

October 9, 2019
HANA in the Cloud by Christmas, SAP Says

SAP formally revealed the planned general availability of hotly anticipated new cloud data storage products during CTO Juergen Mueller’s keynote address at TechEd conference in Barcelona Monday. Two of those new offerings — SAP HANA Cloud and SAP Data Warehouse Cloud, which are bundled under the SAP HANA Cloud Services umbrella — were announced earlier this year and are expected to ship “before Christmas,” Mueller said.
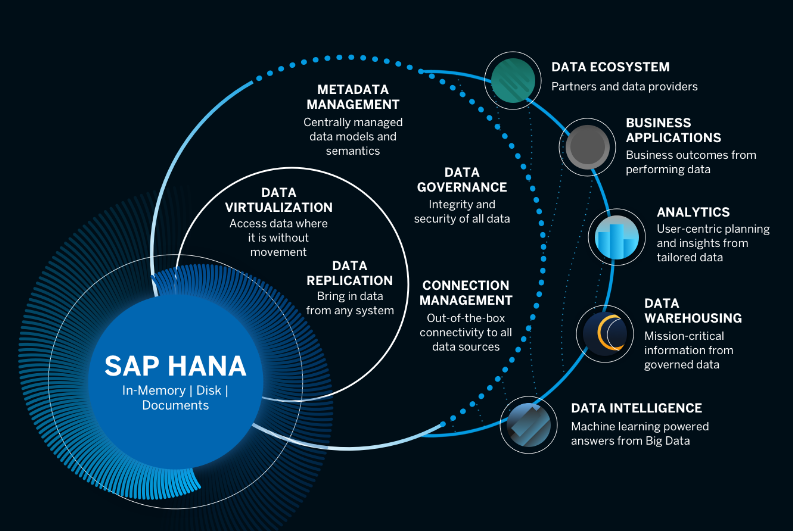
SAP HANA Cloud is a new cloud-native version of the core HANA database that is delivered as a container and can be managed on the SAP Cloud platform using the Kubernetes resource manager. According to Mueller, SAP HANA Cloud gives customers a single place to store data from a variety of sources — for analytics and transaction processing — and manage it in a variety of ways.
“SAP HANA Cloud offers one data access layer for all your data sources,” he said. “It directly connects to your data from your on-premise HANA system, your third-party systems, and even Excel, without the need for data replication in order to work with that data.”
The new cloud offering is a fully managed cloud service, and will “dramatically lower” customers’ total cost of ownership (TCO) for storing and managing petabytes worth of data, Mueller said.
“We have choices for data storage and more options for data federation, so you don’t have to move your data around anymore, so the CFO will be happy,” Mueller said. “You only pay for the memory, disk, and data lake storage that you use — paid by the hour, if you wish.”
SAP HANA Cloud includes a data tiering functions that let customers mix and match their data to different underlying storage mediums supported by HANA. It’s all about meeting the changing data storage and management needs of customers, Mueller said.
HANA isn’t just a database anymore — it’s a brand
“You don’t want to have all your data all the time in main memory. It’s rather expensive, after all,” Mueller said. “What you need is the freedom to assign your data from high-performance, high-cost to low-performance, low-cost storage and back — whatever you want.”
For example, customers could put their newest or most valuable data in HANA’s in-memory repository (the original meaning of “HANA”), and then move it to HANA’s disk storage mode when it becomes lukewarm. When the data cools a bit more, customers can move it to HANA’s relational data lake (see “Data Warehouse Cloud” below), which is more cost-effective. And when it cools even further, they can move it to external data lakes, such as AWS S3, Azure Data Lake, and Google BigQuery — all from within the comfy confines of SAP HANA Cloud.
SAP has done the tough engineering work to separate compute and storage with SAP HANA Cloud. To that end, the new service lets customers scale both compute and storage independently. “That helps you respond to varying database workloads,” Mueller said. “You can create hybrid deployments and mix your on on-prem and cloud setups. On top you get full transparency over where which data resides and how frequently it is [accessed.].”
SAP HANA Cloud can be used to serve analytical and transactional workloads, which is important because SAP is making a big push to get its ERP customers running the latest SAP S/4 HANA suite in the cloud (especially those running the 15-year-old ECC release). But SAP is practical about how much change users of established and highly customized ERP environments are willing to stomach. About 11,500 of SAP’s 45,000 ERP customers have upgraded to SAP S/4 HANA, according to SAP figures, which means there are tens of thousands of customers on aging software.
To that end, SAP is positioning SAP HANA Cloud as a good place to house the new data that ERP customers are collecting, storing, and processing as part of other workloads, including but not limited to analytical workloads. It’s all about providing a “very non-disruptive transition to the cloud,” Mueller said. “Just run additional workloads there, and you don’t have to touch your on-prem system.”
SAP’s Cloud Data Lake
Meanwhile, SAP also unveiled the SAP Data Warehouse Cloud, which is a cloud-based repository that extends the SAP HANA Cloud. The new offering will assist customers with managing data and running analytical workloads, according to Gerrit Kazmaier, SAP’s executive vice president for analytics, databases, and data management.

