

April 4, 2019
Product Naming with Deep Learning

(Ryzhi/Shutterstock)
We do not usually associate artificial intelligence (AI) with creativity. Generally, AI algorithms are used to automatize repetitive tasks or predict new outcomes based on previously seen examples. The creative process can sometimes be repetitive and tedious, too. So, would artificial intelligence be able to provide inspirational thoughts?
Let’s take a classic creative marketing example: product naming. The moment a product is pushed out onto the market, the most creative minds of the company come together to generate a number of proposals for product names that must sound familiar to the customers and yet are new and fresh too. Of all those candidates, ultimately only some will survive and be adopted as the new product names. Not an easy task!
Now let’s take one of the most creative markets: fashion labels. A company specializing in outdoor wear has a new line of clothes ready for the market. The problem is to generate a sufficiently large number of candidate names for the new line of clothing. Names of mountains were proposed, as many other outdoor fashion labels do. However, names needed to be original to stand out in the market and differentiate from similar competitor products.
Why not use fictive mountain names that are based on real mountain names? On the one hand, they would be different from competitor names, but on the other hand, they would sound familiar to customers. Could an AI model help generate new fictive mountain names that still sound realistic enough and are evocative of adventure?
To help the marketing department, we asked a many-to-many recurrent neural network (RNN) to generate mountain-related new names. We built and trained a many-to-many long short term memory (LSTM) network to generate new name candidates from existing mountain names for the outdoor clothing line.
Recurrent Neural Networks
Recurrent neural networks are a family of neural networks used to process sequential data like text, sensor data, and numerical time series[i]. Recently, they have shown great success in tasks involving machine translation, text analysis, and speech recognition[ii] [iii].
RNNs have the advantage that they generalize across sequences of patterns rather than learn individual patterns. They do this by capturing the sequence dynamics through loop connections and shared parametersi. RNNs are also not constrained to a fixed sequence size and, in theory, can take all previous steps of the sequence into account. This makes them very suitable for analyzing sequential data.
Technically, an RNN can be seen as a chain of multiple copies of the same static network, A, with each copy working on a single time step of the input sequence. The network copies are connected via their hidden state(s). This means that each of the network copies has multiple inputs: the current sequence value x(t) and the hidden state(s) h(t-1) output from the previous copy, which theoretically conveys the information from all previous sequence steps.
A common way of depicting an RNN with a loop connection is shown on the left of Figure 1. The network A (light green box) is a static network with one or multiple hidden layers. The loop connection indicates that the output of network A at one time step t is used as the input for the next time step t+1.
On the right of Figure 1, we see the unrolled graph of the same RNN network. It represents, in an easy to understand way, the loop connection on the left. Note that “a copy of network A” here really also indicates the same weights and not just the same network structure.
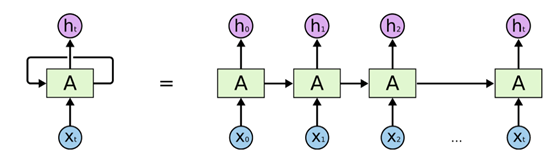
Figure 1. A recurrent neural network (RNN) on the left is a network A with recurring (looping) connections. The same RNN is represented on the right as a series of multiple copies of the same network A acting at different times t.
To train RNNs, we use the generalized backpropagation algorithm, which is called backpropagation through time (BPTT)i.
While RNNs seemed promising to learn the time evolution in time series, they soon revealed their limitations in long memory capability. This is when LSTM sparked the interest of the deep learning community[iv].
Long Short Term Memory Networks
An LSTM network is a special type of RNN. Indeed, LSTM networks follow the same chain-like structure of network copies as RNNs. The only difference is in the structure of the static network A. In addition to the hidden state LSTM units have a second hidden state: the cell state is usually thought of as the representation of the network memory. A particular unit structure, called gate, allows you to remove (forget) or add (remember) information to the cell state in each unit based on the input values and hidden state (see Figure 2).
Each gate is implemented via a sigmoid layer that decides which information to add or delete by outputting values between 0 and 1. By multiplying the gate output pointwise by a state, e.g., the cell state , information is deleted (output of gate = 0) or kept (output of gate = 1).
In Figure 2, we see the network structure of an LSTM unit.

