

October 22, 2019
Enterprise-Wide Data Governance through Governed Global Catalogs

via Shutterstock
In our previous story, we asserted that consumer data, arguably today’s most valuable asset, must be of good quality and be protected by safeguards to comply with privacy regulations. We demonstrated how master data management, or MDM, and data privacy technology can help with those two important aspects in the consumer data landscapes of today’s organizations, and we made the case for applying common data governance processes and tools.
This story will expand on the topic of data governance and cover:
- Why organizations should implement global catalogs on their data landscapes.
- Best practices and how to express governance requirements and controls in a data catalog, and the advantages of such an approach.
- An existing standard for catalog metadata exchange, including its chances of success.
Single Source of Reference through a Governed Global Catalog
Data warehouses were designed to deliver on the promise of single source of truth (SSoT) for analytics development. However, the data that businesses want to analyze today comes in so many types, shapes, volumes and velocities that it is impractical and costly to build such a SSoT.
Today, most enterprise analytic data landscapes are siloed; there are data warehouses and marts, Hadoop data lakes, graph databases, streaming data and MDM repositories. Each analytic silo is optimized for a particular workload and provides some form of governance, typically through a tool-specific catalog.
In this siloed environment, data scientists, developers and power analysts from several business units are tasked with producing business-ready data assets for analysts and end users to consume. Business-readiness means delivering consistent quality, security, privacy and lifecycle policies, i.e., global governance on data sourced across these silos.
To solve this problem, a new architectural blueprint centered on a governed global catalog, dubbed Logical Data Lake (LDL), has emerged (see here and here). Metadata about relevant data assets from the analytical silos are published and made discoverable by developers in this global catalog. Then, the business-ready assets they produce can be discovered by consumers, making this catalog a single source of reference for the entire organization, as shown in the diagram below.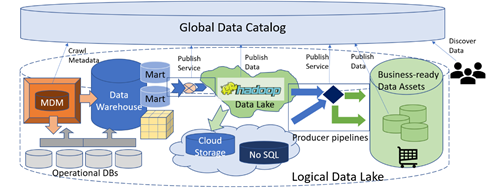
The global catalog is said to be governed:
- When policy, standard and technical control metadata on different areas of governance are linked to the assets it describes; and
- When, thanks to the implementation of these controls, it manages the processing of the various execution engines operating inside the Logical Data Lake, or LDL.
As a result, in LDLs with governed global catalogs, these silos are managed as if they were centralized.
Expressing Governance through Data Classifications
It is a good practice to express policies and standards referring to the organization’s data classifications, a concept first introduced in information security contexts and being extended to other governance areas. These are business metadata terms describing well-defined data asset traits, and are based on the asset’s level of value, criticality and sensitivity. For instance, a patient data asset could be classified as “Highest Quality Tier,” a measurable quality level defined in a quality standard. The same asset could also be classified as “Sensitive Personal Data” in the privacy governance area.
Another type of business metadata are glossary terms which have agreed-upon definitions that give meaning to entire data assets (e.g., “Physician Assistant”), individual data elements (e.g., “Length of Stay”) or groups of data elements or categories (e.g., “Education Data”) when labeling assets with them. Data catalogs typically enable search and delivery of data assets via both glossary and governance classification terms.
Governance technical controls are data processing descriptions that tell how a data asset should comply with the property described by a data classification. So, the control related to “Sensitive Personal Data” tells which patient PII, quasi-identifier data and sensitive data elements to encrypt and/or to pseudonymize, and in which situations. The control associated to “Highest Quality Tier” patient data describes which quality rules apply to this data set and how to use them for measuring quality. Controls may also define terms for data processing actions, such as “encrypt,” “mask,” or “validate address”, and be associated with specific data elements or categories of data assets.
Once implemented with tools and technology, governance also entails certifying that controls work as they should. Chief Privacy Officers and Chief Data Officers are especially interested in the outcome of certification processes since regulations affecting the organization often require evidence of such certifications. Again, searchable terms can be extremely helpful.
Advantages of Enterprise-wide Classification-based Governance
This classification-based approach has the following advantages:
- There is a consistent way of supporting processes from all governance areas and all LDL assets, rather than particular forms of governance around tool-specific catalogs from each analytic silo.
