

August 22, 2018
Popping Big Data Fallacies On the Edge

(Risto Viita/Shutterstock)
Organizations today are drowning in data. There’s no argument about that. But there continues to be vigorous debate on the best way to deal with that data. While some advocate creating big data lakes to store data that will subsequently be used for training machine learning models, there’s a growing chorus of voices calling for a simpler and more real-time approach.
You can count Simon Crosby, CTO of SWIM.ai, among proponents for a lighter-weight and less expensive approach to data collection and analysis, at least for a certain class of real-world machine learning problems at the edge. During a recent conversation with Datanami, Crosby threw cold water on the notion that uploading data to the cloud for storage and machine learning was the best way to get value out of the morasses of data created on edge devices.
“There is this kind of fiction out there advanced by Microsoft, Google, and Amazon that everybody is going to get data scientists and build some sort of machine learning model and push it to the edge,” Crosby says. “It’s just nonsense. It’s just not going to happen.”
The former Citrix Systems CTO is a firm believer in an alternative model that’s based on incremental learning and a stateful recording of the world. Instead of sending huge amounts of data to the cloud and incurring the overhead of database I/O and GPU training time – not to mention a hefty telecom bill or a data scientist’s salary– Crosby makes a good argument that most of the value can be wrought from sensor data close to where it was created and in real time.
“SWIM.AI’s approach to this is we learn on data on the fly,” he says. “It just needs to be exposed to a large amount of streaming data and we self-train using very compact models at the edge, and deliver insights at the edge.”
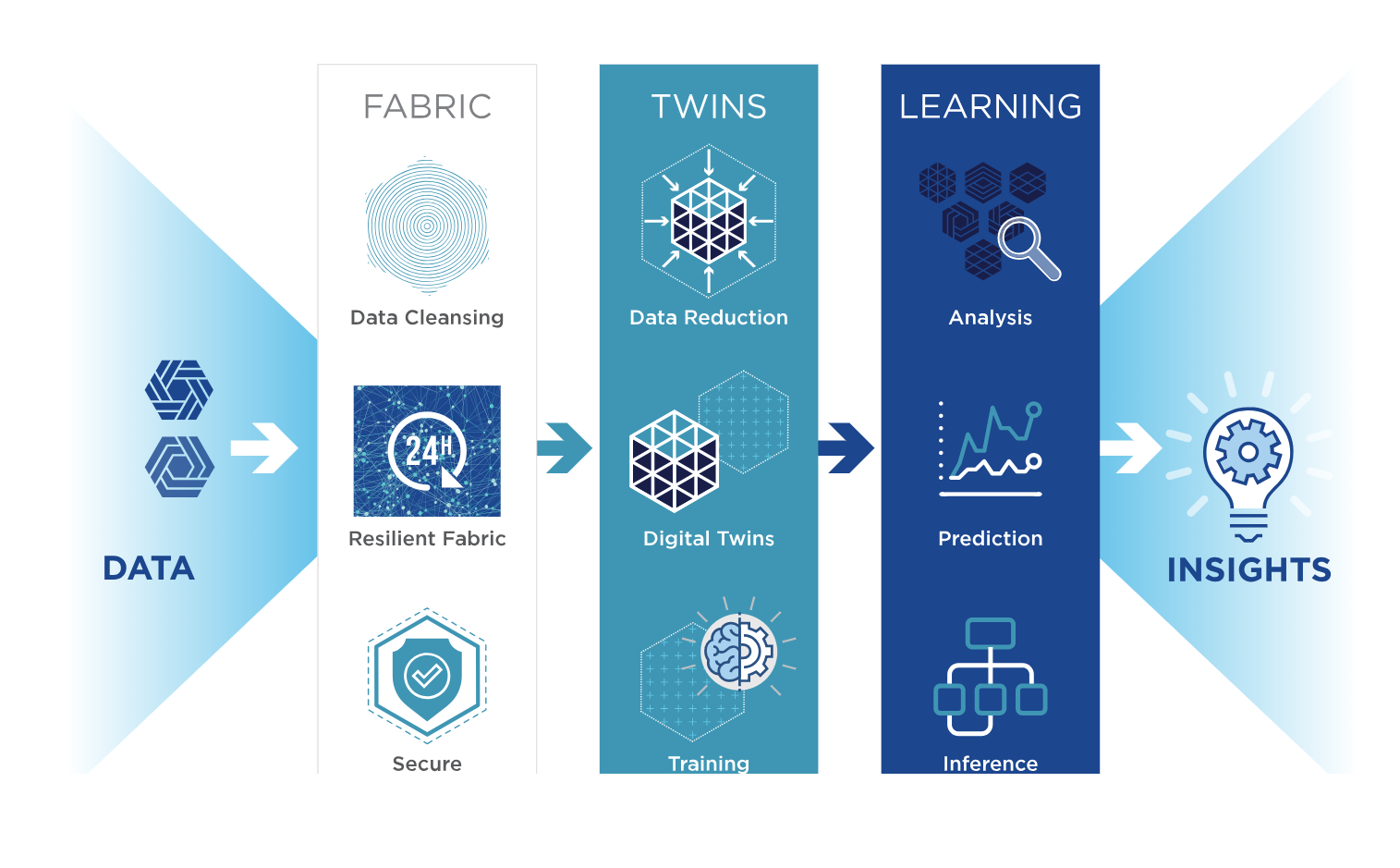
SWIM.ai generates insights on the edge using incremental learning
The company’s SWIM EDX runs on low-power edge devices, such as Arm CPUs, Raspberry Pis, and Nvidia Jetson TX2s. Instead of uploading sensor data to cloud data repositories or other centralized data lakes in order to train machine learning models, the SWIM.AI EDX offering uses a small neural network to do training onsite, via a “digital twin” that’s maintained in a few dozen MB of memory.
“There’s a vibrant field of learning called incremental learning where, if a data source has certain statistical properties, then you learn continually,” Crosby explains. “The difference between how the real world turns out and your guess is your error. You back propagate your error through the network.”
The lightweight approach doesn’t work for all types of data or machine learning workloads. For instance, many natural language processing problems would require you to maintain a large corpus of data for training. If you want to create predictions for people’s behavior, it’s best to have a large database that describes the behavior of people over time.
But for many edge use cases that involve time-series data — such as understanding traffic patterns in a city or predicting equipment failures in the field — incremental learning can be a big time- and money-saver for those suffering under the weight of big data, Crosby says.
Crosby uses the City of Palo Alto’s traffic light network – an actual SWIM.ai customer that generates 4TB of traffic data per day from thousands of sensors – to demonstrate the math behind a cloud-based data processing model and the SWIM.AI approach that processes the data in a city data center.
“If I take all the data from a city and bring it up to Amazon and use Lambda to try to learn on it, essentially what happens is this: Every second, every sensor in that infrastructure is giving me an update, and I have to go and hit the cloud, which is going to read the previous state of this thing out of a database, and write the new state. End to end, for every update, is several hundred milliseconds,” he says.

