

January 10, 2018
Wrestling Data Chaos in Object Storage

(Andrey_Popov/Shutterstock)
It has become all so apparent that object storage is the cornerstone of the cloud and the resting place for just about any aspect of business, industry, and government data. While the simplicity of the object approach lends itself to swift adoption and scalability, the data architecture surrounding cloud-based object stores has become more complex in order to handle traditional tasks.
Most companies under the sun are using it to store and retrieve their essential data. Whether they’re in financial services, healthcare, energy, biotech, telecom, automotive, manufacturing, entertainment, or social media (the list goes on), they are all generating traditionally structured — and now a tsunami of new semi-structured and unstructured data types. Object storage has become a natural place to both collect and disseminate such diverse and disjointed information ‒ and is proving to be the best choice because of its simplistic, elastic, and cost efficient characteristics.
Today, it is hard to imagine a storage or cloud provider not including object storage as a primary offering. Back in 2006, Amazon AWS inauguration began with S3 (Simple Storage Service) and to everyone’s surprise (including Amazon) – it was a hit. A huge hit. It has become so popular that if any part of S3 goes down (e.g. east-1) for just a moment, the Internet virtually stops. And with the explosive growth of data today, the use of S3 also continues to grow.
Object Storage Challenges
The success of object storage is based on its ability to store anything and everything. Whether the data is structured, semi-structured, or unstructured, object storage is more than capable. Yet, this ability to store such diverse and disjointed data types, is also causing a problem.
The challenge begins with it “not” requiring fixed structure upfront. Sure, object storage allows objects to be tagged with descriptive labels, but this is a far cry from a cataloging and schema-based storage such as a relational database. The blend of storing and retrieving data of any type and format, from anywhere, is a major reason for adopting object storage as a significant repository. The benefits are self-evident. The dilemma arises in the inability to discern the relationship between objects as well as the actual type and format. All things considered, object storage can get messy very quickly.

(Bedrin/Shutterstock)
In the case of backup/restore or software delivery requirements, which were the first major use cases, object storage worked extremely well for archiving and deployment due to the ability tag and version content. The power to put in and get out arbitrary data of any size or scale in a web-based and durable fashion, is the object storage advantage. However, since then, object storage has come to encompass more varied use-cases and sources, such as system, application and machine-generated statistical and operational content. This is all content that was traditionally stored in databases. The migration from database storage to object storage has many reasons, but the following are the key benefits:
- Basic and Simple: no upfront structuring, web-based interface
- Scalable and Elastic: no limit to amount stored, no provisioning
- Cost-effective and Durability: no-frills/low-cost, built-in redundancy
The Complexity of AWS Data Architecture
These benefits are so unique that database features and functions were sacrificed and managed externally. As a result, the current state-of-the-art offerings with respects to wrestling data chaos in object storage is to add in independent, unrelated services to catalog, transform, and analyze object storage content. In an ironic twist of fate, the chaos of object storage has been replaced with chaos of data architecture. As object storage repositories increase in size and importance, the need for more complex data architecture dramatically increases to fill in the blanks. For instance:
- Content cataloging has been outsourced to solutions such as SQL (e.g. RDS), NoSQL (e.g. DynamoDB), or Text Search (e.g. Elasticsearch).
- Content analysis requires data to be moved again for further structured through an Extract, Transform, and Load (ETL) process.
- ETL processing moves this new content from object storage into schema based analytic solutions such as data warehousing (e.g. Redshift).
- When ETL processing is at scale, big data scaffolding is erected such as Hadoop and Spark (e.g. EMR) to either transform content or directly analyze.
In another twist of fate, the content derived from the analysis is typically put right back into object storage where the content originally came from.
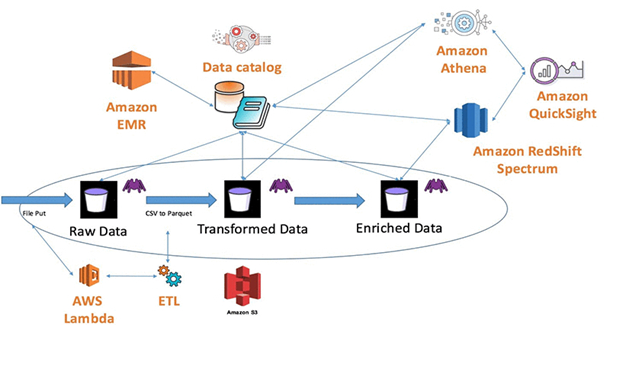
Figure 1 – Amazon Data Lake Reference Architecture
In the above description, Amazon services are used to outline a reference data architecture to wrestle the data chaos of object storage. What is missing are the components required to help trigger the flow of information from one service to another (e.g. Lambda). Each aspect of the design and architecture requires storage, compute, and network resources, that not only increases complexity, but cost. This requires that an organization has the financial means to build and support such a solution and the ability to hire extremely skilled workforce. The typically AWS architecture (See diagram below) outlines services and flow of a data lake implementation.
From Data Chaos to Order
As one can see, decluttering the current state of object storage has led to another obligation to declutter the associated architecture. In a way, object storage has removed the initial issues of ‘schema on write’ complexity and moved it to ‘schema on read’ complexity. However, the object storage story doesn’t end here. The next chapter is to take what works and remove what does not.
Like in any technology, object storage is evolving. Object storage has changed since its inception at Carnegie Mellon University (CMU) in 1996. Even Amazon S3 has notably diverged from CMU’s initial proposal. With the trend of democratization of data analytics, driven by data analyst and scientists, one can assume object storage will continue to evolve and get smarter.
The Future of Object Storage
As data demands continue to evolve and increase in complexity, organizations need to start demanding more intelligence that is integrated in their object storage. Simply building better data scaffolding will not take data science to the next level for any organization. Wrestling with data disorder in object storage traditionally required complex architectures, but the next generation of more capable object storage solutions will open the door to self-service data analytics ‒ for anyone, by anyone. Storage and cloud providers that embrace this thinking will lead the next generation of data management and related services.
About the author: Thomas Hazel is Founder, CTO, and Chief Scientist of Chaos Sumo, a cloud service providing Data Lake Unification and Analytics Services on Amazon’s S3. He is a serial entrepreneur at the forefront of communication, virtualization, and database science and technology. Thomas is the author of several popular open source projects and has patented many inventions in the areas of distributed algorithms, virtualization and database science. He holds a Bachelor of Science in Computer Science from University of New Hampshire, and founded both student & professional chapters of the Association for Computing Machinery (ACM).
Related Items:
Cloud In, Hadoop Out as Hot Repository for Big Data
The Top Three Challenges of Moving Data to the Cloud
Data Lake Showdown: Object Store or HDFS?
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States