

May 31, 2017
How Pandora Uses Kafka

As a big Hadoop user, Pandora Media is no stranger to distributed processing technologies. But when the music streaming service decided to transition its ad tracking system from a batch-oriented system into a real-time one, it brought in a new technological underpinning to serve as the core foundational element.
That technology, of course, is Apache Kafka, which started out as a big data messaging bus but is transforming into a full platform for real-time stream processing of data.
In 2016, Pandora adopted Kafka as a core component of its new stream processing system for processing event data generated by its 24/7 operations and 80 million active users. Pandora software engineer Alexandra Wang recently shared her experience with Kafka in a post on the company’s engineering blog, appropriately named “Algorithm and Blues.”
As Wang explains, Kafka and related technologies, including Kafka Connect and the Schema Registry, were critical to Pandora’s success with the project.
Stream Processing for Music Data
Pandora’s ad trafficking infrastructure was the first use case for Kafka and the Kafka Connect API in production, Wang writes. “Our ad serving infrastructure determines which ad to serve at what time, and it tracks events like impressions, clicks, and engagements,” she says.
The publicly traded media company relies on a “several-thousand node” Hadoop cluster to store user event data collected by the Web servers, for both archival and operational reporting purposes. For reporting, Pandora maintains hundreds of Hive tables, with data stored in the Parquet file format.
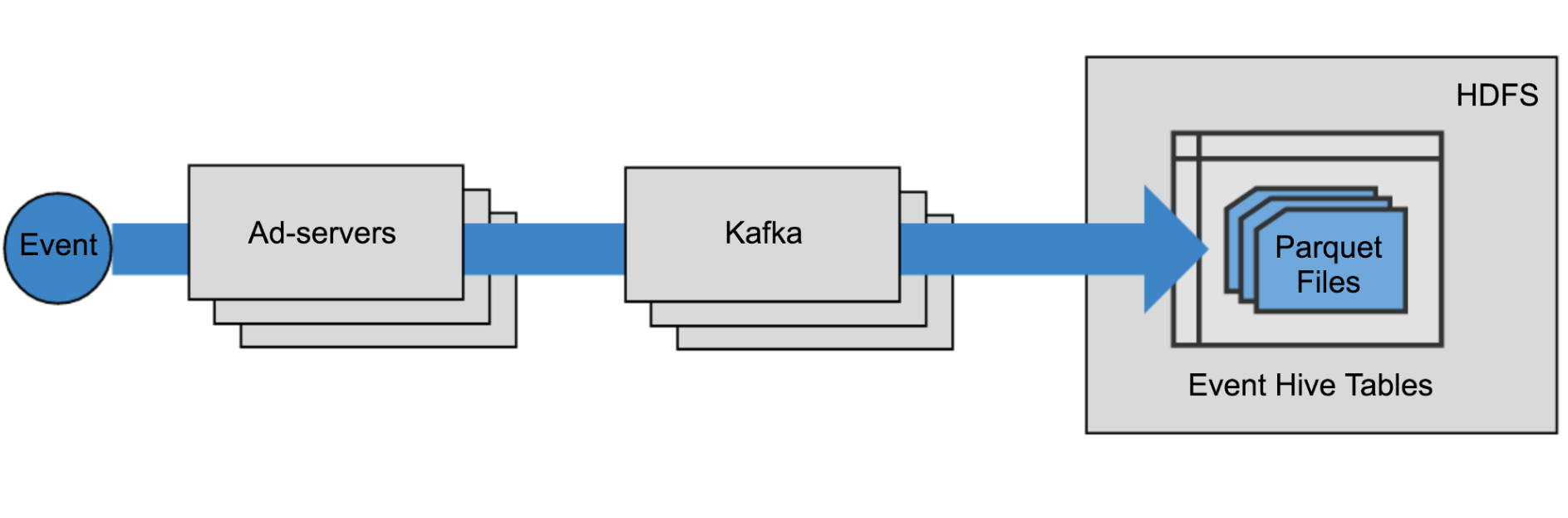
Pandora’s basic data pipeline architecture
This Hive data is critical to Pandora, which gets the bulk of its revenue from advertisers targeting Pandora users, as opposed to customers who subscribe directly to Pandora’s services — and avoid listening to those ads.
