

March 28, 2018
ArangoDB Reaping the Fruits Of Its Multi-Modal Labor
Why do just one thing well when you can do three things well? That’s the philosophy behind ArangoDB, an open source NoSQL database that lets users store, query, and retrieve data using three different data models — a JSON-based document database, a key-value store, and a graph database — depending on the users’ needs.
ArangoDB emerged about seven years ago when two German engineers, Claudius Weinberger and Frank Celler, were designing databases for large public companies in the European Union through their consulting company, triAGENS GmbH. The pair tired of compromising by using multiple databases to solve different data storage and retrieval tasks, and decided to take a new approach. Soon thereafter they laid down the first bits of code for AvocadoDB, which would become ArangoDB several years later due to a name dispute.
Fast forward to 2018, and the database (now named after a type of avocado found in Central America) is starting to pick up steam. The software has been downloaded 3.5 million times, and is currently being downloaded at the rate of 170,000 per month, the company says. More than 1,000 organizations are using ArangoDB in production (although fewer are paying for the enterprise version), and there are more than 80 contributors to the open source project outside of ArangoDB.
All in all, the popularity of the software is growing quite quickly, which ArangoDB president Luca Olivari attributes to its flexibility.
“ArangoDB is a native multi-model database,” Olivari tells Datanami. “What the founders decided to do is to marry JSON documents with graph and key-value in one engine with one query and one query language that allow you to use multiple data models. So you get the flexibility, in a sense, of MongoDB with JSON document, with the connectedness of Neo4j with the graph theory. By marrying them both, you can really address a lot of use cases.”
Native Engines
The folks at ArangoDB are quick to emphasize the native aspect of the database. The product was designed to store and query data in an optimized manner for each of the three modalities — key-value, document, and graph — without compromising the capabilities that make each of those types of database good for certain use cases.
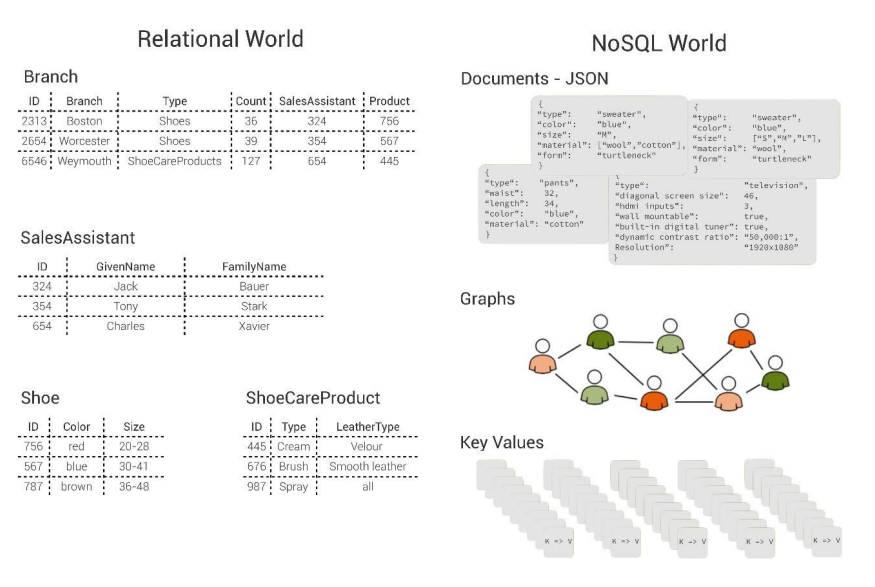
Different data models demand different databases (Source: ArangoDB December 2016 white paper “What is a multi-model database and why use it?”)
At the core, the database stores data in VelocyPack (VPack), which is a “fast and compact binary format used for serialization and storage,” according to the project’s GitHub page. ArangoDB can natively store a nested JSON object as a data entry inside a VPack collection, which the company says eliminate the need to disassemble the resulting JSON objects. Queries are written and submitted in ArangoDB Query Langauge (AQL), which resembles SQL.
“At the very heart we are a transactional document store storing a JSON document,” says Jan Stücke, a developer with ArangoDB. “If we want to provide KV characteristics, then we just store a key and a value and have an index on the key. If we want to go to graph, then we’re doing two things. First we store a special attribute, which is a ‘from’ and a ‘to,’ which are pointing to other JSON documents. And then we index those other attributes in so-called hash index, and can declare it quite efficiently.”
In this manner, ArangoDB can quickly morph from a sleek and fast key-value store optimized for serving lots of relatively simple data, into a more complex graph database optimized for finding connections hidden in more complex data sets. Doing all three of these things in a native manner — not to mention ACID compliance for transactions and a horizontal scale-out architecture — makes ArangoDB somewhat unique among database management systems.
