

April 4, 2019
Intel Builds Analytics, Database Use Cases for Optane

Intel offered a list of use cases for its Optane DC persistent memory technology during a company event this week, including Twitter’s effort to scale its Hadoop clusters using Optane and SAP HANA’s database improvements focused on applications like machine learning and predictive analytics.
The chip maker (NASDAQ: INTC) highlighted those and other datacenter implementations to bolster its assertion that persistent memory is a game-changer. “We’re going to break through memory economics bottlenecks,” said Navin Shenoy, general manager of Intel’s Data Center Group. Noting that DRAM currently accounts for up to 60 percent of total system cost, Shenoy added: “Optane is going to change the economics of memory.”
Optane is promoted as addressing two major shortfalls in the era of big data: volatile memory’s inability to retain stored data when power is lost and NAND’s failure to keep pace with “data-centric” analytics applications.
Optane addresses those stumbling blocks with brute force along with clever software and firmware designs, most notably, a 512-Gb memory module that is up to four times larger than current DRAM capacity.
For early adopters like SAP (NYSE: SAP), the practical effect of the transition to persistent memory technology is new HANA database capabilities centered on improved performance, disaster recovery and consolidation of multiple database systems into a single platform.
Dirk Basenach, SAP’s database chief, said the rollout of persistent memory technology on the company’s flagship HANA database has so far yielded reductions in data loading times from 50 to 4 minutes on a 6-terabyte S/4 HANA system. The database vendor also said the memory technology has helped it achieve 9.1 billion records on a single HANA database.
SAP expects to expand the use of Optane persistent memory in an upcoming release of the HANA data hub, Basenach said.
For its part, Twitter (NYSE: TWTR) relies heavily on Hadoop clusters to store posts, “Likes” and retweets. “Hadoop is an important part of storing all those events and performing analytics on that data,” said Matt Singer, Twitter’s senior staff hardware engineer.
A typical Hadoop cluster used by Twitter includes more than 100,000 hard-disk drives, translating into about 100 petabytes of storage in a cluster.
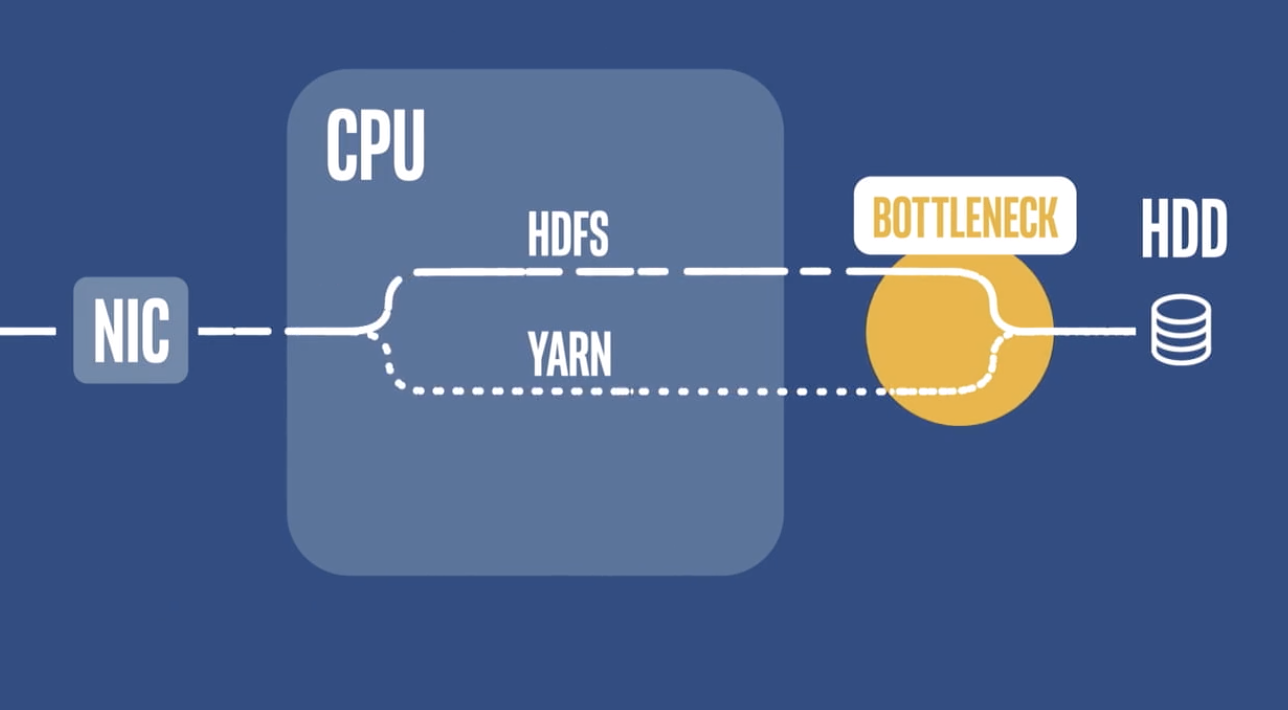
Affordable hard drives have become the “work horses” of Twitter’s Hadoop clusters, Singer noted. “Hard-drive capacity has increased over time, but their I/O [per second] has remained essentially flat, and that has resulted in a storage bottleneck.”
Hence, Twitter leveraged persistent memory and data caching to overcome the bottleneck caused by simultaneous HDFS and YARN data flows “contending” for access to hard drives on a Hadoop server.
Source: Twitter
The solution was selective caching of YARN temporary data via “smart” caching software integrated with an Intel “fast” SSD to eliminate competition for CPU resources
“So hard-drive utilization dropped, and Hadoop could process data faster,” Singer said.
“Removing that storage I/O bottleneck enables us to greatly reduce the number of racks in our [Hadoop] cluster, which gives us a much smaller datacenter,” he continued. Twitter’s Hadoop cluster shrunk from 12 smaller to eight larger hard-drives without impacting performance. Removing the hard-drive performance bottleneck also meant Twitter could leverage CPU horsepower, upgrading from four to 24 Intel second-generation Intel Xeon Scalable cores.
The size of the Hadoop cluster was reduced, resulting in a much smaller datacenter, 75 percent less energy usage and 50-percent faster run times, Singer added.
Intel also this week announced an Optane-based datacenter SSD with dual-port capability targeting enterprise storage along with an EDSFF (Enterprise and Datacenter SSD Form Factor)-compliant QLC NAND SSD with 1 petabyte of storage in a “ruler” form factor.
That, the chip maker claimed, would yield a 20-fold storage rack consolidation versus hard drives.
Recent items:
Aerospike Adds Optane Persistent Memory
Redis Speeds Towards a Multi-Model Future
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States