

April 26, 2018
Inside Intel’s nGraph, a Universal Deep Learning Compiler

The advent of deep learning has spawned new life into the quest to create artificial intelligence. But along the way, we’ve become awash in technological complexity, forcing data scientists to juggle multiple deep learning frameworks and hardware platforms against increased demands for their work. Now Intel hopes to cut through the clutter with a novel new approach to boosting AI developer productivity with a universal deep learning compiler.
Intel last week announced that it would open source its nGraph Compiler, a neural network model compiler that supports multiple deep learning frameworks on the front-end, and compiles optimized assembly code that runs on multiple processor architectures on the backend. Intel isn’t marketing nGraph as a universal deep learning compiler, but that effectively is what it’s creating.
On the front-end, nGraph currently supports TensorFlow and MXnet, two popular deep learning frameworks developed by Google and Amazon, respectively. It also supports ONNX, an open deep learning model standard spearheaded by Microsoft and Facebook, which in turn enables nGraph to support PyTorch, Caffe2, and CNTK. Also supported is neon, a higher-level deep learning API that Intel developed to work with nGraph.
On the back-end, nGraph currently supports Intel’s Xeon CPU, the Intel Nervana Neural Network Processor, and Nvidia‘s GPU. The roadmap calls for supporting field programmable gate arrays (FPGAs) and Intel’s Movidius vision processing unit (VPU). Other optimized hardware platforms, such as application-specific integrated circuits (ASICs), could eventually be supported too.
Intel says nGraph has the capability to significantly boost developer productivity by providing a single API that AI developers can build to. This eliminates the need for developers to make design-time decisions based on the targeted hardware platform that would restrict their ability to use other platforms in the future.
According to Arjun Bansal, Intel’s vice president and general manager of AI Software and the Intel AI Lab, nGraph benefits developers by reducing complexity across three dimensions.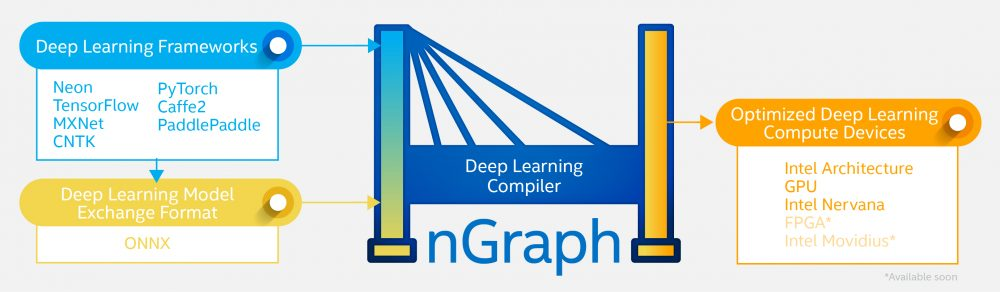
“Previous to this, we had this many-to-many problem where there’s this proliferation of lots of different deep learning frameworks,” Bansal tells Datanami. “All these customers have their own frameworks. And then on the hardware side, Intel has on the order of five to 10 hardware platforms, depending on the performance and power tradeoffs that our customers are making.”
Bansal says the third dimension is the number of AI workloads, such as computer vision, speech recognition, and natural language processing (NLP) programs, that are proliferating thanks to the research that’s being done and the positive early results that Web giants are getting with deep learning.
“If you take the product of the frameworks, the hardware back-ends, and these workloads, it ends up being a lot of work, a combinatorial amount of work that’s increasing exponentially,” Bansal says. “From our perspective, we can’t go out and hire exponentially more engineers to keep up with all that, so a compiler approach which packages a lot of the common work that we were seeing, that we were doing — that’s the way to make this problem more manageable.”
Inside nGraph
The nGraph compiler starts with the computational graph generated by each of the frameworks, says Bansal, who was one of the founders of Nervana. “What we’re basically doing is taking that graph and doing graph optimizations and compile optimizations,” Bansal says.
The nGraph compiler looks for patterns in the graph, and then seeks to optimize the operations called for in the framework code. “The idea is to perform several of these optimizations, then emit an optimized version of the graph that gets translated into an optimized assembly level kernel for the primitive that is emitted by the optimized graph,” he says.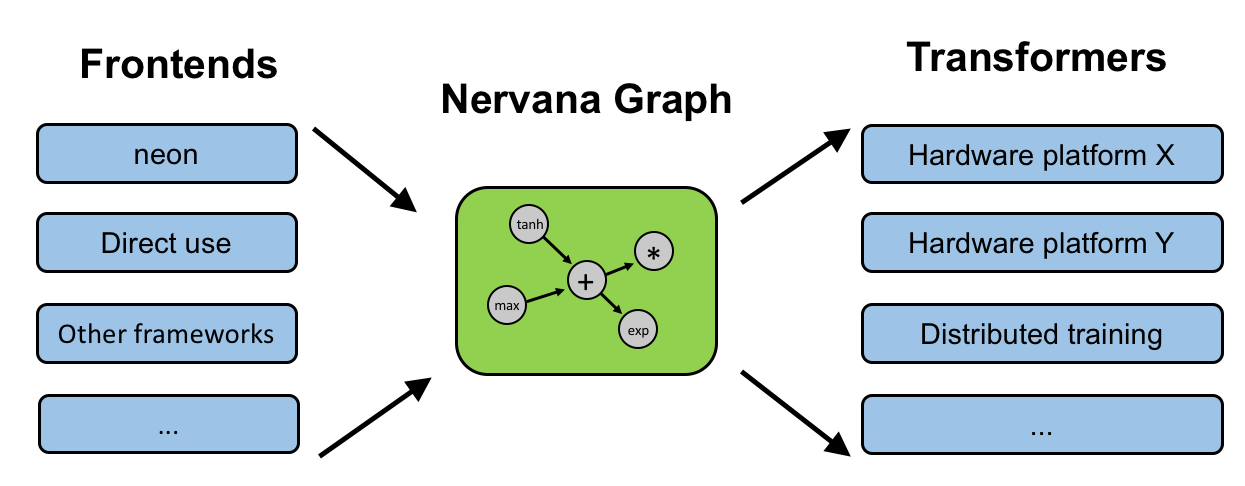
In TensorFlow and Theano, developers are required to understand the underlying tensor shapes while constructing the graph. However, this is tedious and error prone, and eliminates the capability of the compiler to re-order the shape to match the assumptions made by particular processors, Intel says on its nGraph webpage.
