

November 2, 2018
Movie Recommendations with Spark Collaborative Filtering

Collaborative filtering (CF)[1] based on the alternating least squares (ALS) technique[2] is another algorithm used to generate recommendations. It produces automatic predictions (filtering) about the interests of a user by collecting preferences from many other users (collaborating). The underlying assumption of the collaborative filtering approach is that if a person A has the same opinion as a person B on an issue, A is more likely to have B’s opinion on a different issue than a randomly chosen person. This algorithm gained a lot of traction in the data science community after it was used by the team winner of the Netflix Prize.
The CF algorithm has also been implemented in Spark MLlib[3] with the aim to address fast execution on very large datasets. KNIME Analytics Platform with its Big Data Extensions offers it in the Spark Collaborative Filtering node. We will use it here to recommend movies to a new user within a KNIME implementation of the collaborative filtering solution provided in the Infofarm blog post[4].
What You Need to Get Started
- A general dataset with movie ratings by users
For this use case, we used the large (20M) MovieLens dataset. This dataset contains a number of different files all related to movies and movie ratings. Here we will use files ratings.csv and movies.csv.
The dataset in file ratings.csv contains 20 million movie ratings by circa 130,000 users, and it is organized as:
movieID, userID, rating, timestamp
Each row contains the rating to each movie, identified by movieID, by one of the users, identified by userID.
The dataset in file movies.csv contains circa 27,000 movies, organized as:
movieID, title, genre
Movie preferences of current user
The idea of the ALS algorithm is to find other users in the training set with preferences similar to the current selected user. Recommendations for the current user are then created based on the preferences of such similar profiles. This means that we need a profile for the current user to match the profiles of other existing users in the training set.
Let’s suppose that you are the current user, with assigned userID=9999. Likely, the MovieLens dataset has no data about your own movie preferences. Thus, in order to issue some movie recommendations, we would first build your movie preference profile. We will start the workflow by asking you to rate 20 movies, randomly extracted from the movie list in the movies.csv file. Ratings range between 0 and 5 (0–horrible movie; 5–fantastic movie). You can use rating -1 if you have not seen the proposed movie. Movies with rating -1 will be removed from your preference list, while movies with other ratings will become training set material.
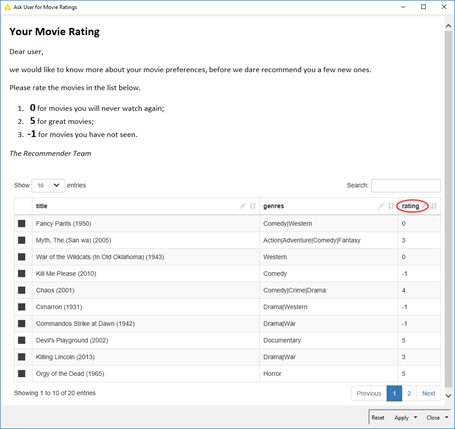
Figure 1. Interviewing the current user (userID =9999) about his/her own movie ratings. We need this information to match the current user’s profile with profiles of other users available in the training set. Preferences from similar users might provide movie recommendations for our current user.
The web page below is the result of a “Text Output” node and a “Table Editor (JavaScript)” node inside a wrapped metanode executed on a KNIME WebPortal. Your rating can be manually inserted in the last column to the right.
A Spark Context
The CF-ALS algorithm is available in KNIME Analytics Platform via the Spark Collaborative Filtering Learner node. This node belongs in the platform’s Big Data Extension for Apache Spark. This extension needs to be installed on the platform to continue with the implementation of this use case.
The node executes within a Spark context, which means that you also need a big data environment available. This requirement can sometimes be a show stopper due to the complexity and potential cost of installing a big data environment either on premises or on the cloud, especially if the project is just a proof of concept. Installation on the cloud might also carry additional unforeseeable costs.

Figure 2. The new node “Create Local Big Data Environment” available in KNIME Analytics Platform 3.6. creates a local simple instance of Spark, Hive and HDFS. While it may not provide the desired scalability and performance, it is useful for prototyping and offline development.
The “Create Local Big Data Environment” node has no input port since it needs no input data, and it produces three output objects:
- A red database port to connect to a local Hive instance
- A light blue HDFS connection port to access the local file system via HDFS
- A gray Spark port to connect to a local Spark context
By default, the local Spark, Hive and HDFS instances will be disposed of when the Spark context is destroyed or when KNIME Analytics Platform closes. In this case, even if the workflow has been saved with the “executed” status, intermediate results of the Spark nodes will be lost.
