

October 25, 2017
Databricks Puts ‘Delta’ at the Confluence of Lakes, Streams, and Warehouses

Databricks today launched a new managed cloud offering called Delta that seeks to combine the advantages of MPP data warehouses, Hadoop data lakes, and streaming data analytics in a unifying platform designed to let users analyze their freshest data without incurring enormous complexity and costs.
Despite their reputations as “legacy” technologies in some circles, traditional MPP-style data warehouses like those from Teradata, HPE, IBM, and Oracle still have a lot to offer enterprises in many respects, according to Databricks Vice President of Product Bharath Gowda, including clean data, transactional support, and solid performance.
“The biggest challenge we hear from customers [regarding data warehouses] is it requires lots of ETL,” he says. “Once you get the data into the data warehouse, things are good. But the process of just getting data into the data warehouse is complicated and tedious.”
When Hadoop started to catch on about seven years ago, enterprises were eager to take advantage of perceived advantages over MPP data warehouses, including greater scalability, cheaper storage, and more open data formats. Certainly many enterprises tried to replace their warehouse with Hadoop running Hive, Impala, and other SQL query engines, but few have made them work, Gowda says.
“They took for granted the problems that data warehouses solved,” he says. “Performance was taken for granted. Data consistency was a huge challenge. And most of the data lakes that we hear of when we talk to customers, they’ve become really inexpensive messy data store with very limited analytics being done.”
Gowda says research by Gartner shows fewer than 15 percent of Hadoop implementations have succeeded. “There were lots of implementation in development, but very few of them have moved to production and actually met the expectations,” he says. “It’s not just that it didn’t address performance challenges. It’s the level of work that needs to happen to pull these things together.”
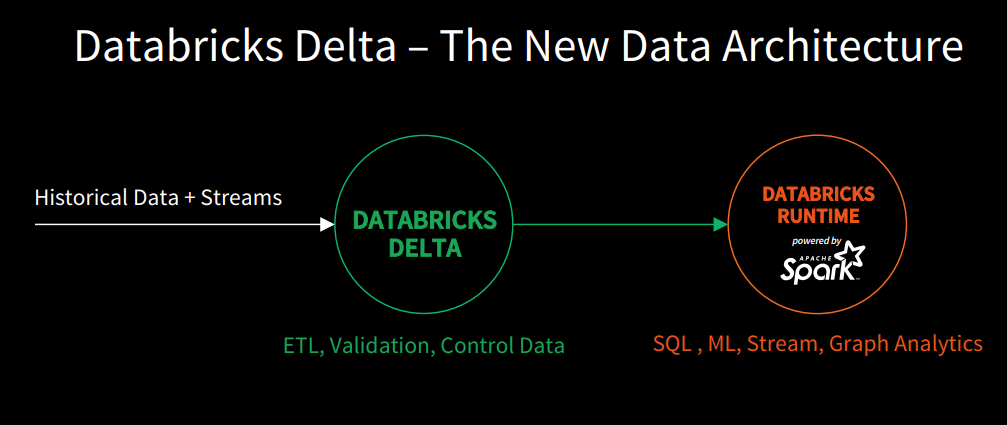
Databricks is positioning Delta as a unified data management system that offers the best of both worlds — the scalability and flexibility of Hadoop and the dependable performance and data consistency of MPP warehouses — with support for streaming analytics and machine learning thrown in to boot.
The offering runs in AWS and utilizes the S3 object store as a fully managed services. As a customers’ data streams in via Kinesis, Kafka, or other streams, Delta runs user-defined transformations written by the user in Scala, Java, Python, or R and accessing the Spark DataFrame API. Once the data is transformed, it’s stored in the Parquet format and made immediately available for SQL style processing, machine learning, and streaming analtyics.
The advantage of Delta stems from the way it handles reads and writes, Gowda says. Regarding writes, Databricks implemented ACID transactions to make sure that multiple writes don’t overwrite each other, and to deal efficiently with failed writes. “We’re saying, customers only have to focus on business logic,” he says. “And when you do a write, we will ensure the write is consistent, that it’s ACID compliant.”
On the read front, the company has implemented a range of techniques like automatic partitioning data skipping, caching, and indexing to automate performance tuning. “That means that you, the data engineer, basically says ‘Here are the columns that I care about, here are the predicates that I usually use in the business’ and then based on those things, we will automated the performance aspect of it,” Gowda says.
![]()
Customers could use Apache Spark running on AWS to build their own type of streaming data pipeline, or they could tap a third-party vendor like Snowflake to build and host a warehouse. But Databricks is gambling that customers will pay to make all the problems go away, thereby allowing them to focus on solving business problems instead of wrangling data and infrastructure.
One such customer is the popular automobile website Edmunds.com, an early Delta user. Having real-time customer and revenue data is very important to Edmunds.com’s business, but complex ETL processes slowed down access to data, according to Greg Rokita, Edmunds.com executive director of technology.
“Databricks Delta allows us to overcome this roadblock by blending the performance of a data warehouse with the scale and cost-efficiency of a data lake,” Rokita says in a press release. “We now have a simplified data architecture that enables immediate access to business-critical data.”
Ali Ghodsi, co-founder and CEO at Databricks, says Delta could finally provide a solution for customer that have struggled with maintaining data lakes and data warehouses, and moving data between them.
“With this unified management system, enterprises now benefit from a simplified data architecture and faster access to relevant data – increasing their ability to make decisions that drive results,” he says in a press release. “We have solved a massive struggle facing organizations that are on a mission to run their business in real-time.”
Related Items:
Hadoop Was Hard to Find at Strata This Week
Hadoop Has Failed Us, Tech Experts Say
Sectors:
Retail
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States