

May 19, 2017
Google/ASF Tackle Big Computing Trade-Offs with Apache Beam 2.0

Trade-offs are a part of life, in personal matters as well as in computers. You typically cannot have something built quickly, built inexpensively, and built well. Pick two, as your grandfather would tell you. But apparently when you’re Google and you, in concert with the Apache Software Foundation, just delivered a grand unifying theory of programming and processing in the form of Apache Beam 2.0, those old rules may not apply anymore.
Google Software Engineer Daniel Halperin delivered a compelling session on the benefits and capabilities of Apache Beam during this week’s Apache Big Data conference in Miami, Florida. When you consider how many of the major breakthroughs in big data over the past 15 years originated with the Mountain View, California company — the Map-Reduce paper, the Google File System, which morphed into HDFS, and the Bigtable paper, which inspired a hundred NoSQL databases — then you realize it’s probably worth taking notice.
Apache Beam, you will remember, is a unified programming model designed to help developers create data-parallel batch and stream processing pipelines with a single API set. The framework, which is now under the care of the Apache Software Foundation, is designed to efficiently orchestrate workloads that were developed and actually execute in other environments through “runners” out to Spark, Flink, Apex, and Google Cloud Dataflow (with runners for Storm, JStorm, and Gearpump in the works).
As Halperin explains, Google has done a lot of work to ensure that all types of workloads — whether they’re streaming or batch, bounded or unbounded — can be completed in a manner that’s simultaneously fast, complete, and efficient. And with Wednesday’s announcement from the Apache Software Foundation that Apache Beam 2.0 is now ready for production use, it all adds up to something quite interesting for the big data community.
On the Beam
Halperin showed a packed room at the InterContinental Hotel how Beam works within the context of a fairly typical big data workload that many will be familiar with: a JSON log of website activity.

