

June 20, 2017
Cray Brings AI and HPC Together on Flagship Supers

Cray took one more step toward the convergence of big data and high performance computing (HPC) today when it announced that it’s adding a full suite of big data and artificial intelligence software to its top-of-the-line XC Series supercomputers.
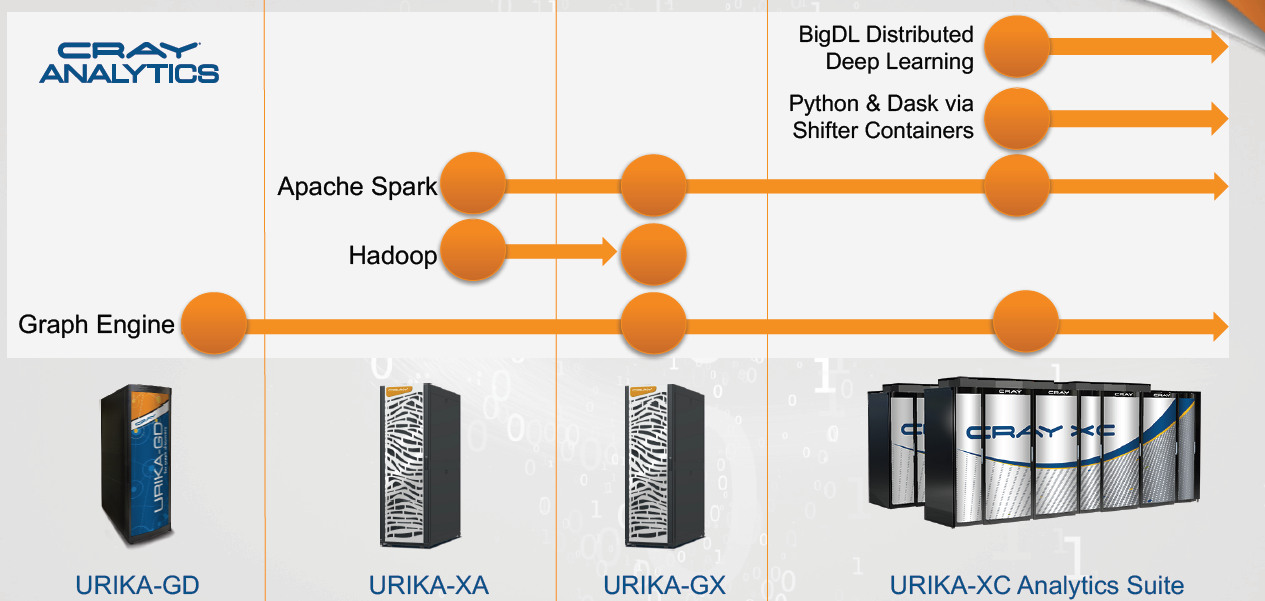
The new Cray Urika-XC analytics software suite will let customers of its XC Series supercomputers access and use Apache Spark in-memory engine, Intel’s BigDL deep learning library, Cray’s Urika graph analytics engine, and an array of Python-based data science tools.
These big data and AI products will run right next to traditional HPC workloads like simulations and modeling, according to Tim Barr, Cray’s director of analytics and artificial intelligence product strategy.
“Our goal here is to provide an integrated hardware and software solution that allows you to run multiple converged workloads on the same platform,” Barr says. “These are traditional HPC simulation workloads and big data analysis and analytics types of workloads, all running on an XC series system.”
Cray’s HPC customers are increasingly looking to use open source data science tools to complement their traditional workloads, and Cray delivered that with the Urika-XC software
“One of the great benefits of this approach is you have access to all of your data from one platform, so there’s no data shuffling or movement of data that tends to really increase the time to analytic result,” Barr tells HPCwire‘s Tiffany Trader. “Just by removing a lot of this data shuffling types of tasks, it can create quite a timesaver with large analytics workloads.”
The Urika-XC software represents an evolution in Cray’s big data analytics offering. First it offered Urika-GD, which focused on graph analytics. Then it delivered the Urika-XA, which was focused on Hadoop. The third generation of Cray big data products was the Urika-GX, which combined graph analytics, Hadoop, and Spark.