Pandora’s aim was to migrate from a batch-oriented log collection architecture to a real-time architecture, using Kafka as the core data pipeline. Getting this batch-to-streaming migration right was extremely important for Pandora, which brought in $1.4 billion in revenue last year, most of it from advertisements.
“There are billions of tracking events per day and since these events are the source of truth for advertising and billing, it is critical that they are reliably stored in HDFS for posterity,” Wang writes. “Our new architecture was designed to support reliable delivery of high volume event streams into HDFS in addition to providing the foundation for real-time event processing applications such as anomaly detection, alerting and so on.”
Out of the Box
As Pandora got into the Kafka project, it concluded that custom coding was not the answer.
“We soon realized that writing a proprietary Kafka consumer able to handle that amount of data with the desired offset management logic would be non-trivial, especially when requiring exactly once-delivery semantics,” the software engineer writes. “We found that the Kafka Connect API paired with the HDFS connector developed by Confluent would be perfect for our use case.”
Kafka Connect is an open source add-on to the core Kafka project that’s designed to make it easy for users to extend Kafka pipelines to other data sources and other data sinks (or targets). The Kafka Connect framework is composed of various source connectors and sink connectors developed by Confluent itself, as well as third-party data management vendors like DataStax, Couchbase, Microsoft, Attunity, IBM, Kinetica, Striim, Syncsort, HPE, SAP, JustOne, and VoltDB.
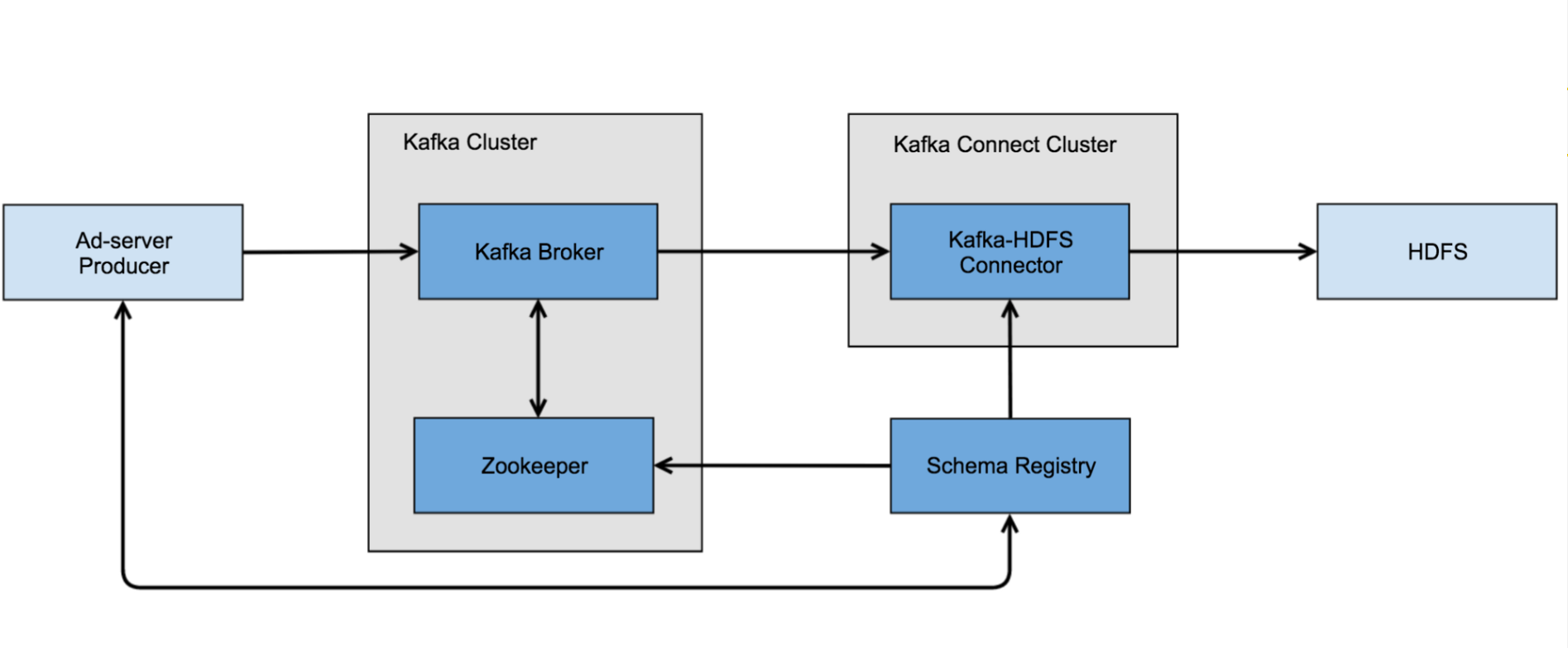
Kafka Connect runs separately from the Kafka cluster at Pandora
Another data-related issue that cropped up in Pandora’s project was schema tracking. Over time, the particular pieces of data that Pandora includes in its log file collections changes. Keeping up with this schema drift presents challenges to the underlying systems designed to move data.
