

January 13, 2020
Using a Data Catalog to Support Precision Medicine

(pikepicture/Shutterstock)
In the first story of this series, we made the case for applying common data governance (DG) and tools in organizations to help with the quality and privacy of consumer data. To have the best chances of success, we suggested in a second story that organizations should wage the battle for a single source of reference of their data assets through a governed, global data catalog. This last story will illustrate how a global data catalog implemented at a hospital could support a data scientist team in a precision medicine scenario.
We’ll cover the following topics:
- A brief description of the scenario.
- Assumptions on the existing data landscape and DG efforts at the hospital.
- Project development aspects: governance requirements for new datasets, existing data asset discovery and access, data pipeline development and production governance aspects.
- We conclude with a summary of the thoughts presented in this series.
Scenario Description
This recent study, developed by UK scientists at Cambridge, is the first to combine non-genetic factors (e.g., clinical data, lifestyle) with known genetic ones in a risk prediction model for breast cancer. The model achieves high levels of risk stratification in the general population, enabling much higher levels of personalized decision-making on prevention therapies and screening. It is a great example of the precision medicine approach to diseases like cancer, diabetes and coronary artery disease that may result from the interaction of multiple causal factors.
Genetic Factors
On the genetic front, susceptibility to breast cancer in this model is conferred by:
- Rare, high-penetrance variants in two genes (BRCA1 and BRCA2); and rare, intermediate risk variants in three other major genes.
- Common variants conferring lower risks on some other (minor) 300+ genes, whose risks combine multiplicatively; their joint effect can be represented as a polygenic risk score (PRS).
- A residual genetic component accounting for family history and other unknown genetic effects. Family history is modeled using configurations of 0, 1, 2 or more 1st-degree relatives having breast cancer, with increased family history implying higher risks on both components 2 and 3.
Nongenetic Risk Factors
The nongenetic risk factors (RFs) are modeled as categorical factors with an associated relative risk with respect to a baseline category, at a given age. The study shows it matters to have data from different populations to compute the right risk scores, as incidences significantly vary by country. For concreteness, mammographic density, a nongenetic RF, is modeled as the following table, using UK population distributions and relative risks.
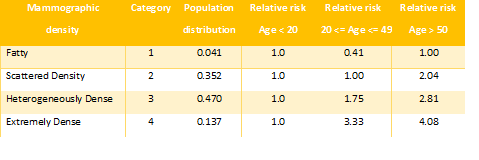
Nongenetic RFs in the model are classified as:
- Anthropomorphic factors: height, body mass index;
- Clinical factors: mammographic density, hormone exposure;
- Personal lifestyle: e.g., alcohol intake; and
- Reproductive factors: age at menarche, at menopause, at first live birth. For space reasons we will henceforth ignore these factors.
Steps to compute the risk score
At a high level, our data scientists must build a pipeline to find, for each patient, the following data:
- Presence or absence of variations in his/her genetic data for each of the major and minor genes.
- For minor gene variations, compute the PRS score summarizing these multiple variation effects.
- Based on age, determine the relative RFs associated with each of the major genes and the polygene, relative to a baseline incidence (the one applicable to no variants on any genes).
- Determine the patient’s number of 1st degree relatives having had breast cancer.
- For each non-genetic RF, find the category to which the patient belongs.
- Determine, for each such nongenetic RF categories, the patient’s relative RFs.
- Use the formula in the model with the data values computed above to calculate the risk score.
Assumptions on Data Landscape and Data Governance
In the scenario above, our data scientists can rely on existing data assets, but need others. We make the following assumptions:
- New datasets:
- Patient genome sequencing data. The hospital has contracted the services of a genomic sequencing provider. Registered patients are asked to take blood samples, and results are made available digitally (e.g., as FASTQ files) a few days afterwards. Privacy policies apply.
- Population RF datasets. These pose no ingestion nor privacy problems, as it’s aggregated data.
- Existing datasets within the organization provide the remaining needed data:
- Patient basic data (birth date, country of origin and residence, anthropomorphic data),
- Patient alcohol intake, and
- Patient clinical data related to breast cancer (family history, mammographic density, hormone exposure data).
- The data landscape consists of two electronic health record (EHR) repositories from formerly independent providers, a data warehouse and a data lake for experimentation.
- Data governance assumptions:
- A DG organization is in place,
- A global data catalog has been implemented: glossary terms, DG policies and terms are defined, and curated datasets from the landscape are classified by both glossary and governance terms,
- Data lineage metadata is in place for patient data,
- Quality statuses are reflected with crowdsourced rating terms.
- The GDPR legislation covers the hospital.
- Security and privacy of patient data was reworked to become GDPR-compliant.
The figure below depicts the landscape just described.