Figure 2. Structure of an LSTM cell (reproduced from [i]). Notice the three gates within the LSTM units. From left to right: the forget gate, the input gate, and the output gate.
The “forget gate layer” at the beginning filters the information to throw away or to keep from the previous cell state based on the values of current input and previous cell’s hidden state h(t-1).
The adding of information is implemented by two layers. A sigmoid “input gate layer” that decides which information to add and a “tanh layer” forcing the output between -1 and 1. The outputs of the two layers are multiplied pointwise and added to the previous, already filtered, cell state C(t-1) to create the new value C(t).
The last gate is the “output gate”. This decides which of the information from the updated cell state C(t) ends up in the hidden state h(t). The hidden state is a filtered version of the cell state C(t). For more details about LSTM units, check the GitHub blog post “Understanding LSTM Networks” (2015) by Christopher Olah.
Many-to-Many RNN and Character Encoding
“Many-to-many” refers to mapping the input and output of the network, meaning a sequence as input and a sequence as output. A sequence here can be a sequence of words, characters, time steps, video frames, etc.
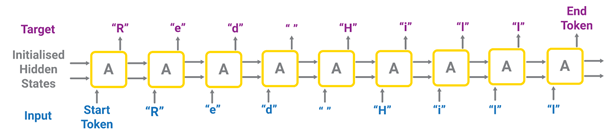
Figure 3. The many-to-many RNN architecture unfolded for one mountain name. First, the network is executed on some zero initialized hidden states and on the start token as input value to predict the first character of the mountain name, here “R.” In the next iteration, “R” and the hidden states of the first network copy are fed into the next copy to predict “e” and so on until the end token is reached and the network stops.
As a training set, we built a list with 33,012 names of mountains in the U.S., as extracted from Wikipedia through a Wikidata query. Mountain names are strings and presented to the network as sequences of characters, one character per “time step.” Each sequence needs a trigger character, named start token, and an end character, named end token. We arbitrarily chose “1” as the start token and “0” as the end token.
Figure 3 shows the unfolded many-to-many architecture for the mountain name “Red Hill.” Thus, the Start Token must predict “R,” then “R” must predict “e,” then “e,” “d” and so on until the End Token is reached.
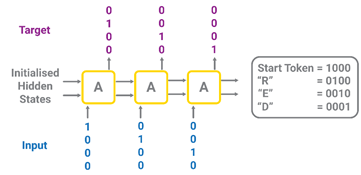
Figure 4. Neural networks operate on numerical vectors/tensors. Therefore, characters are one-hot encoded.
Still, a network doesn’t understand letters as input but operates on numbers. Therefore, all characters must be one-hot encoded, as you can see in Figure 4. By translating the position of the “1” in the one-hot encoding vector, we get a more compact and equivalent index-based encoding.
Training Workflow
In order to read and encode the mountain names and to define, train and execute the many-to-many LSTM network, we used theKeras integration available within KNIME Analytics Platform.
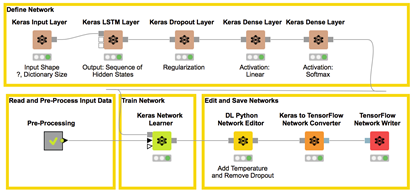
Figure 5. This workflow builds, trains and saves an RNN with an LSTM layer to generate new fictive mountain names. The brown nodes define the network structure. The Keras Network Learner node trains the network using index-encoded original mountain names from the node named “Pre-Processing.” Finally, the trained network is prepared for deployment, transformed into TensorFlow format, and saved to a file.
The workflow that implements the example described in this article is shown in Figure 5. At the top, you can see the brown nodes that build the layers in the RNN structure. Below, from left to right, you can see a grey node that reads, preprocesses and index-encodes the mountain names in the input data, the node implementing the network training algorithm. Finally the last three nodes prepare the network for deployment, transform it to TensorFlow format, and save it to a file.
Defining the Network Structure
The Basic Structure
The network we use has:
- an input layer to feed the one-hot encoded character into the network
- an LSTM layer for the sequence analysis
- two dense layers to extract the probabilities for the output characters from the hidden states
The number of different characters in the training set is 95. Therefore, the size of the input layer is “?, 95.” The “?” stands for a variable input length. The possibility of having a variable length input is indeed one of the biggest advantages of RNNs. The output layer also has 95 units.
