

December 6, 2017
Embracing the Future – The Push for Data Modernization Today

(Komjomo/Shutterstock)
There is growing recognition that businesses today need to be increasingly ‘data driven’ in order to succeed. Those businesses that can best utilize data are the ones that can better serve their customers, out-compete their competitors and increase their operational efficiency. However, to be data driven, you need to be able to access, manage, distribute and analyze all of your available data while it is still valuable; and to understand and harness new potential data sources.
Key to this is Data Modernization. Data Modernization starts with the recognition that existing systems, architectures and processes may not be sufficient to handle the requirements of a data-driven enterprise, and that new innovative technologies need to be adopted to succeed. While the replacement of legacy technology is not a new phenomenon, the particular sets of pressures, leading to the current wave of modernization, are.
In this article we will delve into the very real pressures pushing enterprises down the path of data modernization, and approaches to achieving this goal in realistic time frames.
Under Pressure
Business leaders world-wide have to balance a number of competing pressures to identify the most appropriate technologies, architectures and processes for their business. While cost is always an issue, this has to be measured against the rewards of innovation, and risks of failure versus the status quo.
This leads to cycles for technology, with early adopters potentially leap-frogging their more conservative counterparts who may not then be able to catch up if they wait for full technological maturity. In recent years, the length of these cycles has been dramatically reduced, and formally solid business models have been disrupted by insightful competitors, or outright newcomers.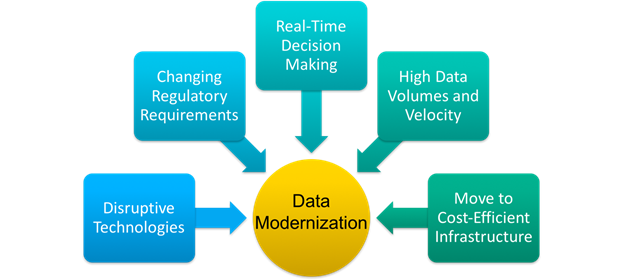
Data Management and Analytics are not immune to this trend, and the increasing importance of data has added to the risk of maintaining the status quo. Business are looking at Data Modernization to solve problems such as:
- How do we move to scalable, cost-efficient infrastructures such as the cloud without disrupting our business processes?
- How do we manage the expected or actual increase in data volume and velocity?
- How do we work in an environment with changing regulatory requirements?
- What will be the impact and use cases for potentially disruptive technologies like AI, Blockchain, Digital Labor, and IoT, and how do we incorporate them?
- How can we reduce the latency of our analytics to provide business insights faster and drive real-time decision making?
It is clear to many that the prevalent and legacy Data Management technologies may not be up to the task of solving these problems, and a new direction is needed to move businesses forward. But the reality is that many existing systems cannot be just ripped out and replaced with shiny new things, without severely impacting operations.
How We Got Here
From the 1980s to the 2000s, databases were the predominant source of enterprise data. The majority of this data came from human entry within applications, web pages, etc. with some automation. Data from many applications was collected and analyzed in Data Warehouses, providing the business with analytics. However, in the last 10 years or so, it was recognized that machine data, logs produced by web servers, networking equipment and other systems, could also provide value. This new unstructured data, with a great amount of variety, needed newer Big Data systems to handle it, and different technologies for analytics.
Both of these waves were driven by the notion that storage was cheap and, with Big Data, almost infinite, whereas CPU and Memory was expensive. Outside of specific industries that required real-time actions – such as equipment automation and algorithmic trading – the notion of truly real-time processing was seen to be out of reach.
However, in the past few years, the industry has been driven to rethink this paradigm. IoT has arrived very rapidly. Connected devices have been around for some time, and industries like manufacturing have been utilizing sensors and automation for years. But it is the consumerization of devices, coupled with the promise of cloud processing, that have really driven the new wave of IoT. And with IoT comes the realization that storage is not infinite, and another processing paradigm is required.
As I outlined in this article, the predicted rate of future data generation – primarily, but not solely, driven by IoT – will massively outpace our ability to store it. And if we can’t store all the data, yet need to extract value from it, we are left to conclude it must be processed in-memory in a streaming fashion. Fortunately, CPU and memory have been become much more affordable, and what was unthinkable 10 years ago, is now possible.
A Streaming Future
Real-time in-memory stream processing of all data, not just IoT, can now be a reality, and should be part of any Data Modernization plans. This does not have to happen overnight, but can be applied use-case-by-use-case without necessitating a rip and replace of existing systems.
The most important step enterprise companies can make today is to move towards a ‘streaming first’ architecture. A Streaming First architecture is one in which at least the collection of all data is performed in a real-time, continuous fashion. Understanding that a company can’t modernize overnight, at least achieving the capability of continuous, real-time data collection enables organizations to integrate with legacy technologies, while reaping the benefits of a modern data infrastructure that can combat the ever-growing business and technology demands within the enterprise.
in which at least the collection of all data is performed in a real-time, continuous fashion. Understanding that a company can’t modernize overnight, at least achieving the capability of continuous, real-time data collection enables organizations to integrate with legacy technologies, while reaping the benefits of a modern data infrastructure that can combat the ever-growing business and technology demands within the enterprise.
In practical terms, this means:
- Using Change Data Capture to turn databases into streams of inserts, updates and deletes;
- Reading from files as they are written to instead of shipping complete logs; and
- Harnessing data from devices and message queues without storing it first.
Once data is being streamed, the solutions to the problems stated previously become more manageable. Database change streams can help keep cloud databases synchronized with on-premise while moving to a hybrid cloud architecture. In-memory edge-processing and analytics can scale to huge data volumes, and be used to extract the information content from data, massively reducing its volume prior to storage. Streaming systems with self-service analytics can be instrumental in remaining nimble, and continuously monitoring systems to ensure regulatory compliance. And new technologies become much easier to integrate if, instead of separate silos and data stores, you have a flexible streaming data distribution mechanism that provides low latency capabilities for real-time insights.
Data Modernization is becoming essential for businesses focused on operational efficiency, customer experience, and gaining a competitive edge. And a ‘streaming first’ architecture is a necessary component of Data Modernization. Collecting and analyzing data in a streaming fashion enables organizations to act on data while it has operational value, as well as storing only the most relevant data. With the data volumes predicted to grow exponentially, a streaming-first architecture is the truly the next evolution in Data Management.
The world operates in real-time, shouldn’t your business as well?
About the author: Steve Wilkes is co-founder and CTO of Striim. Prior to  founding Striim, Steve was the senior director of the Advanced Technology Group at GoldenGate Software, focused on data integration. He continued in this role following the acquisition by Oracle, where he also took the lead for Oracle’s cloud data integration strategy. Earlier in his career, Steve served in senior technology and product roles at The Middleware Company, AltoWeb and Cap Gemini’s Advanced Technology Group. Steve holds a Master of Engineering degree in microelectronics and software engineering from the University of Newcastle-upon-Tyne in the UK.
founding Striim, Steve was the senior director of the Advanced Technology Group at GoldenGate Software, focused on data integration. He continued in this role following the acquisition by Oracle, where he also took the lead for Oracle’s cloud data integration strategy. Earlier in his career, Steve served in senior technology and product roles at The Middleware Company, AltoWeb and Cap Gemini’s Advanced Technology Group. Steve holds a Master of Engineering degree in microelectronics and software engineering from the University of Newcastle-upon-Tyne in the UK.
Related Items:
Streaming Analytics Picks Up Where Hadoop Lakes Leave Off
Streaming Analytics Ready for Prime Time, Forrester Says
Investments in Fast Data Analytics Surge
Technologies:
Middleware
Vendors:
Striim
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States