

April 2, 2018
What’s Fueling Deep Learning’s ‘Cambrian Explosion’?

It’s fair to say that University of Toronto computer scientists Alex Krizhevsky, Geoffrey Hinton, and Ilya Sutskever didn’t know what they were about to unleash. It was 2012, and they had just submitted details about their new machine learning model, dubbed a convolutional neural network, to the folks who run the ImageNet competition.
The trio’s CNN featured just eight layers – five convolutional layers and three fully connected layers. Yet it was so good at classifying images that the GPU-based system beat the rest of that year’s ImageNet field by nearly 11%, which is a huge margin as these things go. But more importantly, that winning model, known as AlexNet, would go on to jumpstart the modern field of deep learning.
Today, AlexNet forms the basis for an untold number of deep learning models. Nvidia CEO Jensen Huang first dubbed this flowering of deep learning a “Cambrian explosion” at the 2017 GPU Technology Conference, and he used that language again at last week’s show.
“Neural networks are growing and evolving at an extraordinary rate, at a lightening rate,” Huang said during last Tuesday’s marathon two-and-a-half hour keynote address. “What started out just five years ago with AlexNet…five years later, thousands of species of AI have emerged.”

Nvidia CEO Jensen Huang has talked about a “Cambrian Explosion” around deep learning (double click to enlarge image)
Huang listed off several of the types of deep learning models that have emerged since AlexNet’s first stunning victory: recurrent networks, generative adversarial networks, refinforcement learning, neural collaborative filtering. “All of these different architectures and hundreds of different implementations,” Huang said. “The number of species that’s growing is so incredible, and there are so many new ones coming out.”
As the field of deep learning has gotten richer and more complex, so have the individual deep learning models. When AlexNet debuted in 2012, it had just eight layers and a few million parameters but today’s neural networks sport hundreds of layers and billions of parameters. That corresponds with a 500x increase in deep learning model complexity over the past five years, according to Huang.
What AlexNet demonstrated to the world is that the combination of better software, faster hardware, and (lots) more data could introduce better and more accurate predictive models. The deep learning approach also formed the basis for a renaissance in artificial intelligence (AI) that’s changing how we think about computing.
“The amount of data is growing exponentially. There is evidence that with GPU computing, the computation is growing exponentially,” he said. “And as a result, deep learning networks and deep learning models — AI models — are growing in capability and effectiveness at a double exponential.”
Ongoing Expansion
Finding the right ingredients to supercharge a machine learning task is impressive in its own right. But what’s more interesting is that a model named AlexNet could bootstrap an entirely new approach to computing. That is truly fascinating.
“What’s more amazing is that people were able to keep improving it with deep learning,” Sutskever, one of the original developers of AlexNet, told Quartz in a 2017 interview. “Deep learning is just the right stuff.”
Today, deep learning is seeping into the enterprise, and combining with other forms of machine learning to boost the capabilities of corporations.
“The interesting pivot we’re seeing now is this move between machine learning and deep learning,” said Chad Meley, vice president of marketing at Teradata. “We’re seeing many clients going after the same kinds of use cases, like fraud detection, customer intimacy, supply chain optimizing, yield management – but by applying deep learning as opposed to the machine learning that they’ve been doing over the last five years, they’re getting better predictive outcomes, better models. It’s just more accurate.”
That doesn’t meant that customers are ripping their existing machine learning frameworks out and replacing them with deep learning models built with Google‘s TensorFlow or Facebook‘s PyTorch or any number of other capable deep learning frameworks that have been open sourced over the past few years. It’s more of an ensemble approach, said Atif Kureishy, vice president of global emerging practices at Teradata.
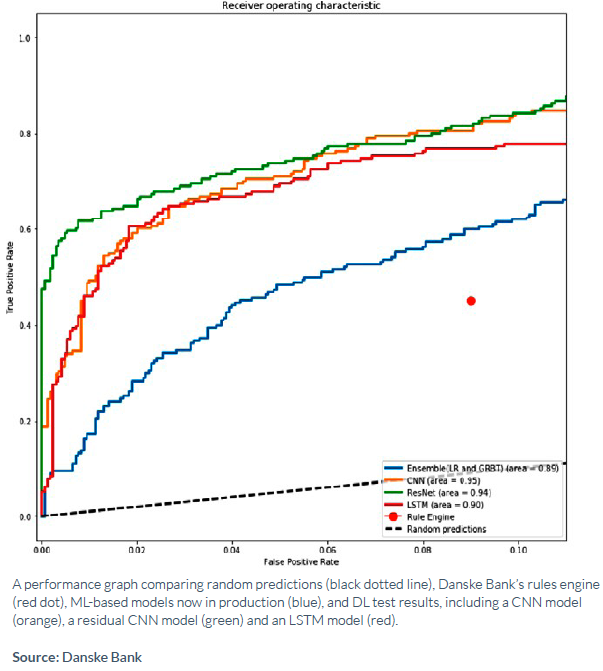
Danske Bank’s tests shows deep learning (green line) offers lower false positives for a fraud detection system than other approaches
“If you set up the right problem in the right way, it can definitely improve your accuracy,” Kureishy told Datanami at last week’s GTC 2018 show. “But in almost every engagement we’ve done, where customers have gone into production using deep learning, it’s usually through an ensemble of models that has traditional machine learning as well as deep learning models.”
Teradata is looking to move up the analytics stack, beyond its roots in enterprise data warehousing, and the expansion of its partnership with Nvidia unveiled at last week’s show shows it. As part of Teradata’s Analytics Platform, the company eventually seeks to enable users to essentially spin up whatever analytics environment a data problem might demand – such as a GPU cluster for deep learning or memory-heavy CPU cluster for Spark workloads – at the push of a button.
The company is still a ways from delivering that capability, but its customers are already utilizing deep learning in innovative ways. One of those is Danske Bank, which tapped Teradata’s Think Big Analytics group to build a better fraud detection engine using deep learning technology.
Kureishy explained what the company did. “Essentiality we took time-series data, and over time we built out an N-dimensional array, a matrix,” he said. “We threw many features at it: Features about the transaction, features about the originator, the destination, the IP address. It was a huge feature space.
“Then we turned that into an arrangement that looked like a pixelated image,” he continued. “We created essentially RGB value of all those features relative to that time series data…. And then we ran it through an AlexNet architecture, and what popped out were imagery that had different colorization, and the intensity of the pixel essentially demonstrated what was going on.”
By essentially taking tabular data and using it to emulate an image that a CNN could signal on, the bank created better mousetrap than what it was capable of doing with machine learning alone. According to a write-up by Constellation Research, Danske Bank’s new system was responsible for a reduction in fraud false positives by 20% to 30%. It also used the LIME framework to help to explain to auditors how Danske Bank’s deep learning system detects fraud, which is a growing concern for anybody relying on “black box” techniques.
“We did a lot of experimentation, and this actually panned out to be the most effective,” Kureishy said. “We had to do all that enrichment and do the inference across six machine learning and deep learning models in 100 milliseconds. But the hardest part was getting data from the IBM mainframe, and other columnar stores.”
Turning Geoff Hinton’s academic research in neural network architectures into a self-teaching system capable of winning the ImageNet prize surely kicked off the Cambrian Explosion of deep learning that we’re experiencing. But what’s fueling that explosion now is stories like the one from Danske Bank that show how real-world companies are finding the technology useful for solving business problems.
Related Items:
Reporter’s Notebook: The 2018 GTC Experience
Nvidia’s Huang Sees AI ‘Cambrian Explosion’
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States