

February 1, 2018
Ray’s New Library Targets High Speed Reinforcement Learning

via Shutterstock
Data scientists looking to push the ball forward in the field of reinforcement learning may want to check out RLlib, a new library released as open source last month by researchers affiliated with RISELab. According to researchers, the goal of RLlib is to enable users to break down the various components that go into a reinforcement learning, thereby making them more scalable, easier to integrate, and easier to resuse.
Reinforcement learning is a type of supervised learning that’s gaining popularity as a way to quickly train programs to perform tasks optimally in a world awash in less-than-optimal training data. Instead of training a model with pristine data, which is ideal in supervised learning, the reinforcement learning model learns from the data environment as it naturally exists, and uses a simple feedback mechanism (the reinforcement signal) to nudge the model towards the ideal solution.
The practical advantage of the reinforcement approach is that it seeks to achieve a balance between being able to interpret uncharted data (which is where unsupervised learning algorithms flourish) and exploiting existing knowledge (where supervised learning typically excels). When this balance is achieved, the runtime performance of the model can be optimized, at least for a specific context.
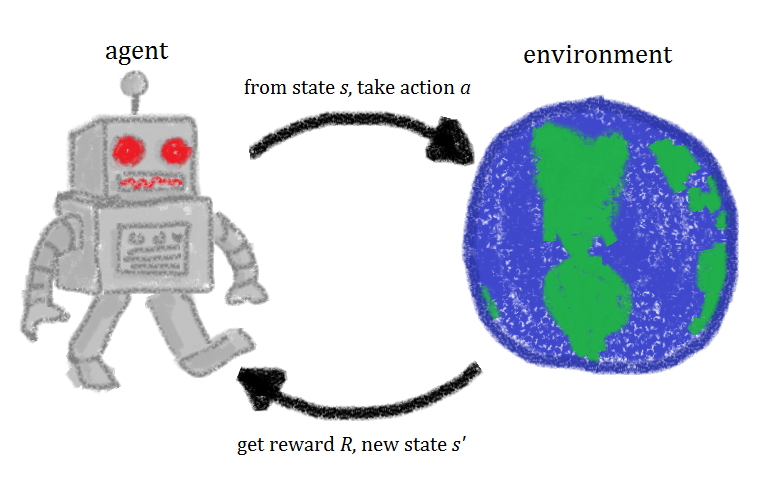
Reinforcement learning hinges on the delivery of a reward signal (Image courtesy Notfruit/Wikimedia Commons)
According to the RLlib page on the Ray website, RLlib seeks to provide a scalable framework for building reinforcement models that are both performant and composable.
Here’s how the researchers behind Ray RLib describe their work in a paper that was published last month in the Cornell University Library:
“Reinforcement learning (RL) algorithms involve the deep nesting of distinct components, where each component typically exhibits opportunities for distributed computation. Current RL libraries offer parallelism at the level of the entire program, coupling all the components together and making existing implementations difficult to extend, combine, and reuse. We argue for building composable RL components by encapsulating parallelism and resource requirements within individual components, which can be achieved by building on top of a flexible task-based programming model. We demonstrate this principle by building Ray RLlib on top of Ray and show that we can implement a wide range of state-of-the-art algorithms by composing and reusing a handful of standard components. This composability does not come at the cost of performance — in our experiments, RLlib matches or exceeds the performance of highly optimized reference implementations”
The RLlib software runs atop Ray, the distributed execution framework from RISELab that director Michael Jordan last year said could displace Apache Spark. RLlib is the second library within the Ray project. The first was Ray Tune, a hyperparameter optimization framework for tuning neural networks.
RLlib integrates with Ray Tune, and its APIs support TensorFlow and PyTorch. The library incorporates a series of algorithms, including Proximal Policy Optimization (PPO), the Asynchronous Advantage Actor-Critic (A3C), and Deep Q Networks (DQN).
Ray runs on Ubuntu, Mac OX X, and Docker. It can also be used with GPUs. You can find downloads for Ray, Ray RLlib, and Ray Tune at this GitHub page.
Related Items:
Meet Ray, the Real-Time Machine-Learning Replacement for Spark
The Next Data Revolution: Intelligent Real-Time Decisions
RISELab Replaces AMPLab with Secure, Real-Time Focus
Leading Solution Providers









Tabor Network
Sponsored Multimedia








{kind=link}
Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States