SAP CTO Juergen Mueller (left) talked with Gerrit Kazmaier, SAP’s executive vice president for analytics, databases, and data management, at TechEd October 8, 2019
“SAP Data Warehouse Cloud is built on SAP HANA Cloud,” Kazmaier said on stage at TechEd in Barcelona, Spain yesterday. “It uses SAP HANA Cloud for virtual data access. It uses its persistency. It uses its data tiering. Most important, of course, it uses its heart — our in-memory engine, HANA — for the cloud and the performance.”
As a relational data lake, SAP Data Warehouse Cloud lets customers store petabytes worth of data without worrying about exceeding capacity limitations, Kazmaier said. If everything goes as planned, the solution will help SAP customers put their out-of-control data analytics projects back on track.
“Our new offering is really about filling the gaps in the data value formula, because so many data projects fail to deliver lasting value,” Kazmaier said. “We all have gigantic data lakes with no usage because they really are data swamps. We have so many self-service BI initiatives that fail to deliver data driven decisions because there is just no confidence in the data, and there are so many machine learning and data science projects which never make it past the demo stage because the models built can’t be integrated into enterprise data flow. And SAP Data Warehouse Cloud deals with all of those issues.”
Intelligent Hubs
Also figuring into the big data mix is another new SAP product, called SAP Data Intelligence, which it unveiled two weeks ago at its TechEd conference in Las Vegas.
SAP Data Intelligence is a managed cloud service designed to help customers control the creation of machine learning models.

Mueller discusses the data value formula
On the data science front, SAP Data Intelligence helps data scientists to manage the development, deployment, and ongoing maintenance of machine learning models. The software features a built-in Jupyter data science notebook, and works with models developed in Python, R, and Tensorflow.
SAP Data Intelligence is complementary to an existing product, called SAP Data Hub. Launched two years ago, SAP Data Hub helps users create reusable data pipelines using connectors for more than 200 sources, which could include structured data from a database, unstructured data from a data lake, or even streaming data. It provides data discovery, data catalog, and metadata management for turning this raw data into reusable assets.
SAP Data Intelligence and SAP Data Hub are critical supporting cast members for organizations that want to do more with their data, but are stymied by all the usual data suspects, according to Kazmaier.
“We recognize it’s less about the actual data science piece,” the EVP told Datanami two weeks ago at the Strata Data Conference in New York. “It’s more about how do I source data? How do I prepare data? And at the end, in what way do I apply machine learning or plug in my model into a governed data flow?”
SAP Data Hub addresses the data pipeline aspect of the big data challenge, while SAP Data Intelligence brings process to sometimes chaotic data science activities.
“We found that, when we looked into real life customers, where they’re struggling the most is they had all these brilliant data scientists available,” Kazmaier said. “That was not the issue. But giving them the right data, and once they had the data, unwinding what they have done to the data to repeat that on an enterprise process — this is where Data Hub and Data Intelligence help to fill the gap.”
Related Items:
Eyeing Expansion, SAP Pushes HANA to the Cloud
Inside SAP’s Data Analytics Startup
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States