“Instead, the ngraph API enables users to define a set of named axes, attach them to tensors during graph construction, and specify them by name (rather than position) when needed,” Intel says. “These axes can be named according to the particular domain of the problem at hand to help a user with these tasks. This flexibility then allows the necessary reshaping/shuffling to be inferred by the transformer before execution.”
According to this blog post by Scott Cyphers, the principal engineer for Intel’s Artificial Intelligence Products Group, nGraph works as an intermediate representation layer that abstracts the AI developer from the details of the device the software will run on.
Cyphers says nGraph creates “a strongly-typed and device-neutral stateless graph representation of computations.” Each node in the graph “corresponds to one step in a computation, where each step produces zero or more tensor outputs from zero or more tensor inputs.”
Each supported framework has a “framework bridge,” while supported hardware device have specific transformers that “handle the device abstraction with a combination of generic and device-specific graph transformations.”
Optimized Learning
nGraph helps AI developers get good performance out of a variety of deep learning programs, including convolutional neural networks, recurrent neural networks, reinforcement learning, and others. But it does so in a way that doesn’t take away a developer’s option to further tweak the code to get more performance out of it, Intel says.
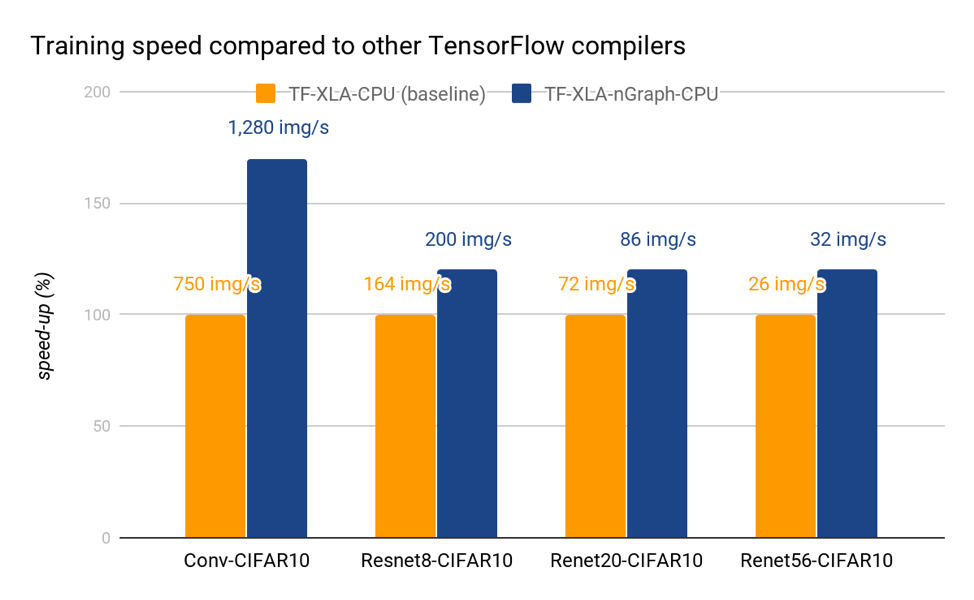
nGraph provides a training speed advantage on TensorFlow compared to other compilers (source: Intel)
“I think what we’re simplifying is the delivery of optimized performance,” Bansal says. “But the frameworks still have a lot of flexibility and freedom in terms of the kind of experience they want to deliver in turn to their end customers. We’re just making it easier for them to get good performance, or the best performance that they can offer.”
According to Bansal, Intel is aiming to have nGraph-compiled AI programs run at about 80% of the performance of hand-coded programs. nGraph has actually exceeded that level in early testing, but 80% remains the target. Compared to non-optimized code, nGraph-compiled programs run significantly faster, Intel’s benchmarks show.
“Obviously, if you have enough people working on a problem for long enough, they should be able to do better with hand-optimized code,” he says. “But the idea is, by using a compiler approach, we can get to let’s say 80% of the performance of hand optimized code, then that significantly improves the out-of-the-box developer experience.”
A “significant amount of effort” went into developing nGraph, including research conducted by Nervana Systems before it was acquired by Intel in 2015. The company is making the source code open in the hopes that it boosts the adoption of the product, and also to allow others in the deep learning community to continue its development.
Related Items:
New AI Chips to Give GPUs a Run for Deep Learning Money
Intel Details AI Hardware Strategy for Post-GPU Age
Applications:
Artificial Intelligence
Technologies:
Processors
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States