

July 24, 2017
GPU Acceleration Advancing the Evolution of Fast and Big Data

(sakkmesterke/Shutterstock)
With enterprise data warehouses and Hadoop data lakes now well established in the enterprise, organizations are able to store the large amounts of data they are generating, sourcing and curating. Across retail, financial, and healthcare sectors, IT leaders have found that dynamically shifting marketplace characteristics, consumer trends, social sentiment and care delivery efficiency all increasingly depend on performance-sensitive access to priority data feeds. Fast data augments these established information reservoirs by dramatically boosting the organization’s ability to act immediately, as things are happening, thereby maximizing time-to-value for perishable insights.
This article explains how constant advances in data analytics and other technologies have led to today’s highest-performing solution: the in-memory database powered by a graphics processing unit (GPU), which is capable of yielding analytical insights 100-1,000 times faster and at as little as one-tenth the cost of many big data alternatives.
From Transactions to Fast Data: The Evolution of Data Analytics
Data analytics can be considered to have evolved in four distinct phases. The driving forces for each new phase is universally acknowledged to be the relentless growth in the volume and variety, and most recently, the velocity of data.
- Relational Databases have long formed, and continue to form, the foundation for nearly all on-line transaction-processing (OLTP) applications.
- Data Warehouses substantially increased scale and enabled the first Big Data applications, but struggle to accommodate the growth in semi-structured and unstructured data.
- Data Lakes facilitate analysis of all data (structured, semi-structured and unstructured) using both proprietary and open source software running on clusters of commodity servers. This phase made big data more capable, scalable and affordable, but challenges can surface with end user requirements increasingly calling for sub-second query response times for streaming data analytics.
- Fast Data builds on all three prior phases to enable streaming data to be ingested and analyzed simultaneously at the “speed of thought” to satisfy the performance-sensitive needs of users and the scalability demands of the modern data-driven enterprise.
Although data analytics has evolved in identifiable phases, the technologies used have not become obsolete. Indeed, every technology used in the first three phases will largely remain in use across the enterprise. Relational databases and data warehouses continue to be ideal solutions for OLTP and analytical applications involving structured data. Data lakes continue to be cost-effective for ad-hoc queries of today’s volume and variety data, but not its velocity—at least for the perishable data that must be processed in real time.

Streaming analytics act upon fast data
Even when combined, however, the technologies employed in these first three phases continue to strain in the face of relentless and exponential growth in data, much of which is now being accelerated by the significant increase in streaming data. Here are just a few statistics that help quantify the extent of the challenge:
- More data has been generated in the past two years than in the previous entirety of human history
- More data will be generated in the next six months than in all time previously
- In 2010 one data scientist calculated that the world was generating as much data in two days as humanity had generated up through 2003
- By 2020 an average of nearly 2 Megabytes of data will be generated every second for every person on the planet
- By that same year, the total amount of data generated will exceed 40 Zettabytes or 40 trillion Gigabytes—an order of magnitude more than exists today
Perhaps the most shocking statistic is the estimate by industry analysts that less than 1% of all data now being generated is being processed adequately. The reason is the performance bottleneck caused by the lack of computational capacity and not I/O as it was in the first three phases. The evolution to fast data will, therefore, require adding substantially greater computational capacity, and fortunately, the requisite technologies already exist.
1 + 1 = 10
No, this is not a binary equation. Rather, it is an equation that demonstrates the exponential improvement made possible by marrying two separate and proven technologies used to accelerate performance: the in-memory database and the graphics processing unit. Both technologies advanced in parallel and both have now been integrated in data analytics solutions that deliver unprecedented levels of performance.
In-memory databases take advantage of the substantial increase in the amount of Dynamic RAM (DRAM) available in servers. The ability to configure servers with Terabytes (TB) of low-cost DRAM makes the technology viable for many applications, some of which are able to operate entirely within memory. With five orders of magnitude reduction in read/write access latency—from 10 milliseconds for direct-attached storage (DAS) to 100 nanoseconds for DRAM—the improvement in performance is dramatic.
To help fill the performance gap between DAS and DRAM, Intel recently introduced a technology it calls “Memory Drive” that combines the best attributes of both: the low-cost scalability of solid state storage and the high performance of memory. The technology can be used for displacing some DRAM, for fast storage or caching, or as top tier in a shared storage hierarchy. With a latency of 10 microseconds and the ability to configure a server with up to 48 TB of fast storage (vs. a typical 12-16 TB of DRAM), the Memory Drive brings new capabilities to in-memory databases.
These and other technology advances have shifted the performance bottleneck for many data analytics applications from I/O to compute. And that change presents a daunting challenge because, after 50 years of achieving steady gains in price/performance, Moore’s Law has finally run its course for CPUs. The reason is: The number of x86 cores that can be placed cost-effectively on a single chip has simply reached a practical limit.
Yes, there are smaller geometries capable of integrating more and faster cores. But these are so costly to manufacture that while performance does increase, price/performance actually decreases. And yes, x86-based servers and clusters can be scaled up and out to improve performance. But the cost of doing so can be prohibitive, especially when compared to the far more cost-effective alternative afforded by GPUs.
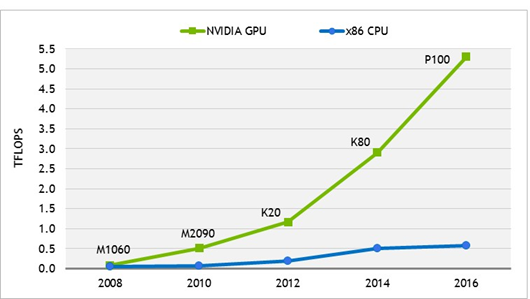
The GPU continues to deliver impressive gains in compute price/performance that far out-pace what is now possible with multi-core x86 CPUs. (Source: NVIDIA)
As the name implies, GPUs were initially used to process graphics. The first-generation of GPUs powered plug-in video interface cards equipped with their own memory (video RAM or VRAM). The configuration was especially popular with gamers who wanted high-quality real-time graphics. Like the CPU, the GPU has advanced in numerous ways over successive generations. One of the most enabling of these has been to make GPUs easier to program, and that is what now makes them suitable for many more applications, including data analytics.
Servers equipped with plug-in GPU cards are capable of processing data up to 100 times faster than configurations containing multiple, multi-core CPUs alone. The reason for such impressive improvement is their massively parallel processing capability, with some GPUs containing nearly 5,000 cores—roughly 200 times more than the 16-32 cores found in today’s more powerful CPUs.
Subsequent generations of these fully programmable GPUs also increased performance by offering faster I/O. For I/O with the server, some solutions deliver a bi-directional throughput of 160 Gigabytes per second (GB/s) between the CPU and GPU, which is 5 times faster than a 16-lane PCIe bus.
The combination of such fast host and VRAM I/O serving several thousand cores enables a GPU card equipped with 16 GB of memory to achieve single-precision performance of over 9 TeraFLOPS (trillions of floating point operations per second). For a GPU-accelerated in-memory database application, that translates into an up to 100X improvement in performance at one-tenth the cost of comparably-performing CPU-only configuration.
Enabling Fast Big Data with GPU Acceleration
The typical GPU-powered in-memory database runs on a commodity server equipped with one or more GPU cards. Both the CPUs and GPUs share in the processing effort, with the latter handling the bulk of the workload. Individual servers can be scaled up with more and faster processors and/or more memory, and servers can be clustered to scale out as needed to achieve the desired performance. For the software, most GPU-based solutions employ open architectures to facilitate integration with virtually any application that stands to benefit from higher and/or more cost-effective performance.
What makes the GPU-accelerated solution different from a CPU-only in-memory database is how it manages the storage and processing of data to deliver peak performance. Data usually resides in system memory in vectorized columns to optimize parallel processing across all available GPUs. The data is then moved as needed to GPU VRAM for all calculations, both mathematical and spatial, with the results then returned to system memory. For smaller data sets and live streams, the data can reside entirely in the GPU’s VRAM to enable faster processing.

