

July 11, 2017
AI Makes Inroads into Enterprise Software

(Aleutie/Shutterstock)
Enterprise software is often maligned as a legacy holdover from a previous age, a low-growth market dominated by stodgy software companies out to milk maintenance streams from hapless victims. But two giants of enterprise software, OpenText and Infor, today showed that even giants can move nimbly when it comes to putting artificial intelligence into the hands of its customers.
Infor‘s big announcement today was Coleman, its new AI platform for its cloud-based enterprise software suites. The ERP giant says Coleman will help Infor clients by recommending actions to take and automating repetitive tasks currently performed by human employees.
“Coleman is our cloud-based AI platform with a collection of industry-specific AI services that harnesses our vast data set and industry knowledge,” Infor co-president Duncan Angove in a keynote address at today’s Inforum conference in New York City. “Coleman brings the power of artificial intelligence and machine learning to the enterprise and it helps you seize the moment by making the best decision every time.”
The new AI platform offers four main capabilities. First it includes a conversational interface, similar to Amazon‘s Alexa and Google Now; in fact it uses the same AI framework as Alexa, Angove says. Second Coleman augments work to make employees more productive, such as by finding answers to simple questions, like “What’s my PTO balance?” and by fetching reports generated by Birst, which Infor just bought. It can also automate some repetitive tasks, such as invoice matching. Lastly it can make recommendations to employees, such as providing next-best actions, similar to Netflix’s movie recommendation system.

“AI is the new UI” Infor co-president Duncan Angove declared today.
Infor, which is the third-largest ERP vendor behind Oracle and SAP and is the accumulation of numerous acquisitions, often touts its expertise in deeply understanding the specific business processes used in various “micro-vertical” segments, such as clothing manufacturing or equipment rentals. The company is now seeking to leverage that micro-vertical expertise by setting Coleman’s machine learning algorithms loose to suck up vast amounts of customer data on the cloud with the goal of fine-tuning its recommendations for all of those micro-verticals.
Angove cited research that says AI bots will replace 40% or more of the work in finance departments by 2020, including “low-complexity, high-volume tasks” like invoice matching, expense report reconciliation, journal reconciliation, evaluation of credit risk for new customers, reconciling deductions in AR, performing inter-company transactions, creating consolidated reports, and closing the books.
Eventually Coleman will do these sorts of tasks across departments, “in every facet of the industries that we serve,” Angove declares. “Coleman frees you up to focus on valid work, relieves you of mundane repetitive low value work that can be perform more efficiency and quickly by an AI with less rework and errors. Plus Coleman works 24 hours, a day seven days a week.”
Angove repeatedly claimed that Coleman was designed “maximize human potential” for its customers, who are mainly corporations. “Coleman is helping maximize human potential by relieving people from low-value repetitive tasks,” he says. “What if you could make the best decision every time? Do the work of two people and be relieved of repetitive transactional tasks that allow you to spend more time with customers or patents or guests or citizens?”

AI features prominently in Infor’s future plans for ERP software
Infor, which built a data science laboratory in Cambridge, Massachusetts profiled in Datanami a year ago, has not fully built out Coleman. Elements of it are available today for predictive inventory management for healthcare, price optimization management for hospitality, and forecasting, assortment planning, and promotion management for retail, the company says.
The new AI platform was named after Katherine Coleman Johnson, the NASA mathematician who calculated orbits during the early days of the space race. Coleman’s life was featured in the 2016 film “Hidden Figures.” Infor also honored two other NASA women featured in the film, including Mary Jackson and Dorothy Vaughan, by naming a lab and another facility after them. Infor CEO Charles Phillips is a big backer of diversity in STEM education; earlier this year, he bought 25,000 tickets to the movie “Hidden Figures” so students could attend free of charge.
OpenText GAs Magellan
As Infor was honoring Coleman and her NASA colleagues, OpenText was honoring another trailblazer from a little further back in history: Ferdinand Magellan.
Today at its Enterprise World conference in Toronto, Canada, the $2 billion provider of enterprise content management (ECM software announced the general availability of Magellan, a new analytics platform that it first unveiled a year ago.

