

April 16, 2019
Quobyte Plugs TensorFlow Into Scale-Out File System
Quobyte designed its file system with scalability in mind. It also designed it to handle multiple types of files and workload without burdening human administrators with extra complexity. Both of those characteristics are at play with today’s addition of a TensorFlow plug-in for machine learning workloads on the Quobyte Data Center File System.
Quobyte is a scale-out file system developed by Björn Kolbeck and his co-founder, Felix Hupfeld, to address emerging big data storage needs in academia and the enterprise space. After getting their PhDs, Kolbeck and Hupfeld worked at Google, where they witnessed firsthand the power that a software-only approach to scale-out storage can bring.
“It’s an opportunity to do things radically different from the ground up, as we have seen at Google,” Kolbeck says. “This is why we started Quobyte: To bring high performance computing and scale-out technology together into a software product that does storage.”
Quobyte’s distribute file system runs on commodity servers and can be used to store hundreds of petabytes on a mixture of media running on commodity servers connected over a TCP/IP network. The file system speaks multiple protocols, including NFS, HDFS, and S3, and is POSIX compliant, which adds to its flexibility.
The most important characteristic of Quobyte is its linear scalability, Kolbeck says.
“You can start at four nodes. When go from four nodes to eight, you get twice the IOPS, twice the bandwidth, twice the capacity,” he tells Datanami. “The great thing here is there’s no diminishing returns. When you go from 500 to 1,000 servers, you’ll see twice the performance. There are no forklift upgrades. You can start small because you know the beginning system will scale to thousands of servers when you need it.”
Quobyte developed fault tolerance into its system to minimize the administrative burden. While humans will be needed to replace failed disk drives or host bus adapters (HBAs), the file system’s capability to self-heal will allow it to continue chugging along with barely a blip noticeable to the outside world.
“The important part is when you lose 10 servers out of 1,000, there’s nothing that a human needs to do,” Kolbeck says. “It means humans can work on the system when they have time, but they are not crucial component in the storage system anymore, especially when things go wrong, and that’s the key to scalability.”
There are lots of different approaches to storage that can get you into the 10 petabyte range, which is table stakes for AI. “You could say that 10PB is the new small when it comes to machine learning workloads,” Kolbeck says.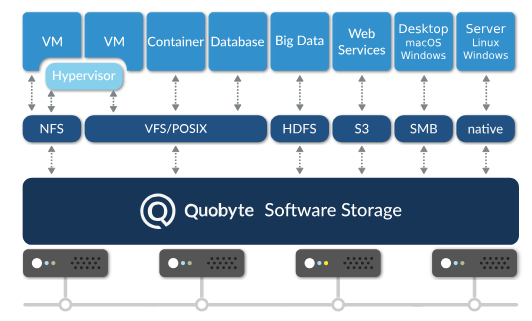
Once you get to the 100 petabyte range, things get a bit more complex. While object storage systems like S3 can offer “cheap and deep” storage, it can’t deliver the performance that machine learning systems need. The Hadoop Distributed File System (HDFS) can deliver better performance, but the complexity starts to become a burden — not to mention the bottleneck caused by the NameNode, Kolbeck says.
Quobyte’s file system has been tested at scale at Science and Technologies Facilities Council (STFC), the UK’s biggest research IT provider, which used Quobyte’s DCFS to feed its supercomputer with 42PB in storage (expected to expand to 300PB by 2022). The largest system in the commercial space is a financial services firm that has a cluster of 170 Quobyte servers. Yahoo Japan has Quobyte running on Kubernetes.
Kolbeck makes the case for Quobyte to be the data lake of the future, thanks to its capability to scale beyond 100 PB, to speak different dialects, and to support different workloads.
“We do cover a broad range of storage workloads. That was done intentionally,” he says. “We believe in one storage infrastructure, instead of silos where you have one storage system per application, because that increases complexity and dramatically drives up the cost.”
Even before today’s introduction of the TensorFlow plug-in, Quobyte had customers who were already running machine learning workloads. We have customer with data scientists who throw all kinds of workloads at us, including machine learning,” he says. “Because we are the right architecture for this, they just run it.”
One of the advantages that Quobyte brings to machine learning, Kolbeck says, is the capability to support the different stages of machine learning. That includes everything from the ingest stage, where the data is pre-processed, to the training phase, where the algorithms spot patterns in the data.
If the data set is big enough — and many ML workloads today are run on datasets measured in the tens of petabytes — then traditional spinning hard drives, will be needed, as opposed to Flash. While Quobyte supports NVMe drives, they’re simply too expensive to feed data to big machine learning workloads.
“Because we have HDDs as a first-class citizen, we can get several gigabytes per second from a single server,” Kolbeck says. “We have customers who get several hundred gigabytes per second from their [whole] installation. So you can do the learning directly on the hard drives without Quobyte, which allows you to do, say, 50PB of hot data on hard drives, which would be too expensive if you did it all on flash.”
The addition of the TensorFlow plug-in just makes training algorithms with that frameworks that much easier, Kolbeck says.
“The TensorFlow plug-in is something we did particularly for machine learning workloads, to make them more efficient by cutting out the kernel and the file system driver and directly linking our driver into TensorFlow,” he says. “The TensorFlow plugin is like another piece in the puzzle to make it more machine learning-friendly.”
Related Items:
The Future of Storage: Software
Amazon S3 Dominance Spawns Storage Challengers
What Can GPFS on Hadoop Do For You?
Applications:
Artificial Intelligence
Technologies:
Middleware
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States