

June 13, 2017
Sparse Fourier Transform Gives Stream Processing a Lifeline from the Coming Data Deluge

(Asmus-Koefoed/Shutterstock)
When James Cooley and John Tukey introduced the Fast Fourier transform in 1965, it revolutionized signal processing and set us on course to an array of technological breakthroughs. But today’s overwhelming data sets require a new approach. One of the promising new algorithms is Haitham Hassanieh’s Sparse Fourier transform, which runs up to 1,000 times faster than the Fast Fourier transform and could pave the way to further breakthroughs in data processing.
Cooley and Tukey’s Fast Fourier transform (FFT) represented a major breakthrough that paved the way for many of the electronic conveniences we take for granted today. Without the FFT providing an almost linear-time implementation of Fourier processing, we may not have things like Wi-Fi, GPS, Radar, radio astronomy, medical imaging, and genomics. It’s been a critical core of data processing breakthroughs for decades.
But the initial speed boost that FFT brought to Fourier processing is no longer sufficient to keep up with today’s massive data streams, according to Hassanieh, who created the Sparse Fourier transform (SFT) while working on his doctoral thesis at the Massachusetts Institute of Technology, and received the Association for Computing Machinery (ACM) 2016 Doctoral Dissertation Award for his work.
“Even an almost linear-time algorithm is not good enough,” says Hassanieh, who is now an assistant professor of computer science and electrical engineering at the University of Illinois at Urbana-Champaign. “If you have petabytes or exabytes of data, having an algorithm that goes and looks through every piece of data….just takes too much time.”
While sampling the data is considered bad form in this big data age, it’s actually the secret behind how the SFT works. Hassanieh explains:
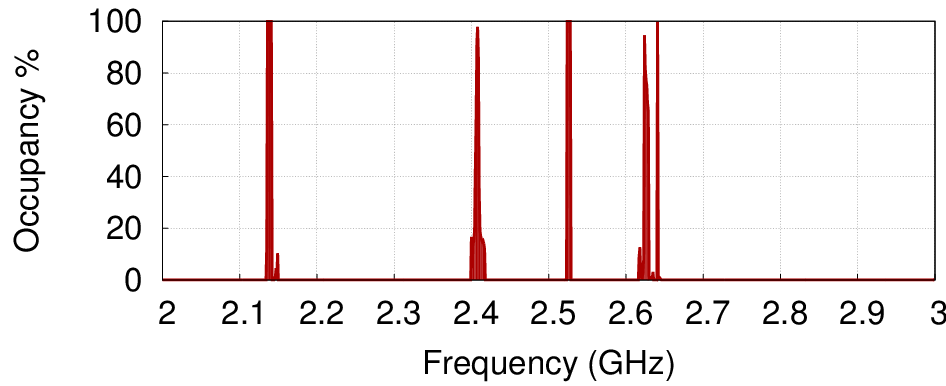
Sparse Fourier transform accelerates processing by essentially ignoring empty spaces in the spectrum of a data signal
“Basically the key insight is that the output of this transform is what we call sparse, which means that most of the output is negligible or zero or a frequency we don’t care about,” Hassanieh says. “If you look at the frequency spectrum, you’ll find that most of the frequencies are not there.”
Instead of using the FFT algorithm to analyze what amounts to a lot of empty space, he decided to come up with a way that essentially skips over those empty spaces.
“It turns out…that for almost all the applications we have, the frequency spectrum is very sparse. Medical imaging, DNA sequencing, etc. It doesn’t have a lot of frequency,” he says. “So we developed an algorithm that, instead of going through all the data, it sub-samples the data and tries to figure out quickly which frequencies are used.”
Computational Trade-Offs
The key, of course, is to sample the spectrum of available data in a way that does not sacrifice too much accuracy. In most cases, the SFT can be used as a drop-in replacement for the FFT. But there are caveats, of course, and there are some applications where the drop-offs in accuracy are significant, including GPS signal processing.