OpenText is a big user of open source with Magellan (from last year’s user conference)
Magellan is designed to help customers identify patterns and pinpoint business opportunities hidden in within vast reams of structured and unstructured data. OpenText combined several open source and propriety software products to create the shrink-wrapped cognitive platform, with the goal of accelerating the big data and AI initiatives in banking, pharmaceuticals, fleet management, public utilities, and governmental agencies.
Specifically, Magellan combines:
- A series of pre-built connectors that pull data from structured sources like relational and NoSQL databases and unstructured sources like server logs and social media;
- Distributions of Apache Hadoop and Apache Spark for storing and processing that data, respectively;
- A layer of proprietary, industry-specific machine learning algorithms developed in Python, Scala, R, and MLlib;
- And a visualization layer based on the BIRT software obtained with its Actuate acquisition.
“We can bring all of that data together, extract metadata intelligence and textual context of these documents, and be able to give you predictive analytics to give you decision-making and automation capability on top of that content that allows you to run your business or run your government better,” says Muhi Majzoub, OpenText’s EVP of engineering.
It’s all about finding common strings within the data that tell the user something about their customers or partners that they didn’t know before. Much of this is an extension of the text analytics that Open Text has been providing for years.
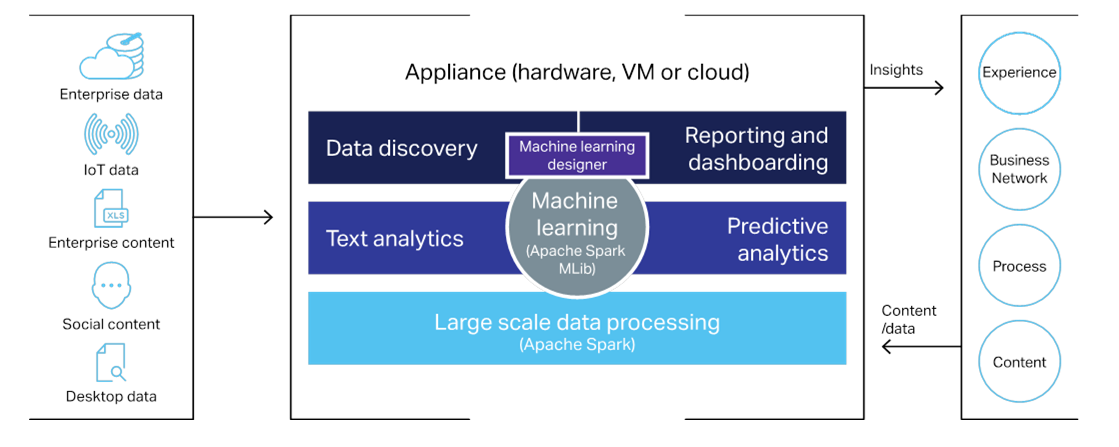
Source: OpenText
“But it can also be transactional data,” Majzoub says. “Our crawlers have access to data sources in ERP and CRM directly through the relational database. So I can go straight into your CRM table that houses all your sales order and then I can link that information to textual data I got from the Wall Street Journal about the health of economies in certain countries and I can predict for you the health of sales in that region or specific country.”
Majzoub says Magellan compares favorably to IBM’s Watson initiative. “IBM Watson runs on the [Power Systems] mainframe. The mainframe is very expensive. We run on X86,” he says. “We’re open source. We don’t own customers’ IP [intellectual property]. When customers develop IP on Watson, they tell you IP is owned by IBM and the Watson division.”
The Hadoop and Spark underpinning provide affordable scalability that customers can count on, Majzoub tells Datanami. “An average bank will collect half a gigabyte to one gigabyte per second in log files,” he says. “This is a massive amount of data. Hadoop and Spark can scale to support it, and we believe it can scale to support it even better than a mainframe.”
Related Items:
Infor Buys Cloud Analytics Vendor Birst
Making ERP Better with Big Data
How Retailers Are Benefiting from Prescriptive Analytics
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States