

March 19, 2018
Which Machine Learning Platform Performs Best?

(Hobbit/Shutterstock)
The advent of automated machine learning platforms has expanded the access and availability of algorithmic interpretation over the past several years. But how do the different machine learning platforms stack up from a performance perspective? That’s the question that researchers from Arizona State University sought to answer.
As the market for machine learning platforms expands, users are naturally inclined to seek sources of information to rank and rate the various options that are available to them. Which systems are the easiest to use? Which ones run the fastest? Which ones give the most accurate answers?
However, most of these questions have gone unanswered, according to the folks in Arizona State University’s Department of Information Systems. While analyst groups like Forrester and Gartner sometimes make references to performance in their product reviews, there has been no systematic attempt to measure the actual performance of the tools themselves, the ASU researchers say in a forthcoming paper titled “Performance comparison of machine learning platforms.”
“As far as we know, there have been no prior studies to compare machine learning platforms or collections of algorithms,” write ASU Professor Asim Roy and 18 other researchers listed as authors in the paper, a copy of which was shared with Datanami ahead of its publication.![]()
In the 41-page paper, the researchers first lay out a method to evaluate and compare collections of algorithms, and then present the results of their comparison work.
“One of our primary goals is to present a framework to objectively evaluate claims of superior performance by platforms” reviewed by analyst groups. “We thus provide a capability to firms such as Gartner and Forrester to more rigorously evaluate the platforms rather than just rely on customer testimonials and thereby misinform the marketplace about performance issues.”
Algorithmic Showdown
Three main ingredients went into the test, including a selection of algorithms, a collection of machine learning platforms, and a of course some data to crunch.
The researchers settled on a group of commonly used classification algorithms that can be found in every automated machine learning platform. This includes support vector machine (SVMs); logistic regression; multilayer perceptron (neural networks); decision trees/boosted decision trees; random forest; and naive Bayes/Bayesian nets.
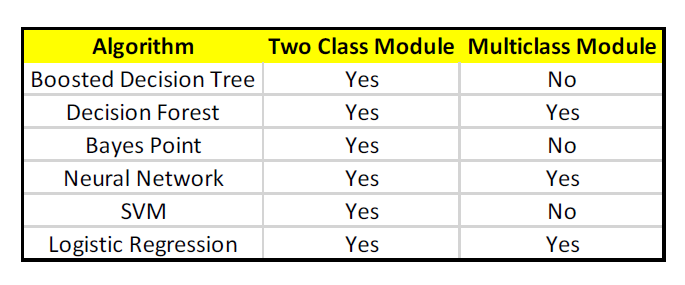
Types of problem each algorithm is asked to solve (Source: Forthcoming ASU paper “Performance comparison of machine learning platforms”)
As far as machine learning platforms go, the researchers selected six commonly used platforms, including: SAS version 9.4; IBM‘s SPSS version 18.0; Microsoft Azure ML 2016; Apache Spark ML, via Databricks Community Edition 2.35 cloud offering; R, via the CARET package; and Python, via Scikit Learn version 0.18.0.
The data comes from three benchmark data sets, including the University of California Irvine (UCI) machine learning repository; various data sets from Kaggle; and a set of high-dimensional gene expression data. Each of the data sets had an associated set of classification problem, such as predicting credit card defaults or detecting brain tumor types, which the ASU researchers used for their analysis.
All told, the ASU researchers ran and compared each implementation of the specific algorithms across each of the machine learning platforms for 29 different classification problems.
Testing ML Platforms
In terms of methods, the researchers took pains to follow best practices. Before testing, they combined the original training and test datasets (if available) and then used random sub-sampling cross-validation techniques on the combined dataset to generate training and testing sets. They did this 10 times for each data set and then calculated the average accuracy and standard deviation.
