

February 12, 2020
Microsoft Details Massive, 17-Billion Parameter Language Model
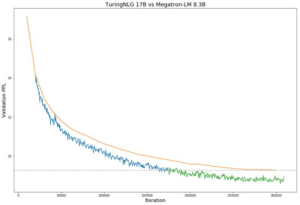
Comparison of the validation perplexity of Megatron-8B parameter model (orange line) vs T-NLG 17B model during training (blue and green lines). (Image source: Microsoft Research)
Microsoft this week took the covers off Turing Natural Language Generation (T-NLG), a massive new deep learning model that it says will push the bounds of AI in the field of natural language processing (NLP).
With 17 billion parameters, T-NLG is “the largest [language] model ever published,” Microsoft Research says in a February 10 blog post. The model is designed as a generative model – that is, one that generates language, which is handy for real-world applications like conversational agents, question and answer systems, and summarizing documents.
The bigger the model, the better it is, the technology giant says. “We have observed that the bigger the model and the more diverse and comprehensive the pretraining data, the better it performs at generalizing to multiple downstream tasks even with fewer training examples,” writes Corby Rosset, an applied scientist with Microsoft Research, in the blog.
To prove that might makes right, Microsoft put T-NLG up against the previous “monster of the deep,” Nvidia’s MegatronLM, which sports a mere 8.3 billion parameters. According to results published on the blog, T-NLG outperformed MegatronLM across several tests, including WikiText-103, LaMDA, and in head-to-head training.
Microsoft trained T-NLG on a Nvidia DGX-2 systems equipped with v100 GPUs and InfiniBand connections. “Any model with more than 1.3 billion parameters cannot fit into a single GPU (even one with 32GB of memory),” the company says, “so the model itself must be parallelized, or broken into pieces, across multiple GPUs.”

(The ZeRO compiler and the DeepSpeed library can increase model and data paralellism (image source: Microsoft Research)
One of the key pieces of software that enabled Microsoft to simplify the parallelization in T-NLG is DeepSpeed, a new library that it created specifically to reduce the time and expense of large-model training.
“DeepSpeed makes training very large models more efficient with fewer GPUs, and it trains at batch size of 512 with only 256 Nvidia GPUs compared to 1024 Nvidia GPUs needed by using Megatron-LM alone,” the company says.
A critical component of the DeepSpeed library is a memory optimization process called Zero Redundancy Optimizer, or ZeRO. Microsoft says the parallelized optimizer improves the data and model parallelism in distributed deep learning models, which enables users to scale the models like they couldn’t before (potentially up to 100 billion parameters, the company says).
DeepSpeed and ZeRo are compatible with PyTorch, and are being released as open source libraries. For more information, see a blog post on the new software.
Related Items:
Deep Learning Has Hit a Wall, Intel’s Rao Says
Can Thought Vectors Deliver Human-Level Reasoning?
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States