Website data flows into the system in a continuous stream
The goal was to know what users are looking at pages, what pages they’re looking at, and when they’re looking at them. It’s the sort of workload that has commonly been done in a batch style using MapReduce, but which is increasingly moving to stream processing paradigms, via engines like Spark, Flink, and Apex.
As Halperin showed us, you can not only switch between batch and streaming modalities in Apache Beam, but you can switch among different actual runners too. “The key thing you want is fresh and correct results, and you want them at low latency,” Halpersin said. “Or maybe I have data on Hadoop or in files, and here what I want is accurate results, but I don’ need them early.”
The big question is, how can one get these types of results — fast and semi-accurate at some times, or slow and totally accurate at others – without burdening yourself with complicated workflows involving multiple frameworks, languages, clusters, and runtimes. “The industry has a lot of answers for this,” Halperin says. “One of the first ones, the classic ones, is the Lambda architecture.”
Unifying Principles
The Lambda Architecture, developed by Storm creator Nathan Marz, is in widespread use by big firms that put huge demands on their data processing. They would like to have the trifecta of computing – fast, good, and cheap – but they’ve instead had to settle for fast and good, while writing off the complexity and expense of Lambda as a necessary evil. According to Halperin, Beam can let you have your computing cake, and eat it too.
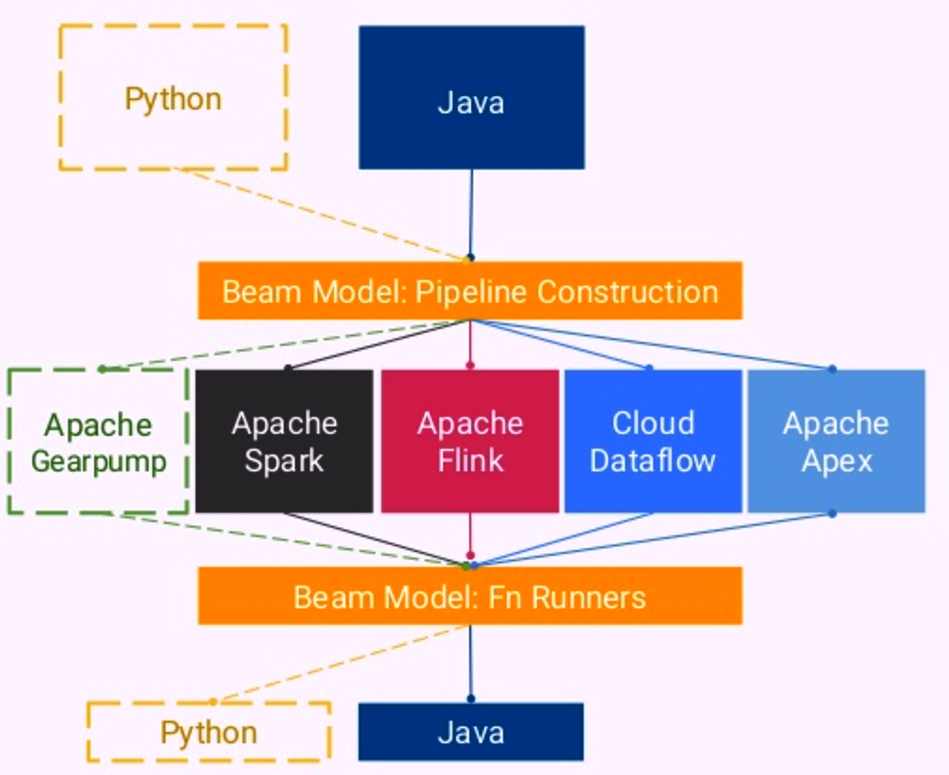
Apache Beam’s Java SDK supports multiple runners; the Python SDK supports only the Google Cloud Dataflow runner at the moment
“Number one, you’re running two different systems” with the Lambda architecture, he said. “Often they’re not even in the same framework. We have people tell us ‘I really like Spark for batch but I really want Flink for streaming.’
“So I have these two pieces, they’re written in different APIs, and I sort of have to keep them in synch,” he continued. “It can be confusing. Sometimes the models don’t line up exactly, and I have to do things in different ways and I have to do a model validation to make sure I get the same results on the same data….The way we deal with completeness is pretty hacky.”
This is a big problem in large-scale data processing, and one that hasn’t been satisfactorily solved. Is Google on the path to solving it with Beam? If Halperin’s presentation is any indication, Google has gotten us a good degree down the road to that point.
According to Halperin, the answer that Apache Beam gives you is pretty simple.
