

January 14, 2019
From Oscar to AI: Mining Visual Assets for Fun and Profit

(Navidim/Shutterstock)
Before big data burst upon the scene, Dan Wexler dealt with it every day at DreamWorks Studios, where he helped developed the rendering tools used on “Shrek” and other films. After winning an Academy Award for his work with 3D graphics, Wexler founded Zorroa, where he’s creating new ways to turn video and imagery data into useful knowledge.
Wexler shared an Oscar for Scientific and Technical Achievement in 2013 with two other colleagues at DreamWorks, Drew Olbrich and Lawrence Kesteloot. The trio was instrumental in DreamWorks’ success in building core lighting and rendering tools behind a string of successful animated movies. It also introduced him to some of the challenges in working with large, unwieldly data sets.
“That was a place where we were kind of causing the problem that we’re trying to solve here at Zorroa,” Wexler tells Datanami. “We created tons and tons of imagery back before we knew to call it big data. We had a whole bunch of fun with 3D graphics as that was growing, and now we’re trying to solve that problem here at Zorroa using the newest cool technologies, like machine learning and AI.”
After DreamWorks, Wexler moved on to NVidia, where he spent more than eight years developing new chip architectures and algorithms for GPU-based film rendering. That gig also prepared Wexler well for Zorroa, where he’s working with machine learning software and distributed systems again.
But instead of generating imagery that titillates the senses, Wexler has reversed course, and is using high technology to break down unstructured image data into something that’s useful for a different audience.
Big Unstructured Data
The story of big data’s explosion is really about the growth of a single type of data: unstructured data.
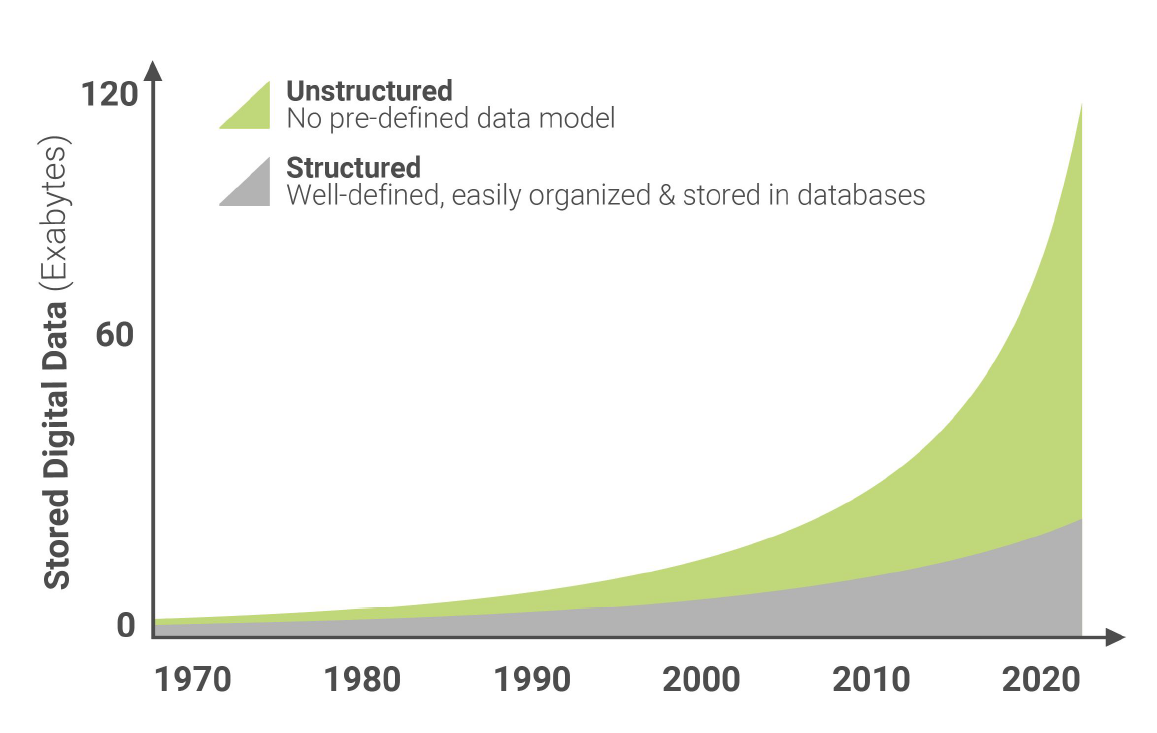
(Source: Harvard Business Review, by way of Zorroa)
Unstructured data, such as videos, images, and Word and PDF documents, largely lives outside of structured databases, which can make it tough to corral. Instead of using SQL or a NoSQL query language to interrogate it, unstructured data can’t be directly queried. To get value out of unstructured data, one typically has to run it through some type of machine learning algorithm.
That’s essentially what Wexler is doing at Zorroa, which he co-founded in 2014 with Beth Loughney, the company’s executive chair. Instead of building the imagery used in animated films, Zorroa’s software excels at picking that imagery apart and transforming it into text, which can then be indexed and analyzed using more traditional tools.
“Zorroa has defined a new category we call visual intelligence, which is a way of managing enterprise assets, such as documents, images, and videos, using these amazing new tech like machine learning,” says Wexler, who is Zorroa’s CEO. “That allows us to dig inside visual data and transform it into the kinds of data that enables the use of all the BI and big data tools that companies have been using recently to grow to that next level of effectiveness.”
Unstructured data accounts for 70% of all data being generated at the moment, by some estimates, with video being called the biggest data source of all. But from the perspective of traditional BI tools like PowerBI and Tableau, that data is largely “dark data” that can’t be tapped for useful decision-making, according to Wexler.