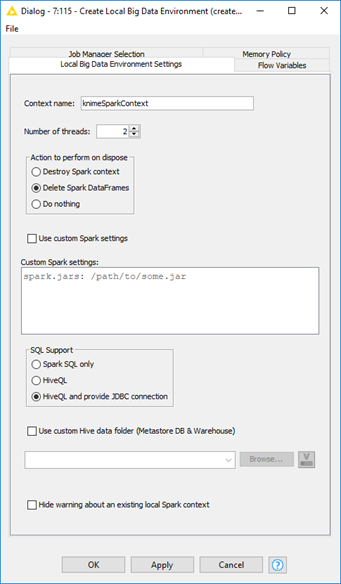
The configuration window of the “Create Local Big Data Environment” node includes a frame with options related to the “on dispose” action, which is triggered when the workflow is closed:
- “Destroy Spark Context” will destroy the Spark context and all allocated resources; this is the most destructive, however cleanest, option.
- “Delete Spark DataFrames” deletes the intermediate results of the Spark nodes in the workflow but keeps the Spark context open to be reused.
- “Do nothing” keeps both Spark DataFrames and context alive. If you save the already executed workflow and reopen it later, you can still access the intermediate results of the Spark nodes within. This is the most conservative option but also keeps space and memory busy on the execution machine.
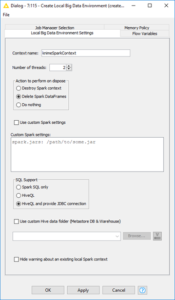
Figure 3. Configuration window of node “Create Local Big Data Environment.” Settings involve: actions to perform “on dispose,” custom Spark settings, SQL support, Hive custom folder, and warning options.
Option number 2 is set as default, as a compromise between resource consumption and reuse.
The Workflow to Build the Recommendation Engine with Collaborative Filtering
In this workflow, we use the Spark MLlib implementation of the collaborative filtering algorithm, in which users and products are described by a small set of latent factors. These latent factors can then be used to predict the missing entries in the dataset. Spark MLlib uses the alternating least squares algorithm for the matrix factorization to learn the latent factors.
Note. It is necessary that movie preferences of the current user are part of the training set. This is the reason why we ask the current user to rate 20 random movies in order to get a sample of his/her preferences.
The collaborative filtering technique is implemented and trained in the Spark Collaborative Filtering Learner node, which runs on a Spark cluster. The node receives at the input port a number of records with product, user and corresponding rating. At the output port, it produces the recommendation model and the predicted ratings for all input data rows, including user and object.
Note. The matrix factorization model output by the node contains references to the Spark DataFrames/RDDs used in execution, and thus it is not self-contained. The referenced Spark DataFrames/RDDs are deleted, like for any other Spark nodes, when the node is reset or the workflow is closed. Therefore, the model cannot be reused in another context in another workflow.
The original movie rating data set was split into a training set and a test set. The training set was used to build the recommendations with a Spark Collaborative Filtering Learner node and the test set to evaluate their quality with a generic “Spark Predictor” node followed by a “Spark Numeric Scorer” node.
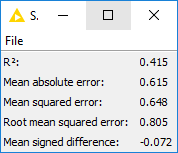
Figure 4. Numerical error metrics calculated on the original movie ratings and the predicted movie ratings with a Spark Numeric Scorer node.
Like the KNIME native “Numeric Scorer” node, the “Spark Numeric Scorer” node calculates a number of numeric error metrics between the original values — in this case the ratings — and the predicted values. Ratings range between 0 and 5, as number of stars assigned by a user to a movie. Predicted ratings try to predict the original ratings between 0 and 5.
The error metrics on the test set show a mean absolute error of 0.6 and a root mean squared error of 0.8. Basically, predicted ratings might deviate from the original ratings +/- 0.6, which is close enough for our recommendation purpose.
Deployment
We previously asked the current user to rate 20 randomly chosen movies. These ratings were added to the training set. Using a generic Spark Predictor node, we now estimate the ratings of our current user (ID=9999) on all remaining unrated movies. Movies are then sorted by predicted ratings, and the top 10 are recommended to the current user on a web page via the KNIME WebPortal.
Since I volunteered to be the current user for this experiment, based on my ratings on the 20 randomly selected movies, I got back a list of 10 recommended movies shown below. I haven’t seen most of them, however, some of them I do know and appreciate. I will now add “watching recommended movies” to my list of things to do for the next month.