“You write the pipeline once. You change maybe 10 lines of code. And then you supply come command line arguments, and that’s all you have to do to achieve these two different scenarios,” he said. “You can do batch and streaming. You can do Kafka and Hadoop. You can do Flink and Spark. You can do all of these with a few lines of code. You’re not rewriting everything from scratch. You’re not maintaining two copies of everything. And you’re getting sensible results, correct results, even in streaming.”
Time and Primitives
Beam, as it currently stands, has about eight primitives that developers can work with through the SDK, including: Pcollections; sources and readers; ParDo; Group By Keys; SideInputs; Windows; Triggers; State and Timers.
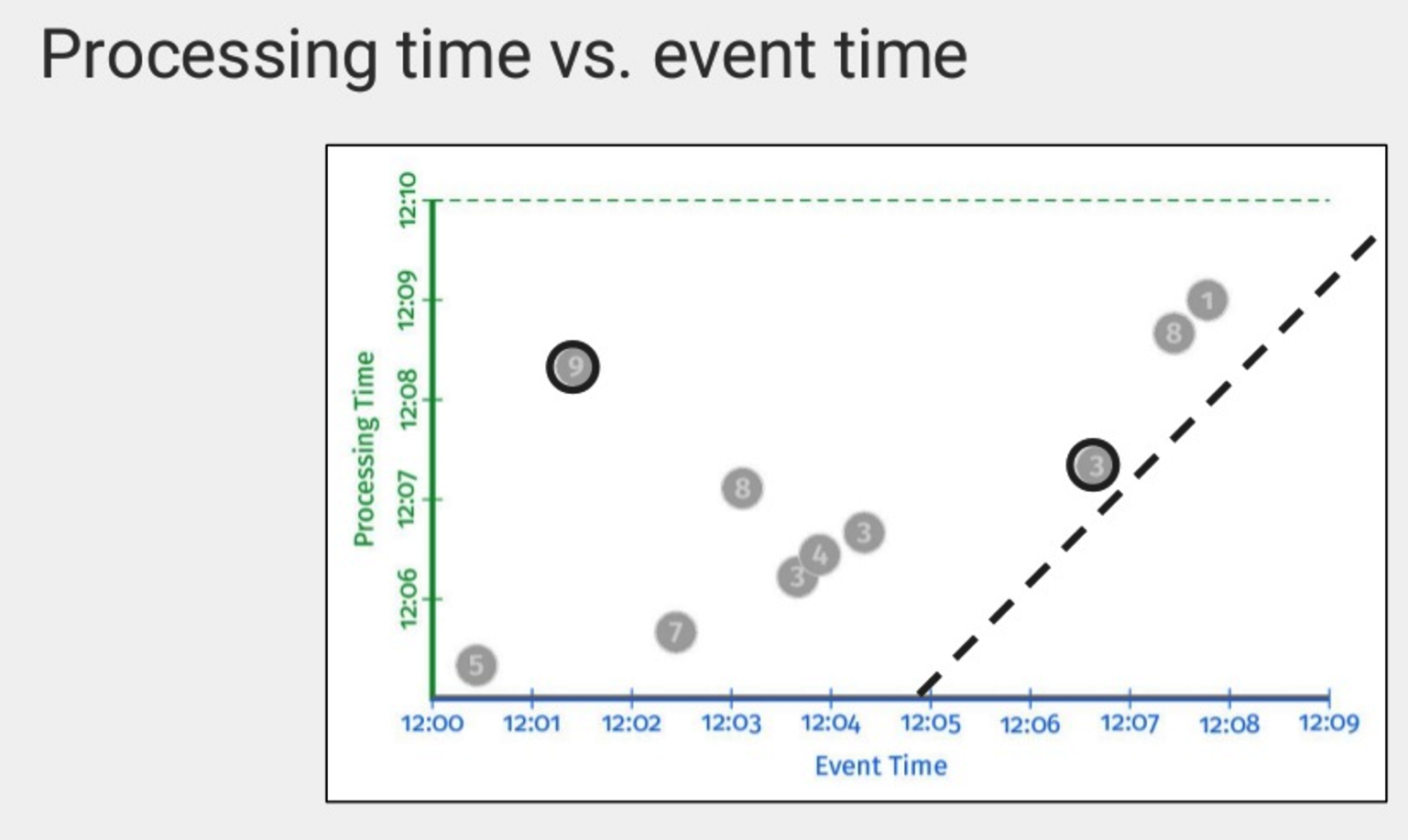
Beam has methods to deal with that pesky data number 9 (in the upper left) coming in late and appearing to be a new session. It’s not; the user was just on the move
Time is a first-class design principle, which is what you would expect in a real real-time system. “Of course you can use classic batch if you don’t care about time,” Halperin says. “We just ignore time sensitive windows. We give them boring defaults. But for most of the exciting stuff, we’re actually going to want this information there.”
In Halperin’s demo, data flows in from a Kafka cluster equipped with some number of topics, or perhaps archive data stored in Hadoop. Once the collection of elements is within Beam, users can work with the commands to process data in different ways. Users can take the elements and compute aggregates from them, or perform joins using other pieces of data. There can be triggers in the workflow to output the state of the data at a certain point in time. There are triggers built in to instruct the business logic to take some actions. And there are window operations galore.
As he explains, Beam does its best to maintain the order of the data flowing in. “They try to read the data roughly in order and they try to estimate how out of order the data is,” he said. “They give you elements with timestamps roughly in order and they give you watermark that says how out of order they are.”
Google added logic to Beam to account for the fact that data rarely arrives in order. “The problem is, if you run ay of these systems, you know that this is not how it works,” he says. “You should not expect your events to come into your system in the same order that they happened. Maybe the user is on Wi-Fi then gets in the elevator, jumps to 3G, then takes a train and gets load balanced between two different replicas with more load and bigger queues that take a different path through the Internet. So your things are going to come in out of order.”

