

June 26, 2018
MapR Makes Platform More Cloud-Like

(vectorfusionart/Shutterstock)
MapR Technologies today unveiled a major enhancement to its big data cluster that introduces features commonly found on public cloud platforms, including support for an S3-compatible API, erasure coding, and a data-tiering function that supports external “cheap and deep” object stores. The changes are part of a move to help customers cope with exabyte-scale and multi-cloud storage challenges.
MapR has always taken a markedly different approach to big data storage and compute than its Hadoop-based competitors, Cloudera and Hortonworks. While MapR does support the Hadoop Distributed File System (HDFS), it also supports POSIX and NFS, which allows its system to be used with a wider group of data science applications and data types.
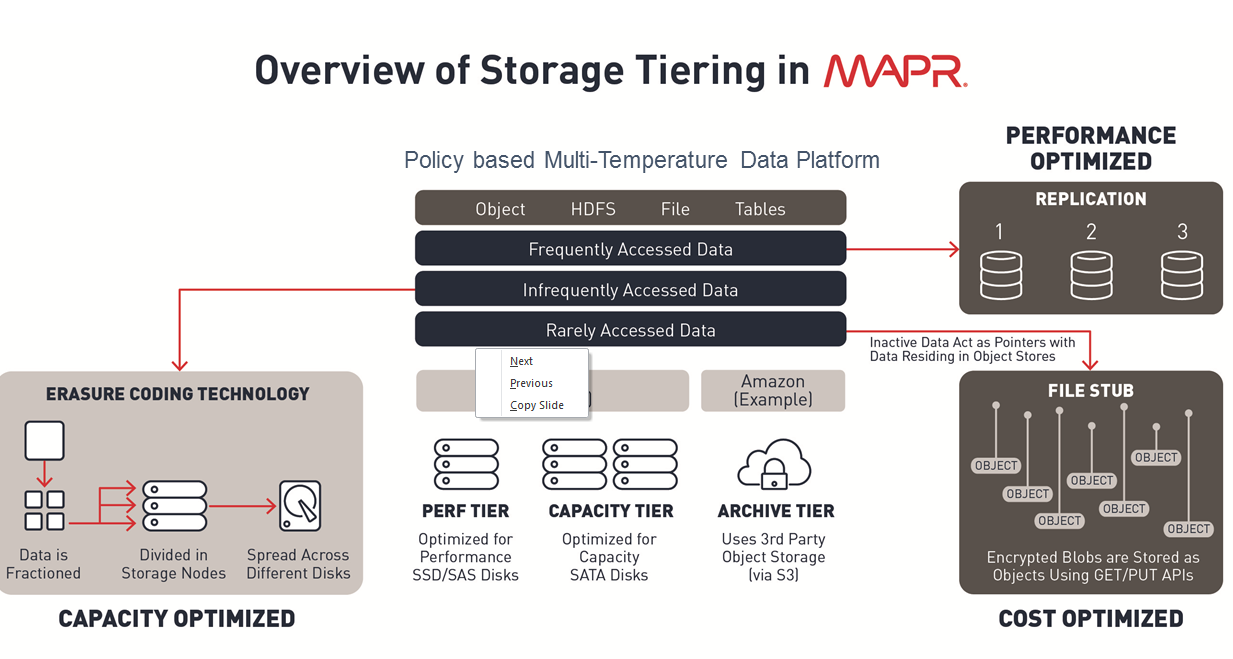
That differentiation continues with today’s announcement. Headlining the changes is the new Object Data Service, which is an S3-compatible API.
MapR previously allowed customers running their clusters in the cloud to read S3 data through optimized cloud connectors. But with the new Object Data Service, customers running on-prem or in the cloud can now write data into the MapR cluster in an S3-compatible format.
Having an S3-compatible API will give customers several benefits, according to Anoop Dawar, MapR’s senior vice president product management and marketing. One of those is giving cloud customers the ability to move their clusters among different cloud providers, if they so choose.
(Image courtesy MapR)
“What we see is native cloud customers realizing they need a hybrid strategy or a multi-cloud strategy,” he says. “Even if they double-down on a single cloud provider as their favorite defacto cloud, what happens is 6 months later they acquired another company which many have chosen an different cloud and voila — you’re now in the multi-cloud world.”
MapR’s product is supported on all major cloud providers, including Amazon Web Services, Google Cloud Platform, and Microsoft Azure. But its goal is to force its customers to be beholden to any of them. “We are trying to makes sure that the customers are able to use the best of the cloud and have the flexibility and elasticity to choose where to run their applications,” Dawar tells Datanami.
This new feature also lets MapR customers have an S3-compatible on-premise data store, which can be useful in certain situations, Dawar says. For example, if a customer has a lot of genomic data that’s stored in NFS and normally accessed through POISX-compatible applications, but a customer wants to use a new analytic tools that supports an S3 interface, they could utilize MapR without having to resort to heavy ETL-based data movement process.
“You simply move the data into MapR because we support POSIX,” Dawar says. “You continue to run POSIX applications on that data, and then you can also take that same data and run your S3 tools without making copies.”
The new object tiering feature opens up MapR to work with external object stores, including those running on-prem and in the cloud. This feature allows MapR customers to automatically move rarely accessed datasets into external object stores, thereby allowing them to maintain the storage and application efficiency of their MapR cluster. But since MapR retains the metadata of the data moved into the external object store, it can be quickly recalled should the data be needed.