Project Development
Governance Requirements for New Datasets
Genomic data is considered special category data under the GDPR. The DG organization has defined the following policies for such data:
- Privacy: No PII information is to be brought to the data lake (where the project will be developed); encrypt data in transit and at rest; decrypt only during processing. Sensitive data should be pseudonymized. Perform a privacy impact assessment (PIA) as per the GDPR, for each new initiative.
- Collection: automate collection of files from the genomic providers’ site and put provenance lineage data pointing to the provider.
- Consent: if/as needed, as determined by the PIA.
- Retention: dates for archival and deletion are required so these events can be audited.
The data catalog helps during the governance requirements phase as follows.
- The data scientist registers the project’s basic data: its purpose, project duration, patient registration process.
- She describes the genomic datasets needed for each registered patient, and requests to take ownership.
- The DG leader approves the project and points to references within the catalog to the governing data policies described above, which she needs to honor.
- She schedules a kick-off meeting to launch the PIA, decide about governance policies and controls for new datasets, and plan subsequent phases.
Governance Design and Implementation Phase
The PIA’s conclusions and recommendations are:
- There is no need for consent. Subscription to the program is a legal basis for holding the data.
- Alcohol intake is sensitive data that must be pseudonymized and classified for privacy governance (this is a privacy gap; it should have been done before).
- To minimize re-identification risks for registered patients, no official patient IDs (e.g., UK’s NHS identifiers) should be given to the genomic provider. To link data back to the right patient, surrogate identifiers (SPIDs) will be given instead.
Our data scientist looks for basic patient data in the catalog. Several datasets are returned. She verifies that the data warehouse dataset has high quality marks and contains all required data basic elements. Its data lineage shows that its data comes from both EHRs. She decides this will be the anchor to link to genomic data. Once it is copied in the data lake and she is given access, she adds a column to store the surrogates, generates the SPIDs and adds them in.
Arrival of new datasets is handled as follows:
- Genomic files, keyed on SPID, are stripped of PII data and stored in encrypted form.
- Population RF datasets are classified in the catalog, and given read-only access to data scientists.
Data Asset Search and Access
Our data scientist now uses the catalog to bring in the remaining datasets. The sequence of events could be as follows:
- To get alcohol intake data, she looks up the catalog’s glossary for the right term to search. A single dataset is returned, coming from the warehouse, and containing aggregated alcohol intake data with pseudonymized categories, as per the PIA. She inspects its lineage; it comes from a single EHR (say, EHR-1). She searches the source dataset by name and verifies data is not aggregated. As per metadata and catalogued samples, alcohol intake is still in units of alcohol/week, so the PIA recommendation is not implemented in EHR-1 yet. She notes down this EHR-1 alcohol intake dataset name to request access later in a grouped access request.
- She looks for clinical data related to breast cancer using keyword searches, e.g., terms “hormone,” “mammogram.” She identifies three datasets she needs. The datasets have high quality marks and are joinable to the other patient data.
- She requests, through the catalog interface, a grouped access to these four datasets, referencing the project she registered. The Catalog software identifies and contacts the data owners, which know about the project, and approve the request.
- Once alcohol intake pseudonymization is implemented in EHR-1, the encoding table, the EHR-1 alcohol intake and the clinical datasets are made available with read-only access in the data lake.
The figure below illustrates this process for alcohol intake data.

Data Pipeline Development
- Pipelines working on genomic data have to locate the major and minor genes in the file, compare each gene to a reference human genome and determine the types of variants for each. The output is a vector, one entry per gene, with a binary result: presence or absence of a pathogenic variant in a major gene, and presence or absence of a common variant in a minor gene. This analysis can be automated with 3rd party genomic analysis solutions.
- For non-genomic datasets, the tricky parts are mapping patient RF category data to the population RF dataset category. For instance, alcohol/week units of alcohol intake must be mapped to grams/day, as required by its RF dataset.
- The genomic file result vector, keyed on SPID, can be joined with the nongenomic risk results for each patient.
- Patients with missing data (e.g., alcohol intake data from registered EHR-2 patients) are either filtered out, or a process starts to complete their missing data.
- The pipeline delivers a resulting dataset containing one line per patient with the final score and all the data values required for its computation for verification and auditability.
Production Governance Aspects
Once automation of new streams of registered patients is handled, the pipeline is turned into production. The resulting dataset needs to be cataloged, classified, and given a data lineage. Policies and rules in the areas of access control, retention and privacy, determined at governance design phase, need to be applied. Last, genomic files are deleted before their registered deletion date.
Conclusion
In this blog series we have striven to demonstrate that large organizations, which generally have no single source of truth for decision making, must introduce data governance processes to address the challenges of locating trustworthy data and analytic assets to help develop, inform and influence business initiatives –the definition of an organization being data-driven.
This blog has shown that a data catalog is a key technology ingredient in supporting DG, including privacy regulations such as GDPR. We also advocate enterprise-wide DG which, in practice, means finding a way for multiple tools to exchange their metadata. We described Egeria, a promising open metadata exchange standard with which experimentation should be encouraged.
Finally, beyond technology, proper data governance requires specific organizational DG bodies defining rights, accountabilities, policies, and processes. Above all, this body must promote data access, data literacy and support the necessary changes to the organization’s culture, as the shift to becoming data-driven changes the way organizations approach their businesses initiatives and the nature of work related to data and analytics.
About the author: Fernando Velez is a software technologist with an extensive career in data management, in the database systems, analytics and information management domains. After a period as a researcher in France, Fernando built and delivered products to each of these domain markets, in companies such as Doubleclick (now part of Google), Business Objects and SAP. He is currently the Chief Data Technologist at Persistent Systems.
Related Items:
Governing Consumer Data to Improve Quality and Enforce Privacy
Enterprise-Wide Data Governance through Governed Global Catalogs
Applications:
Enterprise Analytics
Technologies:
Middleware
Sectors:
Healthcare
Vendors:
Persistent Systems
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States