

August 3, 2018
The Future of Storage: Software

(Timofeev Vladimir/Shutterstock)
In the previous story in this series, we looked at innovations occurring in storage hardware. Now it’s time to turn our attention to what’s going on in storage software, where innovation continues to push the boundaries of what is possible.
While there are interesting developments around hardware – in particular how storage-class memory technologies are blurring the lines between memory and storage – much of the progress occurring in data management these days is occurring on the software front.
For instance, the advent of the Hadoop Distributed File System in the mid-2000s helped Yahoo lash run-of-the-mill X86 servers into a single cluster capable of storing and processing petabytes of data – something that was only possible on supercomputers at the time.
Hardware advancements may eventually make some of the software storage techniques obsolete. For example, some see databases going the way of the Dodo bird thanks to enhancements in storage class memory. But for now, software is largely responsible for the magic that lets us turn the trillions of bits and bytes stored on magnetic disks or silicon transistors into something useful and insightful.
Let’s dive into the various ways software is used in the management of data, starting with the most basic techniques:

IBM’s Storwize V7000 provides file-level NAS storage
File Storage – File-level storage offers the simplest and least-expensive software abstraction for data storage. It’s used primarily with direct-attached storage devices and Network Attached Storage (NAS) topologies. In file-level storage, the file system manages the creation of files and folders, and the applications access the data through those hierarchical paths.
Local file systems such as SMB/CIFS (for Windows), NFS (for Linux), or HDFS (for distributed scale-out systems) are examples of file storage. Management of file-level storage is typically handled by the storage device or NAS for user access control and permissions. While access is easy, performance may not be as good as with block storage.
Block Storage – Block-level storage involves writing data to disk in fixed sized blocks of bits and bytes, and offers a higher-level of abstraction than file-level storage, as well as potentially higher performance. It’s often used in dedicated storage area network (SAN) arrays that connect to servers via Fibre Channel or iSCSI connections. Requesting applications think they’re accessing their own local disk, even if that disk is located far away.
Block storage is a highly versatile and performant foundation for other data storage abstractions, like database management systems or even other file systems. However, block storage has higher management requirements than file storage, and latency increases degrade performance for non-local access.
Object Storage – Moving up the stack, object storage provides a higher level of abstraction for data storage. Object stores like Amazon‘s S3, Scality‘s RING, and DDN‘s WOS store data as individual objects, along with a collection of metadata for each object and a unique identifier for retrieving it.
Object stores have scalability advantages, and have traditionally been favored for big data sets (in excess of a petabyte) and for storing unstructured data, such as pictures or movies. Applications retrieve data from object stores via APIs, defined by REST or SOAP. Cloud-based object stores have recently started to function as data lakes, stealing some thunder from Hadoop.

Relational database schemas provide a blueprint for organizing how companies store data
Databases – Databases provide an even higher level of abstraction than file-, block-, and object storage mechanisms, and continue to be the workhorses for real-world applications. Row-oriented relational databases like Oracle that power transactional workloads rose to popularity in the 1980s, while column-oriented designs that excel at aggregation, like Vertica, fueled the data warehouse explosion of the 2000s.
Today’s NoSQL movement spurns the rigidity of relational for more exotic, flexible, and scalable designs, such as fast key-value stores (like Redis and Memcached) JSON-loving document stores (MongoDB), super-scalable wide-column stores (Apache Cassandra), and powerful graph databases (Neo4j). NewSQL databases (like MemSQL and VoltDB, meanwhile, have applied the scale-out properties of NoSQL to relational databases, while RDBMs have also adopted some aspects of NoSQL, like JSON support.
In-Memory Data Grids – While databases typically access data from spinning disks, in-memory data grids (IMDGs) store entire data sets in the memory of a single computer or a cluster of servers, providing a big speed boost. Some classes of applications, such as airline flight operation systems, require the ability to get the right answer with constantly changing data sets, and IMDGs have proven up to the task where on-disk databases have failed. Products from GridGain, Hazelcast, Gigaspaces, and ScaleOut Software lead this category.
Streaming Data/Pub-Sub Systems – In recent years, we’ve seen the advent of new data management systems designed to process and store huge amounts of streaming data. Apache Kafka, Amazon Kinesis, and Google Cloud Pub/Sub provide a platform for developers to write applications that take advantage of streaming data.