Haitham Hassanieh won the ACM 2016 Doctoral Dissertation Award for his creation of the Sparse Fourier transform
“Because the signals are coming all the way from the satellite, the signals are weak. They end up being 1000x less powerful than the noise in the hardware,” Hassanieh says. “For these applications, in order for us to maintain accuracy, you have to trade off the gains in computation. So instead of 1000x, you get a 2x gain in computation.”
Even the 2x gain is significant because GPS radios consume so much power. But for other applications, like radio astronomy, Hassanieh demonstrated the full 1000x gain in processing speed while maintaining the same accuracy.
While SFT represents a tradeoff in some areas, it opens a door that’s been sealed shut for others. “Do I risk missing something with SFT? Yes,” he admits. “But if I don’t do this, I can’t do anything at all. The nice thing about the algorithm is you can keep sampling more data until you’ve basically collected all the data, and at that point you converge to the original algorithm.”
Converged Inspiration
Hassanieh’s inspiration for the SFT came during, of all things, work on a smart city parking project.
Hassanieh used tricks learned in cellular signal processing to create the Sparse Fourier transform
“We were working on the sensors for the parking project, and we wanted to process the Fourier transforms much faster,” he says. “I had worked on a lot of projects in wireless communications. That was my initial research area. The fact that I worked on both allowed me to realize, Oh there’s all these tricks used in wireless communication that actually can allow us to run this algorithm much faster.”
The standard modulation used today in Wi-Fi and LTE is called Orthogonal Division Multi-Plexing (ODMP). “What ends up happening is when your cell phone transmits data in frequency, not in time,” Hassanieh says. “It’s a subtle thing, but basically with this technique, there are techniques to ensure your transmitter and receiver are synchronized, their phases are aligned.”
Hassanieh basically used that technique, but in reverse, to detect frequencies with data. “I’m going to look at how much the phase changes between the data samples, and I’m going to be able to say, based on that, what frequency this corresponds to,” he says. “If I know how much the phase is changing, I can look back and say, this is the frequency that has the data in it.”
Breakthrough Tech
Hassanieh first described the SFT about five years ago, leading the MIT Technology Review to call it one of the top 10 breakthrough technologies of 2012. The algorithm itself, like the FFT that came before it, is open source and available to anybody who wants to use it.
Hassanieh has spent the past four years working on specific implementations of the SFT, including the including wireless networks, mobile systems, computer graphics, medical imaging, biochemistry and digital circuits.
His work in light field rendering demonstrates that it’s possible to eliminate the need to use an array of cameras or lenses to create a 3D model of a scene. “It allows you to move one camera around, and be able to do the same thing that a full array of cameras can give you,” he says. “This is, again, because you don’t need all the samples. You don’t need each image at each location.”
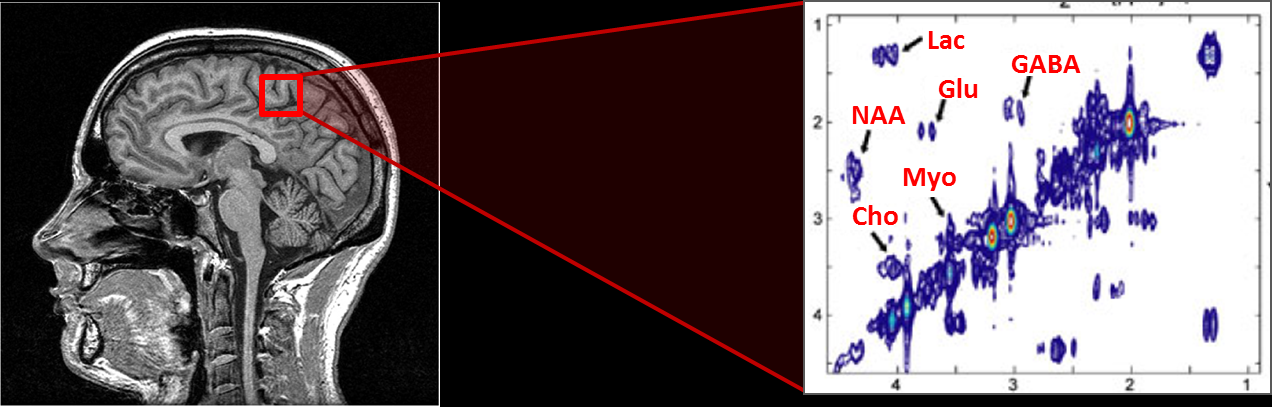
The SFT algorithm can accelerate the identification of features in a biomedical imaging
The public spectrum analysis uses SFT to detect areas of the public radio spectrum that are underutilized, says Hassanieh, who is currently researching technologies that will enable 5G networks. “You can actually build very low power circuits that can look at gigahertz of spectrum at very low power, which is something we could not do before,” he says.
Similarly, SFT in biomedical imaging can dramatically reduce the number of actual pixels captured, reducing the data load significantly without sacrificing quality. Instead of sitting in an MRI machine for three hours, the SFT algorithm can utilize a data sampling approach that reduces the time spent in the machine to 14 minutes. “In fact, we were able to get even better accuracy than by just running a Fourier transform on it,” Hassanieh says. Those specific applications are available for licensing through the MIT Licensing Office.
Looking Forward
Hassanieh sees the SFT having a major impact on the collection and processing of streams of data coming off the Internet of Things (IoT).
“The problem with IoT is you have all these distributed components and your data is spread out. So just collecting all this data and bringing it to one place, and then processing it consumes a whole lot of effort,” he says. “The ability to sub-sample the data from different locations, and the ability to do spatial spectral analysis on it, you can potentially detect security threats or abnormalities much faster.”
Hassanieh says Microsoft and Intel did some research into using the SFT for projects involving voice-enabled devices. “If you have Alexa or Google home, it records your voice, and sends it to the cloud to do the processing to be able to know what you’re saying,” he says. “What [the research] showed is, with our algorithm, you can extract features at low power on the device itself, and then send those features to the cloud.”
Hassanieh is no longer actively works much on SFT applications, but he retains an interest in its use in radio astronomy, and in particular some of the new arrays that are going online. “They’re building this huge telescope to provide images of the sky at huge resolution. The amount of data is bigger than anything we’ve seen. Today, most of the data, if they were to get it, they have to throw it out, because they can’t store it, they can’t process it, they can’t transmit it,” he sys.

New radio telescope arrays threaten to overwhelm scientists’ ability to move it, process it, and store it
“We worked with a group and basically what we showed is can actually process the data seven times faster, 200x faster using SFT,” he says. “That was an important step. They had to build specialized FPGA to process it. But even then, they would have to throw most of it out, because it’s coming at a rate that’s much faster than what they can process.”
As Hassanieh continues to research 5G technologies at the University of Illinois, he looks back fondly on his work on the SFT, and in particular, receiving the ACM 2016 Doctoral Dissertation Award.
“It is a huge honor, to be honest,” he says. “It’s one of the big achievements that not everyone gets. If you look at the list of people who won the award in the past, they all went on to great things. They’ve all become super famous and successful. I’m humbled by the award. But it’s also a statement to the importance of the work and the impact. This is the kind of work that starts from theory then moves to practice and real impact in applications.”
Related Items:
Four Ways to Visualize Big Streaming Data Now
Merging Batch and Stream Processing in a Post Lambda World
Streaming Analytics Picks Up Where Hadoop Lakes Leave Off
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States