Nvidia’s Jetson TX1
“Meanwhile, on the edge using just some generic Arm processor — we’re funded by Arm so let’s just make it an Arm CPU — I’m running on a nanosecond timescale. I’ve already got close to a billion free CPU cycles just form the idle time that it would have taken to [run the Lambda calls] on the cloud. So we can scavenge billions of free CPU cycles at the edge. If I wanted to use an Nvida Jetson TX2, a 64-bit Arm processor and a small GPU, that $200 board solves me the entire edge learning problem for several cities, versus about $5,000 a month for AWS” in Lambda calls alone.
The three-year-old startup has provided similar economic benefits to an aircraft component manufacturer that was struggling to read all the RFID tags in real time. The company maintains 2,000 RFID readers recording 500 reads per second in a manufacturing plant that’s a mile long, and they were “paying Oracle through the teeth for logging all these reads,” Crosby says.
Instead of logging all the RFID reads into the relational database, the SWIM.ai solution utilized a series of digital twins running on two Raspberry Pi devices that maintained the state of all the components attached to the RFID tags. “Suddenly this customer has gone from dying of tag reads going into the database, which they have to process later, to being able to watch wheel sub-assemblies come together in real time and predict when they’re going to be done.”
![]() As the speed and density of edge computing devices goes up, the need to shunt data into the cloud for after-the-fact analysis will decline, Crosby predicts. That’s not true for every use case, but there a strong argument can be made for utilizing a more intelligent technique for edge cases on the Internet of Things (IoT).
As the speed and density of edge computing devices goes up, the need to shunt data into the cloud for after-the-fact analysis will decline, Crosby predicts. That’s not true for every use case, but there a strong argument can be made for utilizing a more intelligent technique for edge cases on the Internet of Things (IoT).
“Why are we storing all this stuff?” Crosby asks. “Because 10 years ago, Cloudera came out of Google and said, ‘People, you need to store all your data.’ Other than that, we wouldn’t be doing it. It’s just not necessary.”
SWIM.ai was founded by Rusty Cumpston and Chris Sachs in 2015. The San Jose, California-based company has received $11 million in funding, including an investment by Arm in a $10-million Series B round that closed last month.
Related Items:
It’s Sink or Swim in the IoT’s Ocean of Bigger Data
Why Data Scientists Should Consider Adding ‘IoT Expert’ to Their List of Skills
Collecting and Managing IoT Data for Analytics
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States