Running ecommerce websites is one use case for ArangoDB. Others include security, fraud detection, machine learning, product and asset catalogs, real-time analytics, customer and content management, and customer 360 initiatives.
Multiple Modalities
The advantages of the multi-modal approach are evident for those building ecommerce websites, Olivari says. “In the single model world, you have a shopping cart on Redis, your product catalog on MongoDB, your recommendation engine on Neo4j, and your transactions on Oracle,” he says. “The downside is there are different query languages to learn, many databases to manage, complex code bases, and a lot of cost and lost productivity.
“With ArangoDB, you don’t really need to have one massive complex database,” Olivari continues. “You can still have multiple databases if you want and expose microservices if you want. But then you can manage the key-value part for the shopping cart on ArangoDB. You can use the catalog using the JSON interface of ArangoDB. The recommendation is using graph and transactions again on ArangoDB.”
These three database types fit well together, and ArangoDB doesn’t plan on extending it dramatically, Olivari says. “We cannot really support all the of data models out there,” he says. “But if you think about it, the JSON document using the graph theory — they work extremely well. So you can say ArangoDB is a graph database wherever vertexes and edges [exist] in JSON documents. It’s really natural for those data models to stick together.”
You won’t see ArangoDB adding other data types that fit nicely with what it already has. “For example, we don’t plan to add wide column store. So we’re not saying we can add the data model used by Cassandra,” Olivari says. “We don’t plan to add time series. You can model it in multi-model database, but it won’t be native.”
Competing for Advantage
The native support for key-value, document, and graph gives ArrangoDB an advantage over other NoSQL database providers who would try to bolt on graph capabilities, Olivari says. “It’s not easy to go there, because it’s an architectural advantage,” he says. “People would have to start with a native idea. Some of our competitors are trying to move to the multi-model world, but it will never be native.”
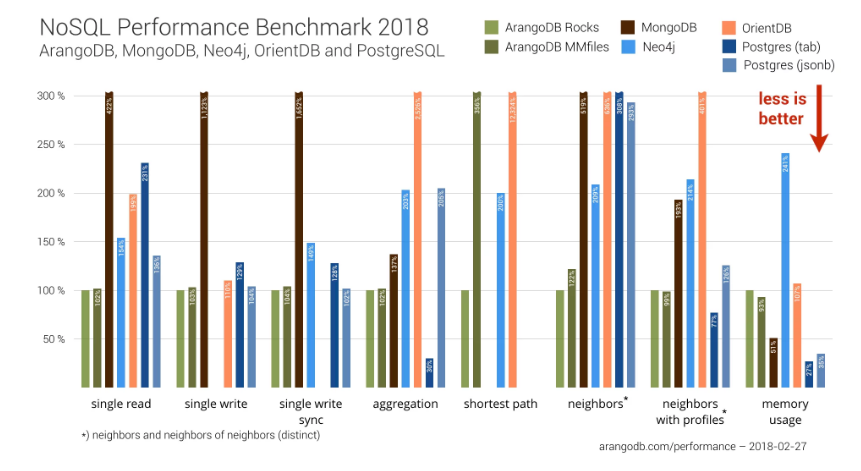
Performance comparison of NoSQL databases (Source: ArangoDB)
Building the architectural foundation that lets ArangoDB morph into different database personas gives it a performance advantage that allows it to perform as well as best-of-breed database solutions. The company recently conducted a benchmark test that showed ArangoDB outperformed other single-mode databases it was tested against, including MongoDB, Neo4j, OrientDB, and Postgres.
In another test, ArangoDB was beaten by Aerospike, a SSD-optimized key-value store. “We were expecting this,” Olivari says. “If you have a very simple data model, then you can press performance as much as possible. With key-value stores, in a sense they may outperform us. But the key-value use case isn’t the one most widely used because it would be basically just using 10% of the functionality around ArangoDB.”
Looking forward, the ArrangoDB team is working on version 3.4, which will add support for geospatial data types, expanded Kubernetes, and the addition of a search engine.
The addition of the search engine, which was developed at Dell EMC and open sourced at the end of 2016, will greatly expand the capabilities of ArangoDB, Stücke says. “It’s a full-fledged search and ranking engine which runs natively in ArangoDB,” he says. “You can also combine the results of the search engine with different data models and vice versus. We hope that the retrieval capabilities, in combination with multi-model, can make a big difference in the search market.”
ArangoDB version 3.4 is due in the second quarter.
Related Items:
A Look at the Graph Database Landscape
What SQL’s Co-Creator Sees in NoSQL
SQL Databases Integrating NoSQL-like Features
Applications:
Enterprise Analytics
Technologies:
Middleware
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States