Beam employs a watermark to help reconcile event time and processing time
Beam uses a watermark on each event to enable it to reassemble the correct sequence of events as its being processed by the system. This is handled automatically by the system, via the business logic developed in Spark or Flink or Apex, but orchestrated by the Beam model.
“I want to know they’re paying attention to my site right now. I don’t want to figure it out only when they finished the hour-long sessions. I want to know earlier so I can send them an email to offer a discount,” Halperin said.
Beam has logic built in to enable system to determine how far out of order the events are. “The important thing is there’s lots of different ways you can work with this to get effectively once output, which is really end to end, exactly once output, if the sync and source are supported,” he said.
Efficiency and Auto-Scaling
In addition to ensuring that the data is correct, Beam also some nifty ways to ensure that the results don’t come at an exorbitant processing cost. It does this through logic that automatically identifying slow-running workers and re-assigning the work to other idle workers (or nodes in the cluster). It also has some clever (but not overly clever) response mechanisms to unpredictability.
“Beam is designed from the ground up both to enable runners do what they want to do and have their own execution characteristics, and be efficient at their own discretion,” Halperin said. “What we really want is the user to say ‘Read from this source and let the runner decide.’ So we have very simple APIs for this, but they turn out to be really powerful in practice.”

Beam will preemptively split off workloads from long-running tasks and assign it to idle workers to maintain cluster efficiency
Instead of picking an arbitrary number of mappers to do the work , and splitting up the work in a (hopefully) ideal manner to maximize the resources , as one does in a MapReduce or a Spark implementation, Beam and its runners can interrogate the work and adapt the use of resources on the fly.
“So on a bounded source, you can ask it, how big are you? And then you can say, please split into chunks of a given size,” Halperin said. “Now the runner can go through and say ‘What is the live information on my cluster right now? How utilized is it? Do I have a lot of nodes or do I have spare nodes? What’s the quota? What’s the max amount I’m allowed to use? What’s going to be the bottleneck here? Is it bandwidth? Is it CPU? Is it loading some other clutter? Are there preexisting reservations? And based on the choices I can make a dynamic decision, so 50 is the right number of tasks to use?'”
The system will also determine the number of bundles it uses, which is determined by how much parallelism is left in the data. “The important thing is the user gets no control of bundle size. The runner does,” he said.

Beam will scale up and scale down the cluster in response to changing workloads over time
The use of triggers in Beam — which is how users can get continual updates about the data on a regular basis — also has an impact on throughput in the beam model. As Halperin explained Beam is in control here, too.
“The other knob you get to play with, which I think people find interesting, is triggering,” he said. “The user might say ‘I want updates every minute’ but the runner is actually free to ignore that. What that means is users can set their triggers for really optimistic scenarios. They can say ‘When things are streaming well, I want updates every minute so I can get all my data.’
“But if the pipeline gets backlogged and the runner gets behind, the runner might drop some of the triggers on the floor,” he said. “They’ll keep all the data. They’ll just output it later. So they can trade off freshness and efficiency based on what they think is the best scenario for execution time.”
Beam is designed to scale the number of workers it needs up and down depending on the demand placed on it by the runner and the user. It doesn’t do this through any fancy predictive capabilities, but by looking at basic things (like the number of records remaining to process) and simply responding dynamically to changes in the job and the resources.

Google software engineer Daniel Halperin, who received his PhD. from the University of Washington in 2012, has worked on Beam for two years
“When it comes to efficiency, one of the mantras in Beam is that there really is no amount of upfront heuristic tuning you can do, manual or automatically, that’s good enough here,” Halperin said. “None of it is going to be good enough to guarantee good performance. In practice, your system is always going to have something unpredictable happen at runtime. So what we should do is design systems that are able to adapt dynamically. We want to be able to get out of a bad situations, and that’s much better than having heuristics so we hope we don’t get into a bad one in the first place.”
So if one node on the cluster is having a bad day, or its network card is on the fritz, Beam will adapt to it by reallocating workload to other working nodes as need.
Google shipped Beam 2.0 on Wednesday, meaning this software is free for all to go and use. Beam 2.0 “is the first stable release of beam under the Apache brand,” Halperin said. “We’re really excited that the Beam team has, in the past 15 months, done a huge amount of work to take sort of a fairly chaotic code base and turn it into something that’s truly portable, truly engine agnostic, truly ready for use.”
Related Items:
Apache Beam’s Ambitious Goal: Unify Big Data Development
Google Lauds Outside Influence on Apache Beam
Google Reimagines MapReduce, Launches Dataflow
Applications:
Enterprise Analytics
Technologies:
Middleware
Tags:
Apache Beam, Apex, batch, data pipelines, dataflow, exactly once, Flink, google, Hadoop, Kafka, Lambda, mapreduce, real-time, Spark, storm, stream processing
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States