Introducing Temperature
We could use only one dense layer with the Softmax activation function. However, to change the confidence of the network after training, we decided to introduce temperature .
Note: Softmax is defined as: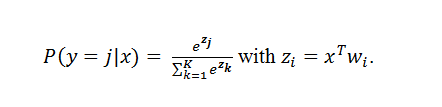
Temperature τ is introduced after the linear part of SoftMax as a dividing factor: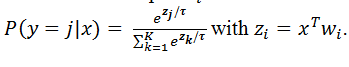
τ < 1 makes the network more confident but also more conservative. This often leads to generating the same fictive names. τ > 1 leads to softer probability distributions over the different characters. This leads to more diversity but, at the same time, also to more mistakes, e.g., character combinations that are uncommon in Englishiv.
Temperature τ = 1,2 is introduced through a Lambda Layer applied in between the linear and the Softmax layer in the trained network via a Python snippet code before deployment. Thus, during training, the linear component of the Softmax must be separated into an additional dense layer. This is obtained with two subsequent dense layers in the network, one with Linear and one with the Softmax activation function.
The final network structure is shown in Figure 6, with one input layer, one LSTM layer, a linear dense layer, and a Softmax dense layer.
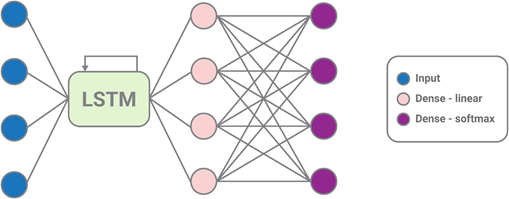
Figure 6. The adopted network structure, with an input layer, an LSTM layer, a linear dense layer, and a Softmax dense layer. The last two layers have been inserted to allow for the introduction of the temperature parameter
The Dropout Layer
The network was trained with an additional drop-out layer to prevent overfitting and to allow for better generalization. Dropout consists in randomly setting a fraction of input units to 0 at each iteration during training time, which helps prevent overfitting. This layer is then removed when the network is deployed.
Preprocessing and Encoding
We now need to prepare the data to feed into the network. This is done in the preprocessing and encoding part of the workflow. Here, mountain names are read and transformed into sequences of characters; characters are encoded as indexes and assembled into collection cells to form the input and target sequences.
The longest mountain name in the training set has 58 characters. Therefore, the input sequence contains the start token plus the mountain name as a sequence of 58 indexes. The target sequence contains the same 58 indexes of the characters forming the mountain name plus a zero in the end. The zero in the end serves as the end token on one hand; on the other hand, it ensures that the input sequence and the output sequence have the same length. For the purpose of training, the sequence length in one batch has to be the same; therefore, we zero pad all those mountain names with less than 58 characters.
The biggest advantage of RNNs is that they can handle sequences of different length. However, for the training, the sequence length in one batch has to be the same. Therefore, we zero pad all mountain names with less than 58 characters.
In the process, a dictionary is also created to map indexes with characters.
The training node of the KNIME Keras integration automatically converts these index-encoded sequences into one-hot encoded sequences as expected by the network (Figure 4).
Training the Network
The Keras Network Learner node then trains the network. In the node configuration window, we set the conversion from a list of integers (the indexes) to a list of one-hot encoded vectors and all the training parameters.
In the last step, we save the trained network. Before we do so, we modify the network structure to remove the dropout layer and to introduce the temperature via a Lambda Layer. For this modification, we use some Python code in the DL Python Network Editor node.
For faster prediction, we convert the network from a Keras model into a TensorFlow model.
The newly converted network structure, TensorFlow formatted, is then saved to a file for further usage in deployment.
The final training workflow is shown in Figure 5
Deployment Workflow
In Figure 7, you see the deployment workflow.
