

September 28, 2018
Redis Speeds Towards a Multi-Model Future
Redis is best known as a key-value store – a very fast, in-memory key-value store. But the folks developing the technology at Redis Labs have big plans to grow the NoSQL database’s repertoire, and along with it the capability to solve more of its customers’ tough data challenges, while hopefully retaining Redis’ simplicity.
Redis traces its roots back to 2009, when Italian developer Salvatore Sanfilippo released the first version of the key-value database, which was written in C and originally dubbed Remote Dictionary Server (or RE-dis). The svelte product (version 2.2 had only 20,000 lines of code) was eventually picked up by Web companies, like Twitter, that needed a fast and an accurate way to keep counts of things, such as for leaderboards.
Thanks to its reputation for an extreme sort of speed, Redis found its ways into other layers of the stack where fast response time was critical to success, such as with session cache and message queues. Its capability to work with individual data elements, instead of requiring an entire page to be reloaded in memory, helps minimize overhead and contributed to response times measured in fractions of milliseconds. Redis has owned the number one position on DB-Engines key value store category for years, and is currently the eighth most popular database overall.
The year after creating Redis, Sanfilippo (aka “antirez”) was hired by VMware, where he continued to lead development of the open source product. In 2013, Pivotal Software, a VMware spin-off, became the main sponsor of the data store, which continued to grow in popularity. The company that would become Redis Labs was formed in 2011 as Garantia Data under CEO Ofer Bengal. Sanfilippo, who initially was reluctant to work at a Redis company, joined the company in 2015 as its open source development leader.
The company has sought to find a balance between the competing demands of maintaining a vibrant open source software project on the one hand, and building and selling enterprise software on the other.
“What happened was there was a lot of new demand on Redis,” said Kyle Davis, Redis Labs’ technical marketing manager. “We said no to a lot of things. [We wanted] to keep Redis nice and compact and slim. And finally we said, why don’t we give them what they want?”
The result has been the development of a slew of new modules, developed both by the community and by Redis Labs employees, that expand upon Redis and effectively have turned it into a multi-model database. “It really has unlocked really great things,” Davis told Datanami at the recent Strata Data Conference.
One of Redis’ strongest attributes is its capability to store not just as strings, but abstract data types, including lists and sets of strings, hash tables, geospatial coordinates, and even probabilistic data structures. This flexibility, combined with the relative simplicity of the product, are important to Redis’ multi-model journey.
Following the decision to open Redis to outside development, its contributors quickly developed additional extensions that could leverage these diverse data types, including a JSON document store, full-text search engine, an Apache Spark connector, the HyperLogLog module, and support for geospatial data. Some of these are core features of the database, while others are external libraries.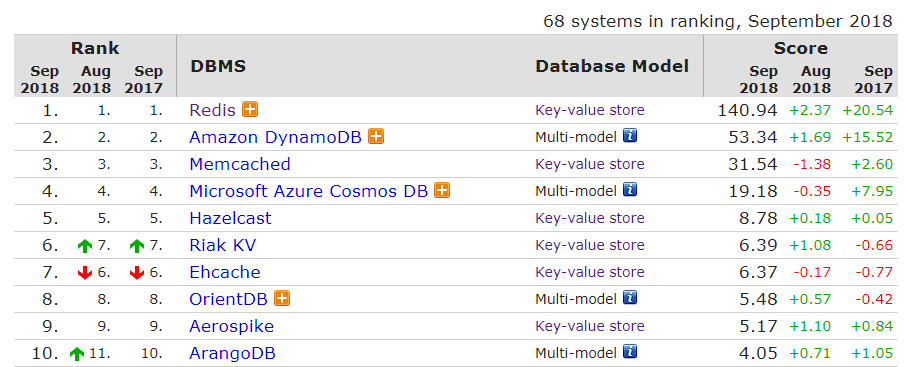
One of the newest modules to emerge from Redis Labs turns the key value store into a graph database. The module, called RedisGraph, will be based on the GraphBLAS technology that emerged out of academia and industry. What’s unique about GraphBLAS is that it expresses graph problems as linear algebra using a data structure called an adjacency matrix, according to Davis.
“We’re positioned very well because we’re the only database that can flip a 0 to a 1 with very little overhead,” Davis said. “So we can take these binary matrixes, store them in memory, do operations on top of them, and get results back many times faster than any other solution on the market.”
According to Davis, the graphs that RedisGraph will hold won’t be massive, but they will offer very fast response times for common types of graph queries, such as detecting fraud. The RedisGraph, which will use the Cypher query language that was developed and open sourced by graph database pioneer Neo4j, could also be used to track down the source of illness in the supply chain, such as with the 2006 E Coli outbreak linked to bad spinach.
“At this point it’s been done in big batches,” Davis said of the so-called “spinach problem.” “We could potentially be in a situation where this can be done in real time so we can catch contamination as it happens rather than after the fact.”![]()
The company has other cool ideas in the pipeline, including a time-series module that could be used to deliver insights on changing data over time. And who knows what is brewing in the hearts and minds of the enormous Redis community at this instant? The trick for Redis Labs will be taking that open source excitement and turning it into paying customers. The company claims that it just surpassed 1 billion downloads of open source Redis on Docker, exceeding other NoSQL databases and NoSQL-based products like MongoDB, Apache Cassandra, and ElasticSearch.
The business model for Redis Labs is a little different than other commercial open source product companies. Any Redis user can get any add-on modules for free, but they’re restricted to running on a single node. If a Redis user finds they need the module to span multiple nodes, they must purchase a license for Redis Enterprise.
So far, the business model seems to be working, as it reports that it has 8,500 paying customers, including an impressive logo sheet that includes the likes of Home Depot, American Express, TD Bank, and Kohl’s. As is typical with most privately held companies, Redis refuses to provide revenue figures.
For now, the company is concentrating on growing, including its cloud business, which is where most customers run Redis. The company currently has 250 employees, with about 100 at the Mountain View, California headquarters and 100 at the Israel office. The company has received $86 million in several rounds of venture capital funding, according to Crunchbase.
Asked which companies Redis Labs is emulating, Davis punted and went another direction. “We’re modeling ourselves on ourselves. I don’t have a crystal ball. I can’t comment on where the business will be in two years, but we continue to grow from a revenues standing, from an employee standpoint, from a capability standpoint,” he said. “We’re at heart a database company.”
Related Items:
Redis Connector Aims to Boost Spark Performance
Redis Labs Gains VC Funding, New Enterprise Customers
Redis Labs Emerges to Push Hosted NoSQL Business
Editor’s note: This article was corrected. Redis Labs started as the independent company Garantia Data in 2011, not as a VMware spin-off in 2014. Also HyperLogLog, the geospatial function, and the Spark connector are not modules of Redis. Datanami regrets the errors.
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States