“It’s essentially like they’re mining gold out of a large pile of ore,” he says. “They really don’t know what’s in their data at all. They don’t know how to access that. What we try to do is make it possible for them to understand the value they already have in their company and transform it into revenue.
Open Platform
Zorroa, which is based in Oakland, California, has taken an open approach to building its offering, which it calls Zorroa Visual Intelligence, or ZVI. The platform can run on customers’ existing on-prem compute and storage clusters or in the Google or AWS cloud. In most cases, the data is so big (millions of items spanning tens of petabytes of data) that it can’t be moved, so ZVI installs in a Docker container on the same cluster.
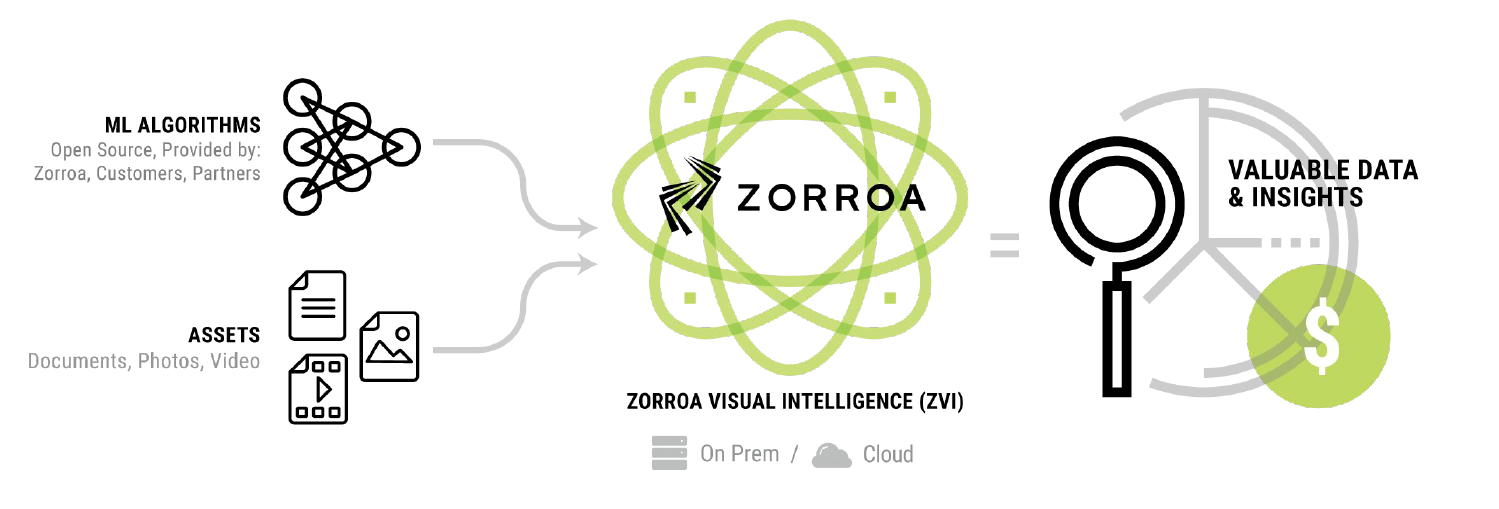
ZVI runs on-prem or in the cloud
As for machine learning algorithms, it can use any open source tooling available, according to Wexler. “We can leverage any tool that’s out there, essentially, with a very configurable pipeline,” he says. “We combine multiple different machine learning and AI algorithms together to try and answer real business problems for our customers.”
The input into ZVI could be a movie with a sound track, or core samples of a potential mine stored in paper documents that have been scanned into a digital format. The images are run through the computer vision algorithm or medley of algorithms, and the results are indexed in an Elasticsearch database, where decision-makers can query the data through a protected API.
“We have a strong visual interface client that allows them to slice and dice that repository of data, and we build BI dashboards that look for those patterns across all the assets we indexed there,” Wexler says. Alternatively, the indexed data can be dumped into other systems, such as Excel or Tableau.
A ‘Digital Backlot’
Customers can user ZVI to explore their data assets in search of new insights, or to ask pointed questions.
ZVI can be used to create a ‘digital backlot’ (Image source: Zorroa)
For example, one common use of ZVI among movie studios is to use it as a “digital backlot” where film executives can quickly pull up scenes from movies that match certain parameters.
“We can use that entire collection across an entire studio, from all the films that they work on, and make it intuitive and easy for the content creators and the directors and production designers to find the assets they want to use in a new film by looking through the archives of assets that they used before,” he says.
For example, if a soda company requested an image of a particular actor sitting in a Lamborghini on a Sunday near a shopping mall for the purpose of building an advertisement, ZVI could pull that information up in a matter of seconds.
“It knows the brand of cars that are in there. It knows the actors by facial recognition. It knows the settings and so forth of where it’s taking place,” Wexler says. “Right now, to do that they have several people working for a day or two to look through that while collection and find an appropriate asset.”
The company has received $9.2 million in angle and seed financing, and is backed by Google’s Gradient Ventures, which invested $7 million last summer. The company worked with Google to index 8 million videos on YouTube; you can read more about that in a blog post on the company’s website.
Zorroa has a handful of early customer success stories in the entertainment, energy exploration, and financial services industries. With those early wins under its belt, it’s now open to exploring solutions for customers in other industries too.
Related Items:
Google Launches Video Analytics Challenge
Analyzing Video, the Biggest Data of Them All
Unstructured Video Data Creating IT Challenge as Volume Explodes
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States