

February 20, 2018
Why Getting the Metrics Right Is So Important in Machine Learning

(Barbol/Shutterstock)
Armed with big data analytics, businesses now have the power to detect and act in very precise ways. But if a business is measuring the wrong piece of data — or measuring the right piece of data in the wrong way – then any machine learning models built on those metrics can lead the business astray.
There are all sorts of cognitive traps just waiting to swallow up unsuspecting big data practitioners. There’s the danger of group think, where safety is presumed to exist by doing what many other do. There’s loss aversion, which is the tendency to favor inactivity over activity. And of course there’s the infamous data snooping bias, where humans tend to see patterns in random plots of data.
Sometimes the world behaves in bizarre ways that run counter to our assumptions of how cause and effect work. Scott Clark, the founder and CEO of SigOpt, recalls a paper from Microsoft Research several years ago that made a counter-intuitive discovery about the connection between search results and ad revenue:
The worse the search results returned by the Bing search engine, the researchers concluded, the higher the ultimate ad revenue. This makes sense when you consider that poor results will drive people to keep searching, providing the search engine with more chances to show advertisements.
“But obviously, that’s a terrible long-term strategy and it would lead to worse revenue over the life of the product,” said Clark, who built machine learning systems for the Yelp advertising team before founding SigOpt several years ago.
“Naively, you’d think of an advertising system as, you just want to make as much money as possible,” he said. “But it’s all about doing that in a sustainable way, in a way that continues to make your customers happy and provides value to the platform as a whole.”
The experiences led Clark to a conclusion that he’s carried forward in his work at SigOpt: Choosing the right thing to measure and getting the right metrics in place are extremely critical to succeeding with machine learning systems.
However, it’s also an area where people are quite prone to making mistakes. As they get further along in their machine learning projects, and perhaps start employing more sophisticated techniques to tune the machine to achieve some goal (which is the business that SigOpt is in), those early errors can come back to haunt you.
“Tuning toward the wrong thing can actually make it look like you’re doing your job right,” Clark told Datanami. “But in reality, you’re actually making things worse.”
ROC Fall
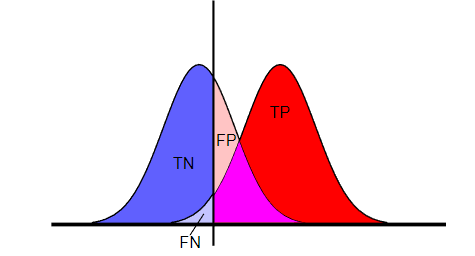
ROC curves can be useful, but they must be carefully adapted to fit the business
Clark surmises that one of the drivers that leads us to measure the wrong thing stems from academia, and the tendency to take a pure mathematical approach.
It’s very tempting to use mathematical measurements like accuracy, area under the ROC curve, or logarithmic computations as the metric defining success in a machine learning model. But using these techniques is not necessarily the best approach in the business world, Clark said.
“These have great mathematical properties and they’re very easy to derive specific statistics off of or prove specific convergence properties,” said Clark, who has a PhD in Applied Mathematics from Cornell University. “But at the end of day, when things are actually applied in real world, you’re trying to solve a business problem, and sometimes these things are correlated…But they’re not always correlated, and sometimes [they’re correlated] in very non-intuitive ways.”
To keep your machine learning models from going off the rails further down the line – like when SigOpt’s “black box” optimizer is used — Clark stressed the importance of taking the time to ensure the metric that’s being used in the machine learning model is a good match for the business outcome.
“This is the most important thing,” he said. “This is the measuring stick to tell whether or not your efforts or investments are bearing fruit. I contend this is something you should do before you even start playing around [with optimizers] because, if you don’t know how to measure yourself, you don’t know if you’re making progress or if you don’t know if you’re regressing as well.”
GIGO’s Revenge
This is something that Bill Schmarzo, the chief technology officer of the Big Data Practice of EMC Global Services, sees becoming more important as companies look to embrace artificial intelligence technologies.

(Kheng Guan Toh/Shutterstock)
“One of my good friends who’s a statistician keeps talking to me about sample size errors and representative populations,” said Schmarzo, who also teaches a course on big data at the University of San Francisco. “Yes, we have all this data out there. But the problem is that that data comes with all kinds of biases built into it that need to be cleaned out.”
Schmarzo sees a big potential for folks working on Internet of Things (IoT) projects to make the same types of mistakes that plagued many early big data projects. Instead of thinking the whole project through and taking a methodical approach to data collection, metric selection, and analytic-driven decision making, Schmarzo told Datanami last month that people will rush to get an IoT project up and running, place too much value on technology, and wind up with a hard-to-manage model that’s of dubious business value.
“I think in 2017 we started seeing some of the indicators that the AI metrics aren’t very good, especially if you don’t consider the data that goes into them,” the Dean of Big Data said. “There will probably be a hard reality crash in 2018 if people don’t realize that ‘garbage in, garbage out’ is more true than ever.”
Custom Metrics
For a machine learning model to be truly impactful, it will most often need to be customized to the user’s specific business. The metrics that determine success or failure – such as customer retention rate, conversion rate, market share, or any other metrics that determine how well a business is doing — must be tweaked and adapted too.

Careful consideration of business metrics will help align machine models with business goals (NicoElNino/Shutterstock)
“This is something that requires a lot of domain expertise and application awareness,” Clark said. “Obviously each ad product is different, each fraud product is different, each algorithmic trading strategy is different, so this is something where the domain expertise makes a big difference.”
Organizations should be wary of using metrics that came straight out of academia, he said. “Tools that are only built to solve academic problems or to only optimize toward very specific metric…are going to be less effective than things that can attack these business problems directly.”
Making sure you’re feeding your model with the right data is just as important as making sure you’re getting the right metrics out, Clark said. This is where the expertise of the data scientists and their specific capabilities as data modeling and business experts gives them a unique advantage to build a virtuous data science cycle.
“I think data scientists and people with that domain expertise for the specific application are in a unique perceptive to try out different things, to really understand and model long-term customer value, to make sure that whatever custom metric they’re coming up with fits the business application at hand,” Clark said.
Related Items:
The Role of Bias In Big Data: A Slippery Slope
From Blackjack to Big Data – The Importance of Avoiding Cognitive Bias
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States