

March 19, 2019
Nvidia Sees Green in Data Science Workloads

We already knew that GPUs are useful for lots of things besides making Fortnite uncomfortably realistic. All the biggest supercomputers in the world use GPUs to accelerate math, and more recently they’ve been used to power deep neural networks in public clouds. But judging from Nvidia’s GPU Technology Conference being held this week in San Jose, Nvidia sees GPUs and the entire GPU ecosystem as fertile ground for growing a much broader range of data science activities.
During a marathon keynote yesterday, Nvidia CEO Jensen Huang outlined, in strokes both broad and fine, the full Nvidia product strategy. From rendering farms and autonomous cars to medical imaging and cloud-scale analytics, Huang showcased the impressively full gamut of industries and solutions that the company is building and targeting with its GPU-enabled solutions.
Huang devoted almost an hour of his two-hour-and-forty-five minute keynote to the field of data science — and in particular Nvidia’s growing role in empowering data scientists to build the next generation of machine learning and AI systems.
“Data science is the fastest growing field of computer science today,” Huang told an audience of about 6,000 GTC attendees at the San Jose State University Event Center (the San Jose McEnery Convention Center’s halls were considered too cramped for the event this year). “It’s the most sought-after job. It’s the most over-subscribed, course, whether it’s Berkeley or Stanford or CMU or NYU.”
Data science is so popular, Huang says, because it’s become the fourth pillar of the scientific method, allowing scientists to extract insights directly from data in ways that weren’t possible with theoretical, experimental, or simulation. “We’re solving problems that were just previously impossible,” he said.
Organizations of all stripes are looking to data science to unlock insights contained in massive sets of data. They are hiring data scientists at a rapid clip to mine huge stockpiles of data in the hopes of finding a competitive edge. As the data grows, so too do the computational requirements for mining that data, and that’s where Nvidia comes in.
“Data science is the new HPC challenge,” Huang said. “HPC uses computers, very large computers, to solve very difficult problems. Because the data is so large, because the compute necessary is so great, this is the new HPC challenge.”
Framing the Data
Data science hasn’t historically been a huge focus of Nvidia’s, but it’s clear — not just from Huang’s keynote but from the launch of the new data science server and workstations that the company announced at the show — that Nvidia views the discipline as a major driver for its GPU business going forward.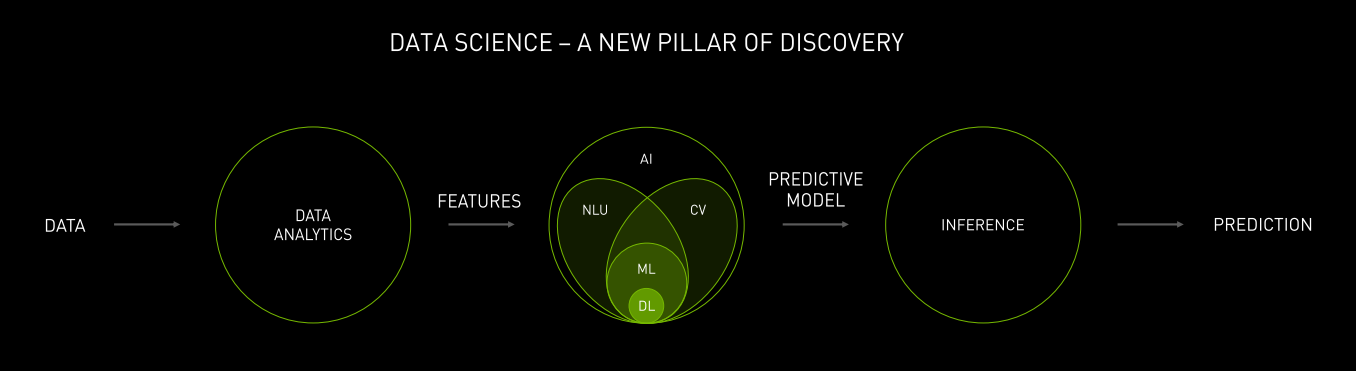
To frame the data processing challenges around data science, Huang described a common data science workflow. It was a good description, and so it’s worth repeating here.
The data science process starts, Huang says, with raw data landing in a data lake. There it’s joined with other data sets to create a data frame, a type of tabular data format that contains the individual identifier (in columns) and the value (in rows) that form the core pieces of information that the data scientist will model.
“You take all of this data in, do all of this munging and wrangling, and what comes out is a gigantic table,” Huang explained. “That gigantic table can be anything from a gigabyte large to a terabyte large. Can you imagine a spreadsheet that’s a terabyte large? First of all, you can’t load it in a normal computer. Not to mention, what do you do with it at all?”
After the data is sufficiently wrangled, the data scientist is left with engineered features that can be used for predictive analytics, he said. “From that, you run it through frameworks and those frameworks ultimately give you a model — a predictive model,” Huang said. “That predictive model, once verified, allows you to predict the next outcome from other instances [of new data]…We call that prediction process inference.”
Data Science & GPUs
GPUs have been commonly used with deep learning, but they haven’t been as widely used for traditional machine learning approaches. In the future, Huang sees GPUs becoming one of the primary computational powerplants for all types of machine learning workloads.
Nvidia is taking several actions to bolster this GPU future. First, it’s making the CUDA library applicable across the stack, which is the reasoning behind the CUDA-X announcement, which makes any CUDA coding run anywhere else, no matter if it was developed for the world’s biggest supercomputer workloads, for a modest machine learning use case, or even a tiny robot operating on the edge.
It’s also pushing its RAPIDS initiative, which is an open source suite of data processing and machine learning libraries that enables GPU acceleration for data science workloads. In his remarks, Huang positioned RAPIDS as the next platform to run big data and data science workloads, which began with Apache Hadoop and continued with Apache Spark.
“It turns out that building a great chip is a nice beginning,” Huang said. “But it’s useless until the world’s developers and users can take advantage of it. That’s why it’s so important for us to work with an ecosystem. Nvidia is an open platform company. We create all these libraries in a way so that it’s software-defined and integrateable into modern system.”
Lastly, Nvidia unveiled a new workstation and a new server dedicated to data science workloads. The new systems are loaded with much of the software required for data scientists to develop and test their predictive models.
“This type of workstation for data scientists is really complicated to build,” Huang said. “We’re basically taking what otherwise is a HPC data center IT tool and turning it into one box.”
Related Items:
RAPIDS Momentum Builds with Workstation Support
At GTC: Nvidia Expands Scope of Its AI and Data Center Ecosystem (EnterpriseAI)
Applications:
Artificial Intelligence
Vendors:
NVIDIA
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States