

March 6, 2018
Inside MapR’s Support for Kubernetes

MapR today announced that customers can now run and deploy applications on MapR’s big data cluster utilizing the Kubernetes containerization technology. In addition to providing data statefulness, it also gives MapR customers a new way to move workloads from on-prem to cloud platforms.
The delivery of a native Kubernetes K8S volume driver seems like a relatively simple thing, acknowledges MapR‘s Senior Vice President Data and Applications, Jack Norris. “OK, you guys updated a volume driver,” he said in an interview with Datanami. “Why should I get excited and jump up and down for your volume driver?”
Norris provided an answer to his question. “The reason for that can be such a breakthrough is because of the capabilities in the underlying platform,” he said. “The update was light, but it leverages the near-decade of innovation in that platform, which are not small innovations.”
The delivery of a volume driver for Kubernetes lets MapR customers use their big data cluster as they have been accustomed to do – including HDFS, S3, NFS POSIX, ODBC methods — with the added benefit of getting the flexibility and portability that Kubernetes provides.
Norris compared how MapR approached Kubernetes versus how other vendors approached it. “They’re either a write-once data platform that can’t support traditional access, or they’re limited in terms of high availability and data protection, so it would mean compromising the SLA,” he says. “Or it’s a different API that would require re-writing the applications that you want to containerize.”
There are a lot of reasons why these approaches don’t work, he said. “There are some new fledging offerings that are trying to start with the containers and say ‘We’re solving this by providing this abstraction,'” he continued. “Well, if you don’t deal with the root complexity, eventually your solution is going to break on the basis of that complexity. And as you add more connections and more and more data, that becomes more and more problematic, and somebody has to figure out how that works.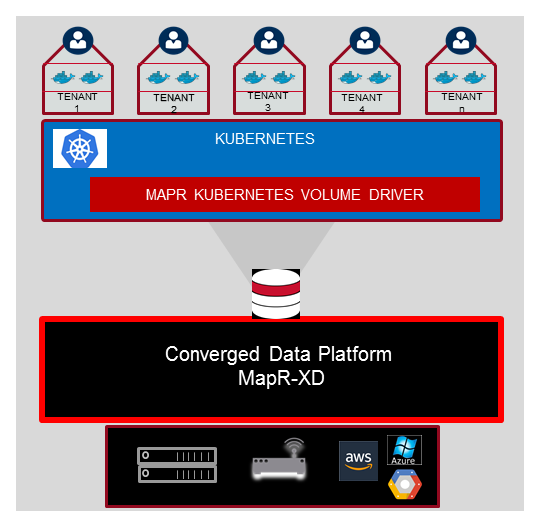
“What we’ve really done is address the drivers of that complexity with our underlying data fabric so that that access can be so straightforward and so simple and easy to integrate into that environment.”
This isn’t MapR’s first foray into containerization. It offered support for Docker containers in a previous release. But the call for Kubernetes has grown so great in recent months that it was obvious what MapR needed to do.
“Kubernetes is popular among customers mainly because it scales a lot more than Docker,” says Suzy Visvanathan, MapR’s director of product management. “And secondly, the deployment of it is integrated already with the main cloud vendors.”
Amazon Web Services, Microsoft Azure, and Google Cloud Compute already support the running of applications inside of Kubernetes containers. The open source technology, which emerged from Google in 2014, provides the capability for users to spin containers on and off, and scale them up and down as workloads and conditions warrant.
With MapR’s new volume driver, customers can move containerized applications from on-premise to the cloud, and move them around different cloud providers too, the company said. Customers can also run containerized applications on multiple clouds and be ensured that the data is being properly synchronized among them.
The big caveat to containerization technology has been the persistency of stored data. When compute containers are created or eliminated, the data needs to be stored in a persistent state. Supporting the Kubernetes volume driver allows MapR customers to sleep well at night knowing their data is safe, the company said.
“Stateful and data-driven applications can’t elegantly live in the cloud without an elegant means for persisting state and making it available, securely and robustly, to containerized microservices,” said James Kobielus, lead analyst at SiliconANGLE Wikibon and a Datanami columnist. “We’re impressed with how MapR has addressed these challenges for stateful containers that run in big-data clusters that have deployed Kubernetes.”
MapR has four customers who are running the Kubernetes volume driver and are nearing production. The customers include a telecommunications firm that’s looking to better utilize their information flows in a real-time application. There’s a medical equipment manufacturer that’s using Kubernetes in MapR to coordinate edge processing with cloud and on-premise compute resources. And MapR also has an insurance company that’s looking to use containers to maintain selective data access in a multi-tenant environment.
By doing the hard work of integrating Kubernetes at the lowest level in its data fabric, MapR is confident that customers are ready to move forward with Kubernetes in demanding production environments, Norris said.
“It’s one thing to work on a POC [proof of concept] or limited basis,” he said. “But when you look at how is this going to work at scale? That’s where big question marks are. Because before I start on this, the last thing I want to do is run into problems [at scale] and now I’ve added data coordination and data flows to access, and it’s a dead end. Those are big deals.
“The beauty about approaching this from where we sit,” Norris continued, “is we’ve got legacy applications at scale running today, and now we have customer who are already proving containerization access running at scale in real time today.”
Kubernetes support is delivered in the MapR Data Fabric, called MapR XD.
Related Items:
MapR-DB Gets Secondary Indexes to Drive Operational Analytics
MapR Takes Aim at DataOps with Platform 6.0
MapR Rebrands Around Converged Data Fabric
Applications:
Enterprise Analytics
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States