As the fourth generation of Cray’s big data product strategy, the Urika-XC software brings deep learning and the Python-based Dask data science library into the fold. Other open source tools, including R, Anaconda, and Maven round out the offering.
Conspicuously absent from this latest offering is Hadoop. The main reason Hadoop and HDFS are not offered is the reliance on local node storage, Barr says. “We’re really focused on large scale in-memory” processing, he says. “I think our approach here reflects that.”
Source: Cray
Cray anticipates the new software being used for both scientific and commercial workloads, including real-time weather forecasting, predictive maintenance, precision medicine, and fraud detection.
One early adopter is he Swiss National Supercomputing Centre (CSCS) in Lugano, Switzerland, which is using Urika-XC with its Cray XC supercomputer nick-named “Piz Daint.”
“Initial performance results and scaling experiments using a subset of applications including Apache Spark and Python have been very promising,” says Professor Dr. Thomas C. Schulthess, director of the CSCS. “We look forward to exploring future extensions of the Cray Urika-XC analytics software suite.”
Cray sees big data and HPC workloads converging in several ways. For starters, traditional HPC researchers are looking to use newer frameworks and techniques that are developed in the open source data science world, says Paul Hahn, group product marketing manager for Cray.
“There’s the notion we’ve spoken about for a while called the convergence of HPC and big data. This is the personification of this,” Hahn says. “Regardless of the domain we’re talking to, the data scientists or the people who are doing the data science work are rapidly crossing over with people who served traditional research…They’re blending the two disciplines.”
The Urika-XC software will make it easier for practitioners to switch back and forth between the big data analytics and traditional HPC approaches, and the tools and frameworks that are associated with them.
For example, Cray sees customers leveraging Spark as a powerful ETL and data preparation tool, which practitioners can use to prep data for simulations. After running the simulations, customers will be able to use other tools to analyze the data. It’s a virtuous cycle.
“We’re starting to see some of the lab researchers develop complex workflows where there’s an analytics piece to it and a simulation piece,” Hahn says. “In weather forecasting, we envision forecast data to be moved into an analytic que using the Python or the Spark suite, and then people running machine learning or analytics against that.”
![]()
Having Intel‘s BigDL framework in place allows users to bring the power of deep learning frameworks, including TensorFlow and Caffe, against large amounts of unstructured data that may be stored. This has the potential to be a game changer for image analysis done in domains like life sciences and oil and gas exploration.
The Urika graph engine, meanwhile, delivers extremely fast analytic results for certain classes of problems involving more refined and structured data. Cray sees Spark being useful for doing the upstream analysis of more raw data that eventually finds its way into the graph engine.
Cray expects to leverage its considerable expertise in building high performance systems to help customers get the most computing bang for their buck with newer big data analytic techniques.
“Building a cluster from a download of open source software…is a really time-consuming process,” Barr says. “A lot of value we bring is you don’t have to have a team go off for several months to build that cluster and try to get it tuned or optimized…We certainly have done a lot of tuning to this analytic stack to make it performant on this platform.”
Not only does Cray’s approach eliminate the need for multiple separate clusters and the latency involved with moving data between them, but it also exposes big data analytic workloads to Cray’s superfast Aries interconnect. Cray considers this an advantage. “A lot of what makes the Cray graph engine incredibly robust and performant is the Aries network that’s part of the Urika-GX as well as XC platform,” Barr says.
The XC series is Cray’s flagship supercomputer, and bringing analytics to this class of machine has the potential to supercharge analytics in ways that weren’t possible. In the Spark ecosystem, the largest clusters are topping out at around 10,000 cores, according to Barr.
“We certainly can scale a lot larger than that and we feel based on our experience in the space, and extensive amount of performance testing, that our current HPC configuration within the XC suite leveraging Aries is ideal to scale out these types of workloads,” he says.
Cray expects to ship the Urika XC software in July. It will be a free download for existing customers.
Related Items:
Bringing Big Data and HPC Together
Cray Bakes Big Data Software Framework Into Urika-GX Analytics Platform
Interview: Cray CEO Sees Big Future in Big Data
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States