- There is a single place to discover assets with a particular criticality, sensitivity and value properties, as described by the governance classifications. Consumers can verify which assets are indeed business-ready.
- Governance is stable despite new data assets being continually curated. The classification process ensures new assets will find their place in the governance program.
- Access to data for all individuals within the organization can be managed through appropriate governance controls enforcing data protection and auditing for ad hoc data requests and usage.
- In mature implementations, the operational governance behavior can be directly managed from the governance classifications and technical controls described in the catalog, regardless of the execution engines they operate on.
We recommend giving thought to the structure of governance classifications and associated terms for control actions and control certifications in order to support global governance processes. Make sure that these classifications are clear and limited in number so that their meaning and the process of classifying data is understood and can be adopted by all staff members relying on data for their work.
Integrating Metadata from Different Catalogs
For hope for global curation and discovery of data assets in the LDL in the presence of catalogs from different vendors (the most likely scenario in organizations), catalogs should be able to exchange metadata. This is now possible via Egeria. Through synchronization capabilities, a central catalog can be chosen to persist metadata from a group of catalogs and act as SSoR. Alternatively, through federated queries, a single view of all catalog metadata can be obtained in lieu of SSoR. These capabilities are delivered through OMRS, Egeria’s Open Metadata Repository Services, which can run in its own server or embedded within a vendor’s metadata server.
The following illustration shows the integration of three catalogs in Egeria: a Hadoop catalog, a catalog from an ETL tool supplying data to Hadoop from systems of record (importantly, Egeria can catalog pipeline metadata), and the global governance catalog. We show each catalog deploying OMRS, the ETL catalog in its own server and the other two in embedded mode. Here, the global catalog could establish relationships between metadata elements held in the other two, enabling lineage and allowing users to understand and trust their data (or not).
Egeria also addresses point 5 above on automated operational governance by adding governance and access frameworks to host bespoke data movement and security engines, as well as data access APIs. This is a generalization as to what was done between Apache Atlas and Apache Ranger, where security access policies authored in Atlas are automatically enforced by Ranger. Egeria uses classification terms as the basis to express governance. A second Egeria component, Open Metadata Access Services (OMAS), provides specialized APIs, types, classifications, actions, certifications and events for different engines such as ETLs and privacy engines. Through this shared governance metadata, these engines can automate otherwise manual governance workflows through global, coordinated jobs on different governance areas (e.g., see Egeria’s Privacy Pack). Each OMAS retrieves and stores open metadata through Egeria’s OMRS, so it has access to all connected metadata repositories.
Will Egeria Generate Industry Traction?
Today, there are hundreds of metadata standards. Few cover details beyond data asset technical detail and some level of asset labeling, and few have been implemented. Most vendors preferred to use proprietary APIs and formats. Yet proprietary solutions won’t obtain traction and will never cover all governance needs, so open source with a commercially friendly license is the only way forward.
Egeria is open source and has roots in Apache Atlas, which drove standardization across Hadoop vendors. It is backed today by IBM, SAP, SAS, Hortonworks/Cloudera, and ING (a large enterprise). This is a good start. Will it be enough? Two large traditional enterprise data vendors are missing (Oracle and Microsoft), and the three most popular cloud platform vendors, which have recently introduced Data Catalogs (Google, AWS, and Microsoft Azure), are also absent.
In our opinion, Egeria has the right approach and the right ingredients, but it needs the backing of at least one of the major players mentioned to tip the balance and generate momentum.
The next and last blog of this series will illustrate how a data catalog implemented at a healthcare organization could support a data scientist in a precision medicine scenario.
About the author: Fernando Velez is a software technologist with an extensive career in data management, in the database systems, analytics and information management domains. After a period as a researcher in France, Fernando built and delivered products to each of these domain markets, in companies such as Doubleclick (now part of Google), Business Objects and SAP. He is currently the Chief Data Technologist at Persistent Systems.
Related Story:
Governing Consumer Data to Improve Quality and Enforce Privacy
Applications:
Enterprise Analytics
Technologies:
Frameworks
Sectors:
Financial Services
Vendors:
Persistent Systems
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States