

September 17, 2018
Improving Your Odds with Data Science Hiring

(ProStockStudio/Shutterstock)
If you’re in the market to hire a data scientist, good luck. Demand continues to outpace supply thanks to the unique abilities of data scientists and businesses’ desire to be data-driven. But you can increase the odds of success by keeping certain things in mind as you scour the land for unicorns.
Six years ago, Tom Davenport and DJ Patil kicked off a hiring frenzy for data scientists by declaring data scientist “the sexiest job of the 21st century” in a Harvard Business Review article. That got the attention of corporations, universities, and out-of-work statisticians alike, and the frenzy to hire data scientists has not calmed down since.
In fact, demand for data scientists has grown. According to the August jobs report by LinkedIn, there were 150,000 fewer data scientists than needed to fill open jobs in that profession. Demand is “off the charts,” the Microsoft subsidiary declared. The scarcity of data scientists relative to job openings has driven up salaries to astronomical levels in some places, such as the Silicon Valley and New York. According to Glassdoor, the average total pay for a senior data scientist is nearly $150,000 per year.
The best way to get a big pay hike is to change jobs, which is easy for data scientists. According to the Data Scientist Report 2018 by Figure Eight (formerly CrowdFlower), half of working data scientists get new job offers at least once a week, and 30% of them report getting several offers. Eighty-five percent get a job offer at least once a month.
Despite the abundance of job opportunities for data scientists, finding the right ones can be a challenge. One person who’s currently on the hunt for data scientists is Paul Dulany, the vice president of data science for CA Technologies, which utilizes predictive techniques to improve alerting in its system monitoring tools. Dulany oversees a team of 10 data scientists and three software engineers who are dedicated to CA’s data science activities.
There are certain minimum requirements that Dulany looks for to be considered for a position on his team. Some of the requirements are set in stone, such as having a firm grasp of mathematics and statistics, while others are more subjective.
“Starting of with someone with a very strong degree, whether it’s in data science or some other area, is key,” Dulany says. “That’s a lot of what’s going to ensure that people understand vector calculus, they understand the partial differential equations that are behind a lot of this stuff.”
But just having a Master’s or doctorate in mathematics or a hard science isn’t enough to earn a spot on his team. Dulany also looks for intangibles that aren’t well quantified, such as the ability to present well and the ability to learn quickly.
“What we look for isn’t exactly what’s taught in the schools yet, in the data science programs or any of the other programs,” Dulany tells Datanami. “Part of what we look for is people with very strong background, both computationally and analytically, and people who have an aptitude to learn the things that they’re going to need to learn when they get here.”
Dulany admits that finding those types of people is challenging. “It is difficult to find those people,” he says. “They are very rare.” But since they’re also the ones that can have the biggest impact on CA’s data science team, Dulany does his best to figure out which of his prospects will fit the best.
 “We’re looking for people who can really understand the domain of AI. That’s critical to what we do,” he says. “But just knowing that is not sufficient. You have to learn the domain of the business that you’re trying to solve the problem for. You also want to find somebody who can learn new domains form a business perceptive relatively quickly and be able to grasp and understand the unique data of each domain, of each problem of each domain.”
“We’re looking for people who can really understand the domain of AI. That’s critical to what we do,” he says. “But just knowing that is not sufficient. You have to learn the domain of the business that you’re trying to solve the problem for. You also want to find somebody who can learn new domains form a business perceptive relatively quickly and be able to grasp and understand the unique data of each domain, of each problem of each domain.”
Dulany received his PhD in theoretical physics, a field that requires working with models and abstract ideas. Physicists have long been sought after as “quants” by Wall Street hedge funds, and now they’re being snapped up by software companies, too. But those with academic degrees in other fields aren’t excluded. In fact, CA has somebody from the oceanography field on its data science team, Dulany says.
That diversity of background contributes to a diversity of thought when tackling data science problems. “Many of us all understand the same mathematics, if you will, but have different intuitions about it and different models within our own heads about what those mathematics mean,” Dulany says. “And bringing different perspectives on data, on process, on different ways to approach the problem, can be extremely helpful. Data science at its best is not done by an individual, but by people collaborating together.”
In the classic Venn diagram for data scientists, domain knowledge can sometimes be the trickiest to obtain, especially for folks coming out of university programs who have strong skills in math and computer science. But Seth DeLand, a product marketing manager at MathWorks, says most of the folks who use the MATLAB data science package are engineers and scientists who have a strong grasp of the business domain, and need to round out their skills with machine learning knowledge.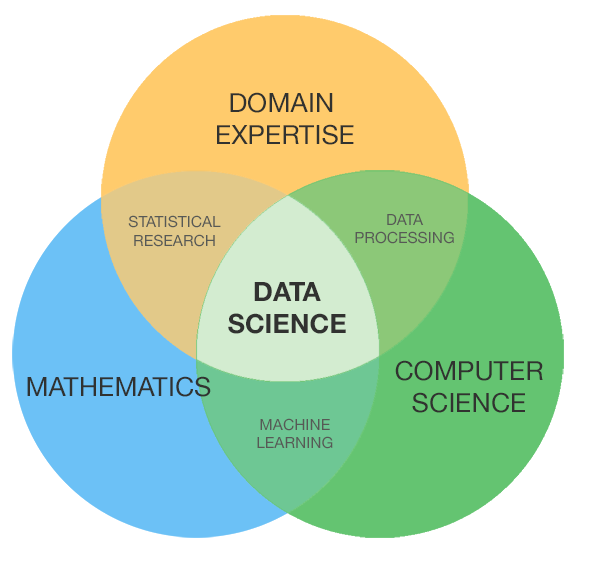
“They already have pretty good math, statistics, and programming knowledge, or traditional data analytics or numerical computation,” DeLand tells Datanami. “That’s something those engineers and science groups have been doing for some time. I would say that enabling the existing engineers to do data science resonates well, because those people are already quite a ways there. They need to learn machine learning and some of the techniques associated with that, and that’s really what we’ve been focused on: lowering the bar for machine learning.”
The MATLAB package is well-regarded in product engineering circles, and is widely used in companies that build jet engines, self-driving cars, and medical devices. Much of the recent focus of MathWorks has been putting guard rails into the MATLAB product to help engineers and scientist ramp up with some of the latest data science techniques, such as use of neural networks.
“When you get to training the machine learning models themselves, there’s definitely some ramp-up that needs to be done,” DeLand says. “I think a lot of the learning curve we see people going through is a lot of trial and error, and a lot of understanding what kinds of machine learning model are going to be appropriate for the type of problem I’m trying to solve.”
Not every machine learning algorithm is appropriate for every use case, and it’s the data scientists’ job to match the best algorithm to the task at hand. For example, somebody who’s new to machine learning might not know that a K-nearest neighbor is probably a bad choice for an embedded systems, DeLand says, because K-nearest neighbor needs to have all the training data to make a prediction.
“Your chances of being able to put all of your training data on an embedded system is slim to none,” he says. “So there’s definitely education about what are the various types of machine learning models, what are their characteristics, what types of parameters to tweak while you’re training them. We’ve been trying to come up with educational resources to help people ramp up in that space.”
Whichever direction you come at the data science game – from academia or from industry – there are well-trod paths. For some, getting access to real-world data and real-world problems is the key to data science success, while for others, learning the basics of machine learning is the best route.
No matter how you arrive, one thing remains the same: abundant job opportunities.
Related Items:
Engineers Vs. Scientists: Who to Hire in Data Now?
Five Ways to Unshackle Data Science from IT Now
Empowering Citizen Data Science
Applications:
Data Mining
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States