opens a new exciting era in computing.
About the author: Ion Stoica is a computer science professor at UC Berkeley  and a director of the RISELab. He is also the chairman and a co-founder of Anyscale, which is developing new tools and distributed systems, such as Ray, to usher application developers into the new distributed era. Formerly, Stoica was a director of the AMPLab. Stoica is also a co-founder and executive chairman of Databricks, and was one of Datanami’s People to Watch for 2017.
and a director of the RISELab. He is also the chairman and a co-founder of Anyscale, which is developing new tools and distributed systems, such as Ray, to usher application developers into the new distributed era. Formerly, Stoica was a director of the AMPLab. Stoica is also a co-founder and executive chairman of Databricks, and was one of Datanami’s People to Watch for 2017.
Related Items:
Anyscale Emerges from Stealth with Plan to Scale Ray
The Next Data Revolution: Intelligent Real-Time Decisions
Why Every Python Developer Will Love Ray
[1] As reported in this paper, it took more than three months using 512 V100 GPUs to (pre)train the NMT model. Assuming 33% GPU utilization (as suggested in this OpenAI blog), and assuming V100 uses half-precision, we get approximately 90 days * 512 GPUs * 30 TFLOPs * 0.33 = 460 PetaFLOPS-days. This yields 460/0.09 = 5,100.
[2] Assuming same GPU types, we have (22 days * 336 GPUs) / (1/24 days * 16 GPUs) = 11,088.
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States