“Without a central registry for message schemas, data serialization and deserialization for a variety of applications are troublesome and the pipeline is fragile when schema evolution happens,” Wang writes.
The solution presented itself in the form of the Schema Registry, a component of Confluent Platform that provides a way to define and enforce Avro schemas as data flows through the Kafka cluster. The service works with Zookeeper and Kafka, and maintains the metadata necessary to recreate the entire history of all schemas.
Pandora created a proprietary Gradle plug-in to help its developers manage message formats and compatibility. A Pandora developer can use the Schema Registry API to validate a schema change, and Gradle serves as the conduit for approving or denying it.
The Schema Registry plays a critical role in data validation in Pandora’s advertising program. “The Ad-server uses the event classes and Schema Registry to validate data before it’s written to the pipeline — ensuring data integrity — and then generates Avro-serialized Kafka messages with the validated schema,” Wang writes.
Kafka Conclusion: It’s ‘Robust’
When it’s all running, the HDFS Sink Connector pulls data from Kafka, and then converts the data into Kafka Connect’s internal data format, with help from the Avro converter and the Schema Registry, before finally writing it as a Parquet file in HDFS, Wang writes. “The connector also writes a write-ahead log [WAL] to a user defined HDFS path to guarantee exactly-once delivery.”
Wang goes into some detail on how Pandora tweaked some Kafka settings to maximize data parallelism and optimize the delivery of data into HDFS. “The goal is to have a file size that’s large enough to be optimal for Hive query performance,” Wang writes, “…while not creating an extensive time interval between each write.” Currently, that means Parquet files that are about 512 MB.
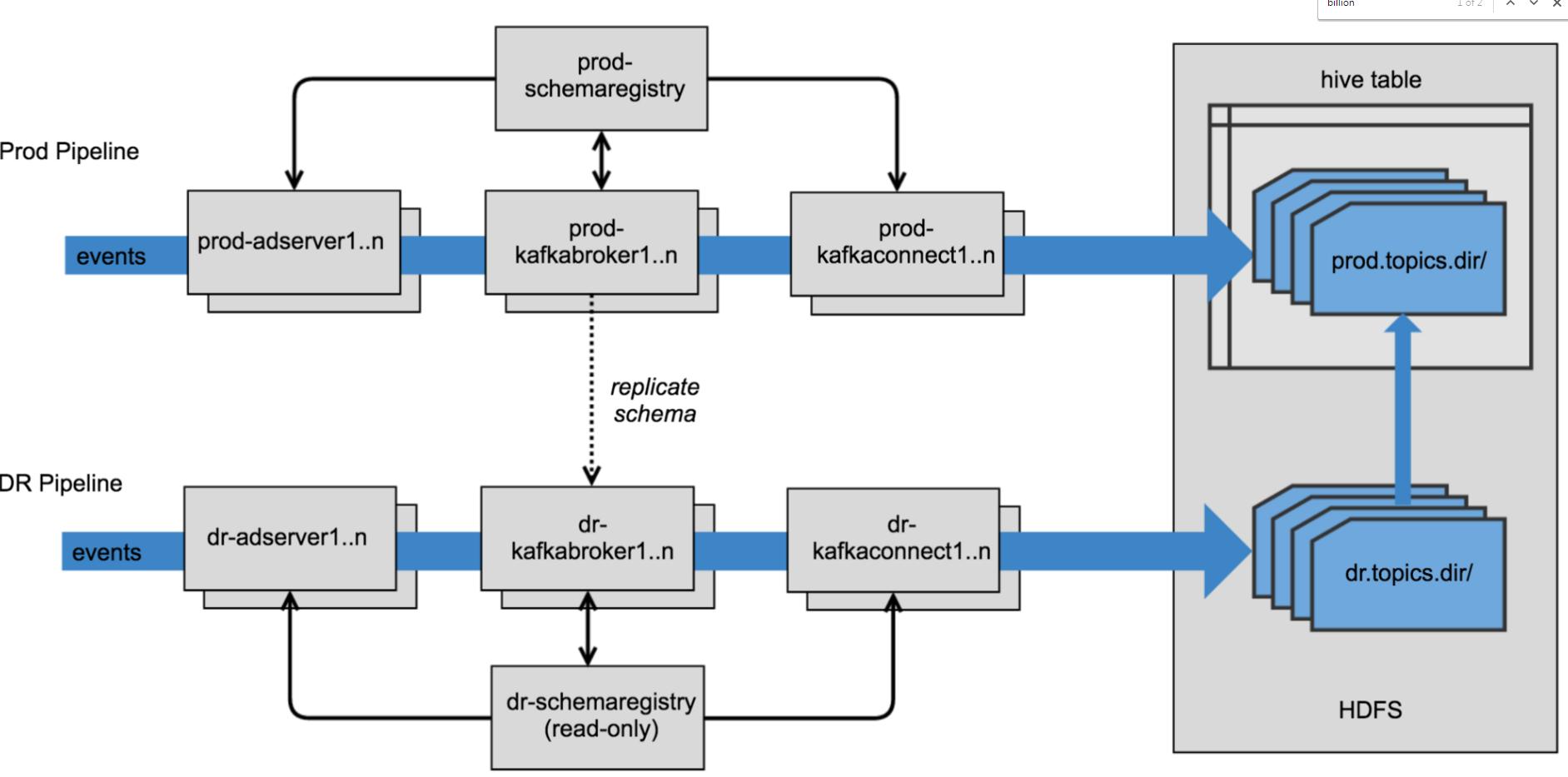
Pandora maintains a duplicate Kafka data pipeline for processing real-time event data