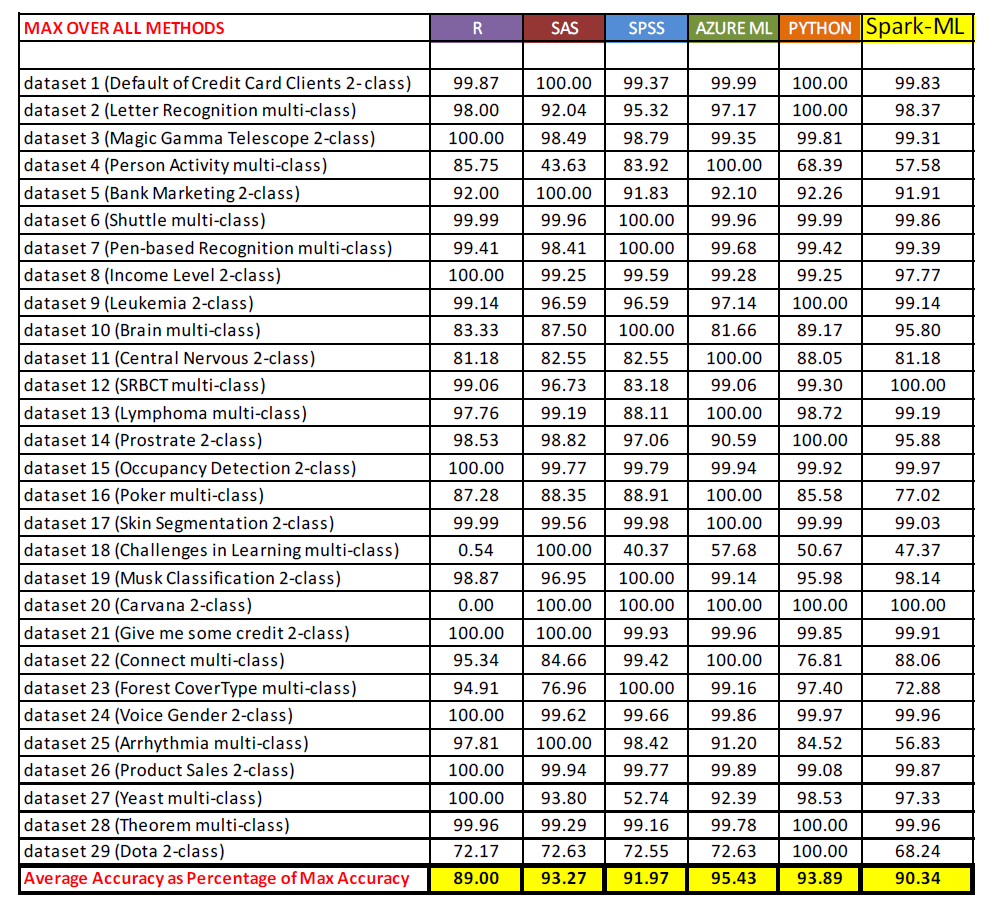
Accuracy of each ML platform across all 29 tests (Source: Forthcoming ASU paper “Performance comparison of machine learning platforms”)
The researchers left out one important step that most data scientists would perform in the real world — feature selection and extraction – because the majority of algorithms it tested do this themselves. “Given such inherent algorithmic capabilities, one of our objectives was to find out how well the algorithms on a platform perform on high dimensional data without the benefit of prior feature selection and/or extraction – both individually and collectively,” they write.
As far as tuning goes, the researchers did their best given the optimization methods available in each of the tools. That means that, for the R package, it used a full grid search for most datasets, while for other packages that don’t offer hyperparamter optimization, like SAS, it ran algorithms with default parameters (although they did do some tuning for SAS).
Analyzing ML Results
Once the tests were run across the 29 problems, the researchers used statistical tools to analyze the results coming out of the six machine learning platforms. It used three methods to analyze the results, including a relatively straightforward accuracy test for all problems. For the 16 two-class problems, it also used an F-score and AUC (area under the curve) approach to understanding the results.
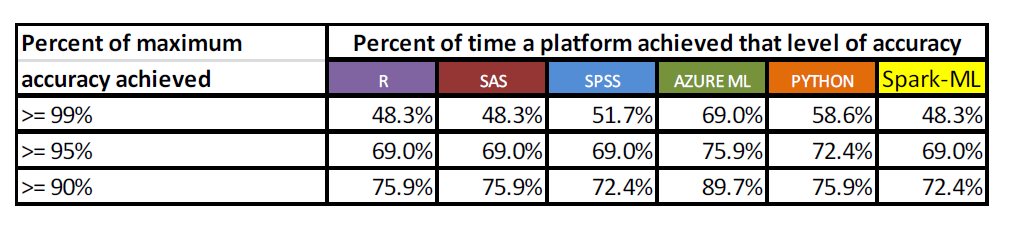
No machine learning platforms really separated themselves from the pack in terms of accuracy (Source: Forthcoming ASU paper “Performance comparison of machine learning platforms”)
These analyses gave some interesting figures. For the accuracy measure, when ranked one through six across all 29 problems, none of the platforms differentiated itself in a meaningful way. Azure ML was the highest ranking platform with an average total ranking of 2.948, followed by Python (3.069), R (3.121), SPSS (3.793), SAS (3.897), and Spark ML (4.172).
When judged by F-score, a similar thing occurred. R led the pack with an average ranking of 2.27 across the 16 two-class problems, followed by SPSS (3.20), Python (3.60), Spark (3.33), Azure ML (4.27), and SAS (4.33). For the AUC measure, Azure came in first with a 1.9375 rating, followed by Python (2.375), SAS (2.5), SPSS (3.31), and Spark (4.875). (R was left off this test because of various errors).
And the Winner Is…
The researchers concluded that, when the results are taken as a whole, there were no clear winners in its machine learning platform comparison.
“When compared on the basis of accuracy and F-score, we cannot reject the hypothesis that all platforms perform equally well, even though some didn’t permit parameter tuning or had limited parameter tuning capability,” Only the AUC comparison shows that these platforms are different, with Azure ML, SAS and Python being better performers. If we accept the findings from a majority of the performance measures (i.e. accuracy and F-score), then all of these platforms perform equally well.”
As machine learning becomes more popular, the ASU researchers hope that this sort of testing can help steer users toward better buying decisions, just as consumers rely on ratings and comparisons to buy automobiles.
“The study we presented in this paper hopefully will begin an era of comparing machine learning platforms, not just algorithms,” the ASU researchers conclude. “Over the next decade, thousands of big and small companies will be using off-the-shelf machine learning platforms and this kind of information could be critical to their evaluation of these platforms.”
Related Items:
Winners and Losers from Gartner’s Data Science and ML Platform Report
Forrester Reshuffles the Deck on BI and Analytics Tools
Applications:
Data Mining
Technologies:
Middleware
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States