Some people see streaming data platforms usurping relational databases to provide the foundation for future applications
While these systems are designed for managing the huge flow of streaming data, some of them, such as Kafka, can also persist petabytes of data. In some ways, streaming data systems, IMDGs, in-memory databases, and scale-out relational (i.e. NewSQL databases) are all converging at the same functional place, which is the capability to process and analyze huge amounts of fresh data.
Software Defined Storage – Software defined storage (SDS) has emerged as a virtualization layer that abstracts away differences in underlying storage hardware. SDS products can be implemented atop SAN, NAS, or object storage layers, and provide facilities for common data tasks, such as backup, de-duplication, replication, and provisioning.
Future of Storage Software
Clearly the software side of the data storage equation has evolved as big data continues to impact the volume, velocity, and variety of data. As data storage hardware gets bigger and faster, we scale out (and scale up) to increase data storage capacity. That encourages us to generate or capture more data, which drives demand for bigger and better storage technology –a virtuous cycle of big data begetting even bigger data, to be sure.
Today, enterprises are looking to RAM and flash to speed access to medium-sized data sets. As RAM becomes more affordable, we’re seeing in-memory databases, such as SAP‘s HANA, as well as IMDGs, become more applicable for a greater range of computing challenges. Without the considerable disk overhead of a relational database, SAP is said to house its entire ERP system on a relatively small setup.

The world is gobbling up NVMe flash, such as this DirectFlash storage card from Pure Storage
The world is currently gobbling up all manner of flash disks that travel over the PCIe bus, which uses the NVMe protocol. It is certainly better and faster than shunting data back and forth to solid-state drives over SCSI or SATA access paths. As flash storage becomes ubiquitous, we’re seeing the emergence of new database architectures, such as Yellowbrick Data‘s new flash-optimized OLAP database. We’re aloo seeing the rise of hybrid databases that can handle both OLAP and OLTP workloads, which some call “translytical” databases.
Storage Class Memory
On the horizon are potential hardware breakthroughs that could throw storage hardware up in the air. So-called Storage Class Memory (SCM) products, such as Intel‘s 3D-XPoint and Samsung‘s Z-NAND products, could upend storage technology as we know it.
Arriving together with SCM is a raft of next-generation storage networking protocols that allow data to flow in a much quicker manner between computers, such as Remote Direct Memory Access (RDMA), InfiniBand, RDMA over Converged Ethernet (RoCE), Internet Wide-area RDMA Protocol (iWARP), NVMe over Fabrics (NVMe-oF), and others.
RDMA enables a direct connection between the memories of two computers in a high-capacity, low-latency manner. InfiniBand is a wire-protocol implementation of the RDMA concept, and RDMA host bus adapters from Mellanox, for example, can commonly be found in high performance computing (HPC) installations, but the tech is finding some traction for big data clusters.
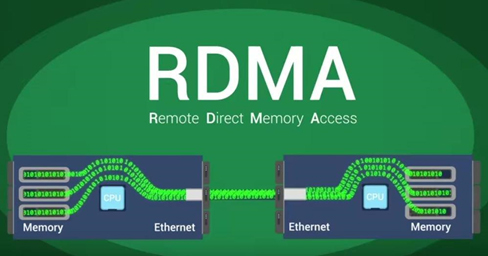
RDMA increases network efficiency by transferring data directly to memory and bypassing the CPU. (Source: RoCE Initiative)
RDMA over Converged Ethernet (RoCE), meanwhile, provides similar functionality as InfiniBand but using standard Ethernet protocols instead. iWARP, meanwhile, provides an RDMA implementation over a bigger geographical area using Internet Protocol.
NVMe-oF, meanwhile, provides a way to share and access storage or memory across a network, instead of over the PCIe bus. Various implementation of NVMe-oF have been created, including ones that work with TCP/IP, Ethernet, and Fibre Channel.
Game Changers
If non-volatile storage class memory gets big enough and cheap enough, it could lead to dramatic changes in the storage equation, including the possibly eliminating the database. That’s the opinion of Lance Gutteridge, a Ph.D. computer theorist who says databases could go the way of the buggy whip.
“The breakthrough in computers that will make a huge difference to the success rate of enterprise systems will be high-speed persistent memory,” Gutteridge writes in an excerpt from his book, IT Disasters. “If we had fast computer memory that was not volatile, that kept its data between power shutdowns, then we would not need a database. We would just keep the data in the convenient format that we use in volatile memory rather than going to all the trouble to translate it into forms suitable for storing in slow, magnetic storage.”
To be sure, this is an exciting time for data storage software. Innovations are occurring at a rapid pace, and new technologies coming down the pike mean potentially significant changes to software.
Related Items:
The Future of Storage: Hardware
Yellowbrick Claims Flash Breakthrough with MPP Database
Applications:
Enterprise Analytics
Technologies:
Storage
Vendors:
Amazon, DDN, Gigasapces, google, GridGain, Hazelcast, intel, MemSQL, Microsoft, MongoDB, Neo4j, Oracle, Samsung, SAP, ScaleOutSoftware, Scality, VoltDB, Yellowbrick
Tags:
big data, block storage, file storage, Flash, iWARP, newsql, NoSQL, NVMe, Object Storage, RDMA, relational database, ROCE, solid-state drives, storage
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States