So far, the Kafka Connect cluster is running well with just the HDFS Connector. Pandora has a second Kafka cluster running in parallel for disaster recovery purposes, and the company is monitoring the 32-core Kafka Connect API worker node to ensure that it’s running well.
According to Wang, the node “can achieve the HDFS writing rate of 136,000 messages per second with 75% CPU usage and roughly 225 MBps network inbound.” Latency is guaranteed to be 17 minutes, with 10 minutes as the average, she writes.
“The HDFS connector is very stable in the production environment as long as other components of the pipeline are doing their jobs,” Wang writes. “It adjusts well when scaling the worker nodes in the Kafka Connect cluster, as well as when we dynamically update connector configurations.”
The main concern revolves around downtime of Kafka due to Hadoop maintenance. When the Hadoop cluster is taken offline, Pandora must stop the Kafka Connect connector from consuming data from Kafka. “Otherwise, some of the WAL files will not be closed properly when the network connection between the connector and HDFS is lost, and if a WAL for a topic partition is corrupted, the connector will no longer consume from that topic partition,” Wang writes.
Even though the implementation is not perfect, Pandora is quite happy with the overall solution provided by Kafka, Kafka Connect, and the Registry Schema.
“Despite some minor limitations, we are pleased with the performance of the Confluent HDFS Sink Connector as well as the responsiveness of the community,” Wang writes. “It has greatly reduced our turnaround time, and the pipeline is reusable for our future use cases. With the benefits provided by the Kafka Connect API — mainly making things easier to implement and configure — we’ve already begun to develop more connectors for our other internal systems.”
Related Items:
Kafka ‘Massively Simplifies’ Data Infrastructure, Report Says
How Kafka Redefined Data Processing for the Streaming Age
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States