

November 28, 2017
Cloudera Bringing Impala to AWS Cloud
Apache Impala, the SQL-based analytical database that originated at Cloudera, will soon be available as a managed service on the Amazon Web Services cloud, the Hadoop software distributor announced today at AWS Re:Invent.
Cloudera Altus Analytic DB, as the hosted cloud version of Impala will be known, will be available as a beta service on AWS by the end of the year, with general availability expected in 2018. The company says support for the Microsoft Azure cloud will follow, but no timeline was given.
Impala is one of the most popular engines in Cloudera’s Distribution of Hadoop (CDH), and the open source software is also offered in other Hadoop distributions. The software essentially allows customers to run a host of standard SQL queries against massive stores of relational data stored in Parquet, an optimized Hadoop file format. It’s not the only parallel SQL data warehouse designed to run atop Hadoop, but it is one of the most mature.
Getting customers the capability to run SQL workloads against data hosted in cloud-based object storage repositories was a big priority for Cloudera, says Alex Gutow, a product manager with the Palo Alto, California-based company.
“When we look around at our customers and the types of workloads that are really best suited to take advantage of the agility and cost efficiencies of the cloud, BI and analytics is one of the key workloads,” Gutow tells Datanami.
Specifically, BI workloads running on Impala will benefit tremendously from features customers can find on AWS cloud, such as multi-tenant isolation and workload elasticity, Gutow says. Instead of leaning on in-house administrators to procure computational resources and then manage it for the user on an on-going basis, the Altus Analytic DB service allows customers to lean on Amazon and Cloudera to do that heavy lifting for them, she says.
“So you can have a very specific cluster to run reporting workloads, and you can have another to run ad hoc queries or self-service BI,” Gutow continues. “It allows for much more of that agility, giving all different types of analysts access to shared data very quickly, giving them much more flexibility, and being able to elastically scale up those resources as you need to meet different performance requirements, or to make sure there’s predicable performance for those workloads.”
Altus Analytic DB will access data stored in customers’ Simple Storage Service (S3) accounts. Impala has been able to access data stored in the S3 object store via an HDFS API for about a year, says Greg Rahn, a Cloudera product manager for Impala and Altus. “HDFS provides an API to S3 known as an S3A connector. Impala uses this,” Rahn says. “It looks to Impala as if it’s kind of the HDFS file system, or the abstraction thereof.”
There’s a similar API that exposes data stored in Microsoft’s cloud object store, ALDS, through HDFS, and the company will use that connector when Altus Analytics DB is supported on the Azure cloud in the future. “So at the end of the day, whether the data is in S3 or ALDS or HDFS itself, it all kind of looks the same in terms of the visibly it to impala,” Rahn says.
Cloudera has pre-selected certain Elastic Cloud Compute (EC2) instances that Altus Analytic DB will be allowed to run upon. Customers will be able to spin up Altus Analytic DB clusters with just a few clicks of the mouse, Rahn says.
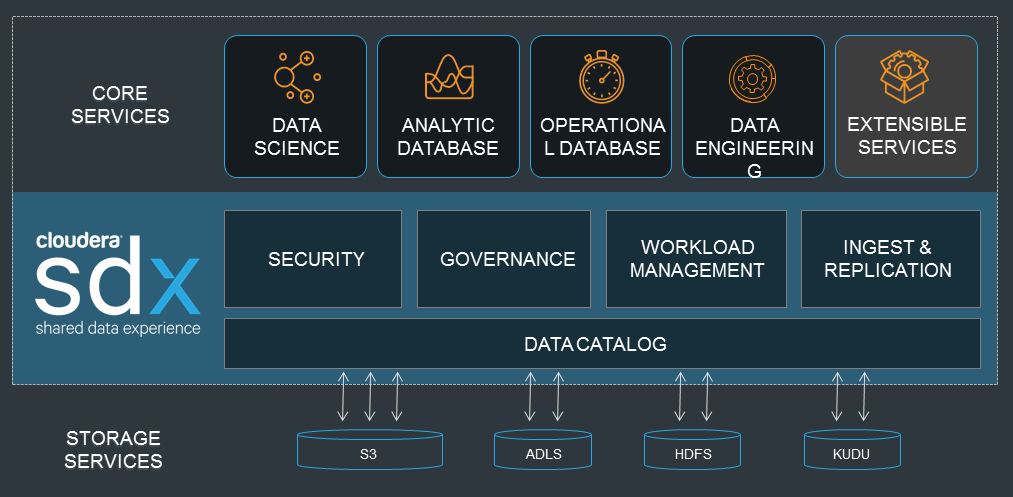
Cloudera is positioning its SDX as a key product uniting customers’ cloud and on-premise Hadoop deployments
“The Altus deployment makes it quite trivial to start up these things, probably on the order of three to four clicks to provision a cluster,” he says. “You log in, name the cluster, pick the size of the instance, the number you want, then you hit ‘create cluster.’ So it’s very simple.”
Customers will be able to quickly spin up analytic clusters on AWS, run a workload, and then quickly dispose of it. None of the data, metadata, or state information for these jobs will be lost when the cloud cluster is deleted because it’s all managed centrally under Cloudera’s Shared Data Experience (SDX), which the company announced at the Strata Data Conference in September.
The SDX provides a way to manage data access and permissions for on-premise and cloud environments from a central console. The software sports hooks into core management tools, including Cloudera Navigator, Cloudera Manager, and Sentry for on-premise implementations and Altus controls for cloud-based environments.
“Not only can you provide these different isolated resources for each of the different workloads,” Gutow explains, “but from the management side of things, these all benefit from having shared security, shared governance, and shared metadata as running actors shared data layer in the cloud, the shared object storage. So each time any of these different workloads are provisioned or run for different self-service workloads, you don’t have to go and redefine the different security policies. You can easily manage them from an enterprise standpoint.”
Altus Analytic DB will be the second hosted offering under the Altus banner since Cloudera announced its new platform as a service (PaaS) in May. The first offering, Altus Data Engineering, was focused on data ingest and transformation tasks, and includes Spark, Hive, Hive on Spark, and MapReduce2 engines.
Cloudera was mum on what engines will come next for Altus. Kudu, its fast-data layer, is one obvious candidate. Cloudera is currently in a quiet period before it announces financial results on December 7.
Related Items:
Cloudera Eyes Uniform Data Experience for All
Cloudera Unveils Altus to Simplify Hadoop in the Cloud
Cloudera IPO Lauded by Big Data Community
Applications:
Enterprise Analytics
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States