

April 18, 2018
Presto Use Surges, Qubole Finds
Don’t look now, but Presto, the SQL engine developed by Facebook as a follow-on to Hive, is starting to catch on in a big way. According to a new survey of big data-as-a-service customers by Qubole, Presto logged impressive usage gains during 2017, and outgrew Hive and Spark across many metrics.
Qubole sees big data workloads growing across the board. And Hadoop/Hive remains the big daddy of big data engines. But Presto notched bigger gains than the other two big data engines across several measurements, according to Qubole’s “2018 Big Data Activation Report,” which reflects data collected from 200 Qubole users.
Here is some data from Qubole’s report, which was released yesterday:
Presto grew 420% in terms of compute hours on Qubole’s cloud platform from January 2017 to 2018. That beat Hadoop/Hive, which grew 102%, and Apache Spark, which grew 298%.
The number of Presto users increased, according to Qubole, which found that the year-over-year increase in the number of users that ran commands on Presto went up by 255%, compared to 171% for Spark, and 136% for Hadoop/Hive.
The number of commands run by users also went up considerably across the board, to 58 million commands last year. The number of Spark commands issued on the Qubole cloud increased by 439%, while Presto commands grew by 365% and Hadoop/Hive commands increased 129%.
In aggregate, customers are running 24x more commands per hour in Presto than Spark, Qubole found, and 6x more commands in Presto than in Hadoop/Hive. This data reflects the different things that each engine is good at, Qubole says.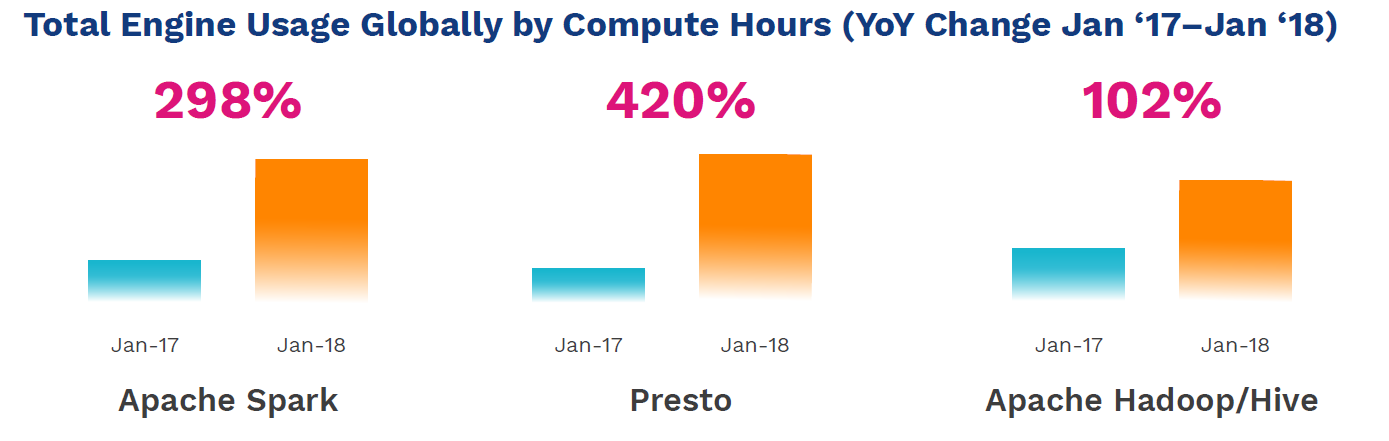
“The impressive growth in Presto suggests greater efficiency and self-sufficiency, as it is a powerful tool for use cases with interactive and ad hoc SQL analytics where joins and highly concurrent simple queries are common,” Qubole writes in its report. “This engine doesn’t require a user to constantly tune cluster configurations, thereby reducing drastically the time-to-insights.”
Presto is a distributed in-memory SQL query engine originally developed by Facebook and released in 2013 to be a faster and more flexible alternative to Apache Hive (Qubole co-founders Ashish Thusoo and Joydeep Sen Sarma created Hive while managing Facebook’s Data Service Team). While it’s not tied to Hadoop, Presto can run on a Hadoop cluster, if needed. And in addition to processing data residing in HDFS, Presto has the capability to work with data stored in relational databases (Facebook is a big MySQL user) as well as object stores like Amazon S3.
Presto has other advantages, including arguably a more complete coverage of the ANSI SQL standard, according to Justin Borgman, CEO of Starburst, the commercial open source company behind Presto that was recently spun out of Teradata. A new query optimizer that’s in the works is expected to boost the speed quotient for Presto even more.
Qubole noted several other trends that emerged from its users’ anonymized data, including:
- A strong correlation between the size of its customers and the relative self-sufficiency of the users, measured in terms of the ratio between administrators-per-user;
- Customers use of Amazon EC2 Spot Instances also grew by nearly a factor of 5x across the three engines, suggesting greater customer sophistication at minimizing cloud costs;
- Growing adoption of new big data tools, including Apache Airflow, which saw a nearly 30% increase in usage, as well as TensorFlow, XGBoost, Pandas, and MLlib.
You can register for a copy of the report here.
Related Items:
Building Presto Business No Magic Trick for Starburst
Teradata Bets Big on Presto for Hadoop SQL
Facebook’s Super Hive-Killing Query Machine Now Yours
Applications:
Enterprise Analytics
Technologies:
Frameworks
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States