While the GPU-accelerated in-memory database stores and process data differently from CPU-only configurations, support for open standards enables it to maintain full compatibility with both open source and proprietary software.
Recognizing that GPU-accelerated in-memory databases are certain to be used in mission-critical applications, many solutions are designed with both high availability and robust security. High availability capabilities can include data replication with automatic failover in clusters, with data integrity being provided by persistence to disk on individual servers. Security provisions can include support for user authentication, and role- and group-based authorization, which help make GPU acceleration suitable for applications that must comply with security regulations, including those requiring personal privacy protections.
Real-World, Real-Time Results
With an open architecture and use of commodity hardware, GPU-powered in-memory databases can be used to improve performance for virtually any data analytics application. In general, the more processing-intensive the application, the greater the benefit.
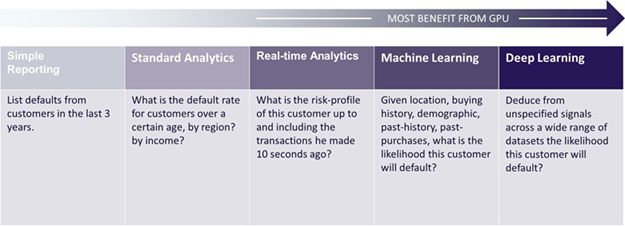
Virtually every data analytics application can benefit from the GPU’s cost-effective performance boost; those requiring the most processing stand to benefit the most.
Here are three examples of results achieved in production applications using GPU acceleration.
The U.S. Army’s Intelligence & Security Command (INSCOM) unit replaced a cluster of 42 servers with a single server running a database purpose-built to leverage the GPU’s power. The application required ingesting over 200 sources of streaming data that together produced some 200 billion records per day.
The U.S. Postal Service uses a GPU-accelerated database to track over 200,000 devices that send location coordinates once per minute. In total, the application ingests and analyzes more than a quarter-billion such events in real time every day.
A retail company was able to replace a 300-node database cluster with a 30-node GPU-accelerated database cluster. Even with only one-tenth the number of nodes, the new cluster delivers a 100-200 times increase in performance for the company’s top 10 most complicated queries.
Conclusion
The marriage of in-memory databases and GPUs is ushering in the era of fast data. The combination delivers breakthrough advances in performance and price/performance just as Moore’s Law is reaching its limits for CPUs. Of equal importance is that the full power and potential of the GPU-powered database is within reach of virtually any organization based on its ability to integrate easily into existing data architectures, and interface with open source, commercial and/or custom data analytics frameworks.
Organizations seeking fast data analytics capabilities can implement a GPU-powered database in a pilot or production application in their own data centers, or go with the cloud where GPU instances are now being offered by Amazon, Google, Microsoft. Either approach presents little or no risk while opening up a whole new era of possibilities.
About the Author: Tom Bianco is Vice President and General Manager of Strategic Accounts at Kinetica. Prior to joining Kinetica, Tom was the Director of National Accounts for Hortonworks, which offers the industry’s only pure-play open source Hadoop platform. Tom also held major account management and international business development positions for Red Hat and EMC.
Related Items:
How GPU-Powered Analytics Improves Mail Delivery for USPS
GPU-Powered Deep Learning Emerges to Carry Big Data Torch Forward
How NVIDIA Is Unlocking the Potential of GPU-Powered Deep Learning
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States