

December 4, 2019
AWS Bolsters Redshift, Elasticsearch Services

Amazon Web Services gave customers 28 more reasons to store and process data on its public cloud platform yesterday during its annual re:Invent conference in Las Vegas, Nevada, bringing the total number of services to 180. Among the new stuff unveiled by CEO Andy Jassy are support for exporting data from Redshift into S3 using the Parquet data format, a speedy new AQUA mode for Redshift due in 2020, as well as a cheaper Elasticsearch storage option for petabyte-scale data.
Redshift is a popular cloud-based data warehouse that’s based on the column-oriented analytics database originally developed by ParAccel. Customers typically load Redshift by moving data from their Simple Storage Service (S3) buckets into the data warehouse, which powers traditional business intelligence and analytics workloads that rely on SQL queries.
With the new Data Lake Export function, AWS is allowing customers to unload data from their Redshift cluster and push it back to S3. Data that’s exported from Redshift to S3 is stored in the Apache Parquet format, which is a columnar storage forma that’s optimized for analytics.
Storing the data in Parquet brings several advantages, according to AWS. First, unloading the data with Parquet can be to 2x faster compared to text formats. It also consumes up to 6x fewer storage resources in S3, the company says.
The openness of Parquet is another key advantage. “This enables you to save data transformation and enrichment you have done in Redshift into your S3 data lake in an open format,” writes AWS’s Danilo Poccia in a blog post yesterday. “You can then analyze the data in your data lake with Redshift Spectrum, a feature of Redshift that allows you to query data directly from files on S3. Or you can use different tools such as Amazon Athena, Amazon EMR, or Amazon SageMaker.”
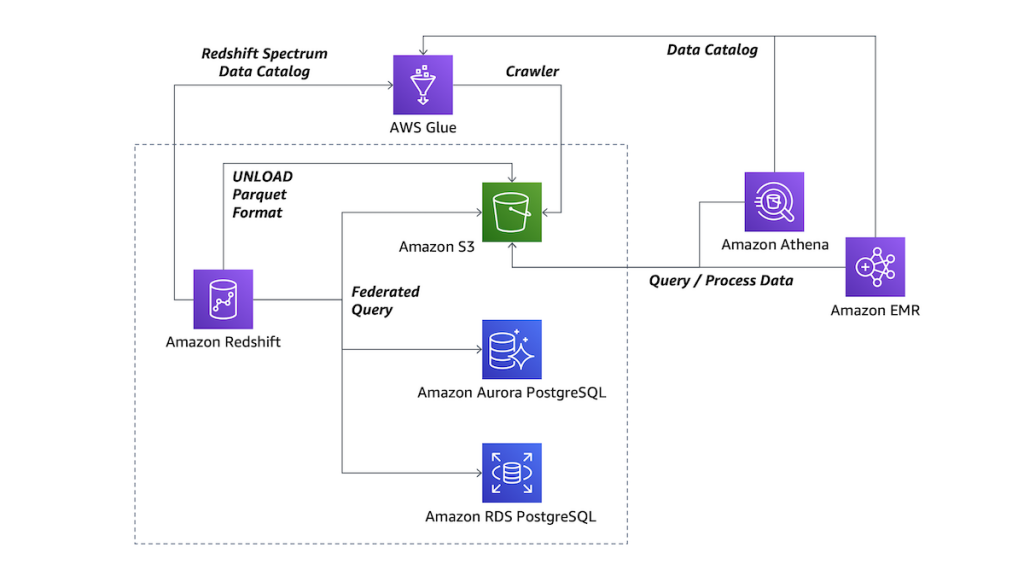
Redshift is getting federated query capabilities (image courtesy AWS)
Once the data is stored in S3, customers can benefit from AWS’s second Redshift announcement: Federated Query. AWS is now enabling customers to push queries from their Redshift cluster down into the S3 data lake, where they are executed. In addition, the Redshift queries can be pushed down to execute in Amazon Relational Database Service (RDS) for PostgreSQL and Amazon Aurora PostgreSQL databases.
Querying the data where it sits, rather than moving it into Redshift using extract, transform, and load (ETL) functions will save customers time, grief, and money, according to Poccia.
“…[Y]ou can access data as soon as it is available,” he writes. “Straight from Redshift, you can now perform queries processing data in your data warehouse, transactional databases, and data lake, without requiring ETL jobs to transfer data to the data warehouse.”
Redshift’s federation story gets even better in mid-2020, when AWS officially rolls out AQUA, an advanced query accelerator for Redshift that Jassy unveiled onstage yesterday.
According to Jassy, AQUA flips the equation of moving the data from storage to compute, and instead moves the compute to the storage. “You can actually do the compute on the raw data without having to move it,” he says.
AQUA is based on the company’s new virtualization platform for EC2, called the Nitro System, that the company has been working on for the last couple of years. Nitro, which stems from the company’s 2015 acquisition of Israeli chip maker Annapurna Labs, is designed to speed up processing by offloading security, networking, and storage from a main server, freeing it to perform tasks faster.

AQUA will increase Redshift processing by 10x and be available in mid-2020, AWS Andy Jassy says
AQUA will accelerate Redshift processing by up to 10x, without increasing costs, by leveraging Nitro to eliminate a lot of the ETL work that is required to move and prepare data for analysis, Jassy says.
“Moving all the data from storage to compute is a lot of muck,” he says, “and so with AQUA you get the double benefit of it being much faster, being able to do the compute on the raw storage, and save the time and energy of not having to do the muck on the data.”
Finally, customers that want to query large amounts of machine data using their Amazon Elasticsearch Service will be happy to hear about the new UltraWarm service that Jassy unveiled yesterday.
Currently in preview, UltraWarm for Amazon Elasticsearch provides a “fully managed, low-cost, warm storage tier” for its Elasticsearch service that can cut 90% of the cost of storing up to 900TB, the company says. Like AQUA, UltraWarm is based on the company’s Nitro chips and virtualization platform.
UltraWarm gives AWS customers an alternative to the hot storage tier, which has been the only Elasticsearch storage option available. The hot tier excels at providing very fast access to the latest data. However, some AWS customers found it too expensive, which led them to restrict the amount of data they were using to perhaps a few months’ worth of data. Now customers can analyze years’ worth of data in Elasticsearch with UltraWarm.
“UltraWarm complements the hot tier to add support for high volumes of older, less-frequently accessed, data to enable you to take advantage of a lower storage cost,” writes AWS’ Steve Roberts in a blog post yesterday. “UltraWarm is a seamless extension to the Amazon Elasticsearch Service experience, enabling you to query and visualize across both hot and UltraWarm data, all from your familiar Kibana interface.”
Customers can analyze up to 3PB of data per Elasticsearch cluster, AWS says. The new service is based on Elasticsearch version 6.8 and also uses Nitro EC2 processing. The service is currently in preview in the US-East and US-West regions.
Related Item:
AWS Launches Cassandra Service
Amazon Uses ML to Transcribe Medical Speech
When – and When Not – to Use Open Source Apache Cassandra, Kafka, Spark and Elasticsearch
Applications:
Data Mining
Vendors:
AWS
Tags:
Andy Jassy, AQUA, AWS, data warehousing, elasticsearch, keynote, machine data, Nitro, Re:Invent, redshift
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States