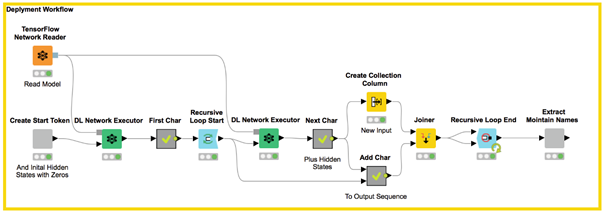
Figure 7. The deployment workflow generates 200 new, fictive mountain names. It reads the previously trained TensorFlow network and predicts 200 sequences of index-encoded characters within a loop. The last node, named Extract Mountain Names, translates the sequence of indexes into characters and visualizes the new fictive mountain names.
It first creates a list of 200 start tokens and the initial hidden states (all 0s). Then it reads the trained network and executes it multiple times to generate new mountain names via the DL Network Executor node, character by character.
For the first character, the network is executed on the start token and the initialized hidden states. The output of the network is a probability distribution for the different index-encoded characters. We can now either choose the index with the highest probability or we pick the output character according to this probability distribution. The deployment workflow uses the second approach, as the first approach would always predict the same name.
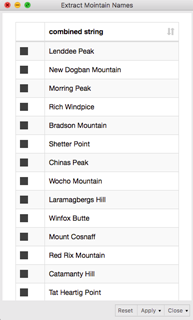
Figure 8. My personal favorites from the output list of fictive mountain names.
To predict the next index, the network is executed again. This time the input is the last predicted index and the hidden states of the last execution. With regards to output, we get the probability distribution for the index-encoded character. And we continue in the same way.
We set the deployment workflow to create N=200 new mountain names. Below, you can see the list of our personal favorites, like Morring Peak or Rich Windplace.
Summary
We have asked AI to help produce a list of fictive mountain names to label the new line of outdoor clothing ready for the market. We produced 200 mountain name candidates to help marketing in the brainstorming phase. These 200 names are just candidates to provide inspiration for the final names of the new products. Human marketers can then select the newest and most adventure-evocative, yet familiar, names to label the new line.
A valid help in putting together a number of name candidates came from an RNN and, specifically, an LSTM network many-to-many network. We trained the network in Figure 6 on 33,016 names of existing mountains, all represented as sequences of index-encoded characters.
Next, we deployed the network to generate 200 new fictive mountain names. One of the good aspects of this project is that it can automate the repetitive part of the creative process for as many fictive mountain names as we want. Once trained, the network could generate any number from 10 to even 5,000 candidate names for our outdoor clothing line.
As future work, you could try to find out automatically which of these names are the most realistic. You could train a second network to separate the real mountain names from the fictive ones. The fictive mountain names that the network wrongly classifies as real are the closest to real names.
You can download the workflow for free from the KNIME EXAMPLES Server under 04_Analytics/14_Deep_Learning/02_Keras/10_Generate_Product_Names_With_LSTM. By changing the real names in the data set, you can train the network to get new inspirational names for whatever you need!
About the authors:
Rosaria Silipo, Ph.D., principal data scientist at KNIME, is the author of 50+ technical publications, including her most recent book “Practicing Data Science: A Collection of Case Studies”. She holds a doctorate degree in bio-engineering and has spent most of her professional life working on data science projects for companies in a broad range of fields, including IoT, customer intelligence, the financial industry, and cybersecurity. Follow Rosaria on Twitter, LinkedIn and the KNIME blog. For more information on KNIME, please visit www.knime.com.
Kathrin Melcher is a data scientist at KNIME. She holds a master degree in mathematics from the University of Konstanz, Germany. She enjoys teaching and applying her knowledge to data science, machine learning and algorithms. Follow Kathrin on LinkedIn and the KNIME blog.
Related Items:
Movie Recommendations with Spark Collaborative Filtering
The ‘Big Bang’ of Data Science and ML Tools
[i] Ian Goodfellow, Yoshua Bengio and Aaron Courville, “Deep Learning”, The MIT Press, 2016
[ii] Jason Brownlee, “Crash Course in Recurrent Neural Networks for Deep Learning”, Machine Learning Mastery Blog
[iii] Zachary C. Lipton, John Berkowitz, Charles Elkan, “A Critical Review of Recurrent Neural Networks for Sequence Learning”, arXiv:1506.00019v4 [cs.LG], 2015
[iv] Andrej Karpathy, “The Unreasonable Effectiveness of Recurrent Neural Networks”, Andrej Karpathy blog, 2015
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States