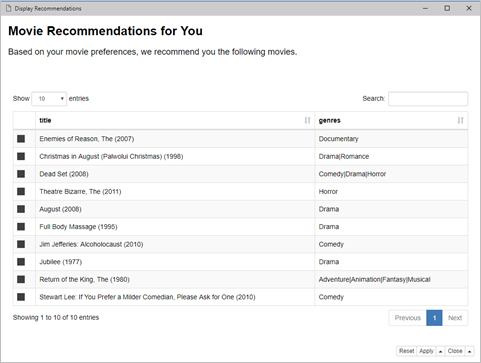
Figure 5. Final list of top 10 recommended movies based on my earlier ratings of 20 randomly selected movies
Note. Please notice that this is one of the rare cases where training and deployment are included into the same workflow.
Indeed, the collaborative filtering model produced by the “Spark Collaborative Filtering Learner” node is not self-contained but depends on the Spark DataFrame/RDDs used during training execution and, therefore, cannot be reused later in a separate deployment workflow.
The collaborative filtering algorithm is not computationally heavy and does not take long to execute. So, including the training phase into the deployment workflow does not noticeably hinder the recommendation performance.
However, if recommendation performance is indeed a problem, the workflow could be partially executed on the KNIME Analytics Platform or KNIME Server till the collaborative filtering model is created, and then the rest of the workflow is executed on demand for each existing user in the training set.
The final workflow is available on KNIME EXAMPLES server under: EXAMPLES/10_Big_Data/02_Spark_Executor/10_Recommendation_Engine_w_Spark_Collaborative_Filtering
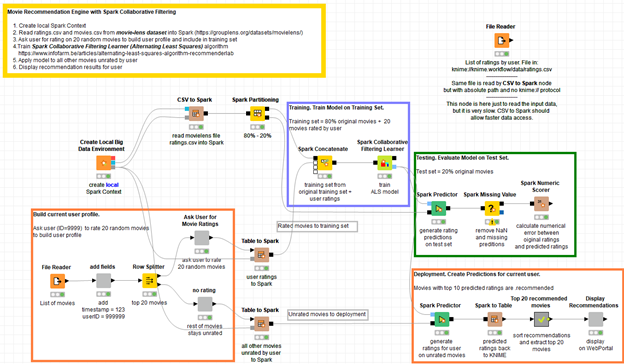
Figure 6. Workflow
EXAMPLES/10_Big_Data/02_Spark_Executor/10_Recommendation_Engine_w_Spark_Collaborative_Filtering first asks the current user to rate 20 randomly selected movies via web browser, and with this data, trains a collaborative filtering model, evaluates the model performance via a number of numeric error metrics, and finally proposes the list of the top 10 recommended movies based on the previously collected ratings.
This recommendations engine case study will be featured in the forthcoming book “Practicing Data Science: A Collection of Case Studies” to premier at the KNIME Fall Summit in Austin, Texas, Nov. 6-9, 2018.
About the author: Rosaria Silipo, Ph.D., is a principal data scientist at KNIME and the author of 13 technical publications, including the forthcoming book “Practicing Data Science: A Collection of Case Studies” to premier at the KNIME Fall Summit in Austin, Texas, Nov. 6-9, 2018. Rosaria holds a doctorate degree in bio-engineering and has spent most of her professional life working on data science projects for companies in a broad range of fields, including IoT, customer intelligence, the financial industry, and cybersecurity. Follow Rosaria on Twitter, LinkedIn and the KNIME blog. For more information on KNIME, please visit www.knime.com.
[1] “Collaborative Filtering”, Wikipedia https://en.wikipedia.org/wiki/Collaborative_filtering
[2] Y. Koren, R. Bell, C. Volinsky, “Matrix Factorization Techniques for Recommender Systems“, in Computer Journal, Volume 42 Issue 8, August 2009, Pages 30-37 https://dl.acm.org/citation.cfm?id=1608614
[3] “Collaborative Filtering. RDD based API” The Spark MLlib implementation http://spark.apache.org/docs/latest/mllib-collaborative-filtering.html
[4] “The Alternating Least Square Algorithm in RecommenderLab” Infofarm blog post by Bregt Verreet Sep 16 2016 https://www.infofarm.be/articles/alternating-least-squares-algorithm-recommenderlab
based on the alternating least squares (ALS) technique[2] is another algorithm used to generate recommendations. It produces automatic predictions (filtering) about the interests of a user by collecting preferences from many other users (collaborating). Read more…" share_counter=""]Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States