(Image courtesy MapR)
Dawar says it might sound silly that MapR, whose whole goal is to encourage customers to store data in MapR, is creating a feature that moves data out of MapR. But he assures that there’s nothing silly about it. “Our customers have experienced the whole journey,” he says. “The fact is, they also need cheap and deep storage…The amount of data we’re taking is Exabyte scale. It’s too much.”
For example, say a company is embarking upon a connected car project. The company may have plans to use a given piece of data for a couple of use cases, but they have no choice but to store it. If the data adds up to an Exabyte, keeping it on a fast, optimized analytical system like MapR just doesn’t make sense.
These cheap and deep stores provide you a cost effective way of storing that data, Dawar says. “The operational overhead of moving it from MapR [or other fast analytical environments] to a cheap and deep data store, and bringing it back and making sure it’s secure and compliant and that policies are not lost…is a massive operational burden.”
MapR works with customers to address these types of pain points and to solve the “end to end” data storage and analysis problem, Dawar says. “That’s where the differentiation and benefit is,” he says. “We continue to serve the needs of AI and analytics to offload that data whenever a customer needs.”
MapR is also introducing erasure coding, which is the data protection scheme that’s commonly used in object storage systems, such as S3. This is a feature that was also recently added to Apache Hadoop 3. With the recent addition of erasure coding to Hadoop, customers were given the option of storing data with an erasure coding scheme, instead of HDFS’s triple-replicated scheme. That gives them a 50% boost in the amount of data they can store on a given cluster.
MapR built its own erasure coding scheme, and did not rely on Hadoop 3, Dawar says. The company is positioning erasure coding a preferred data replication scheme when fast ingest of data is needed, and also for capacity-optimized tiers or those using high speed solid state drives for optimized analytics.
The Santa Clara, California company is also giving customers an option to have their clusters automatically configured to be secured out of the box. “We are now going to, from this release onwards, install security by default, to make sure everything is encrypt on the wire, everything is trusteed and authenticated, and you as a closer now start off with a secure system from the beginning,” Dawar says.
Lastly, MapR is updating its cluster to support the latest big data projects, including Apache Spark 2.3, Apache Hive 2.3, and Apache Drill 1.14. The company is also supporting KSQL with its Apache Kafka-compatible streaming analytics layer, dubbed MapR Streams.
Related Items:
Inside MapR’s Support for Kubernetes
MapR Rebrands Around Converged Data Fabric
MapR Extends Its Platform to the Edge
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States