

April 19, 2017
Inside Anodot’s Anomaly Detection System for Time-Series Data

(Lyu-Hu/Shutterstock)
Time-series data represents one of the most challenging data types for businesses and data scientists. The data sets are often very big, change continuously, and are time-sensitive by nature. One company that’s carving a path through this big data opportunity is Anodot, which focuses on using machine learning techniques to spot anomalies in time-series data, in real time.
Anodot was founded in 2014 when trio of technologists realized there was an unmet need for fast and accurate time-series analysis. The story starts when David Drai, who is now Anodot’s CEO, was helping the ride-sharing company Gett make sense of its data.
As Gett’s CTO, Drai had plenty of data coming in about the business, including the number of drivers in a particular city were active, what kinds of devices the customers were using, how many customers were cancelling rides, and so on. But making sense of these individual business metrics – and especially spotting the unusual activity that signaled a potential business problem – proved difficult.
“He would have BI tools with static reports that he would get every day,” recounts Anodot co-founder and Chief Data Science Officer Ira Cohen, who spoke with Datanami at the recent Strata + Hadoop World show. “He would come in in the morning, look at the report, and notice something. ‘Why was there a drop in Moscow in number of new registrations yesterday?'”
They would often start an investigation, but even if they found the cause, it was usually too late to do anything about it. Sometimes Drai would scan the reports manually in hopes of spotting anomalies hidden in the reports, but it didn’t always work.
“It was just comparing numbers. He would manually do anomaly detection with his eyes,” Cohen says. “But he could do it only on a very limited set of data, and usually very late.”
Getting Timely
Drai, who previously founded a content delivery network bought by Akamai, reached out to Cohen, a PhD-level expert in time-series data who was working in Hewlett-Packard‘s research division, and Shay Lang, an engineer at the cybersecurity firm Trustwave. Before long, the three founded Anodot to build a shrink-wrapped product that could automatically detect anomalies hidden in time-series data using machine learning algorithms.

The three general steps of Anodot’s scheme
The automation of the anomaly detection process is the key aspect of what Anodot does, Cohen explains.
“We look at the data and highlight what’s interesting. We don’t have to guess,” he says. “Instead of having static dashboards, and basically forcing you to ask the question – where you have to think beforehand what might be interesting and you’re limited by your capacity of what you can pursue – we have a system that looks at all the data all the time and highlights to you what’s interesting, automatically. That’s the gist of it.”
While the description is relatively simple – who wouldn’t want a software product that automatically serves up interesting stuff that you haven’t thought to ask yet? – building such a system is not. To uncover anomalies hidden in time-series data, Anodot uses a series of layers of machine learning algorithms and other techniques.
Machine Learning Inside
The first phase involves identifying what “normal” looks like for every set of time series data, or business metric, that gets loaded into the system.
“At Anodot, we look at a vast number of time series data and see a wide variety of data behaviors, many kinds of patterns, and diverse distributions that are inherent to that data,” the company says in its white paper series, Building a Large Scale Machine-Learning Based Anomaly Detection System. “Choosing just one model does not work….”
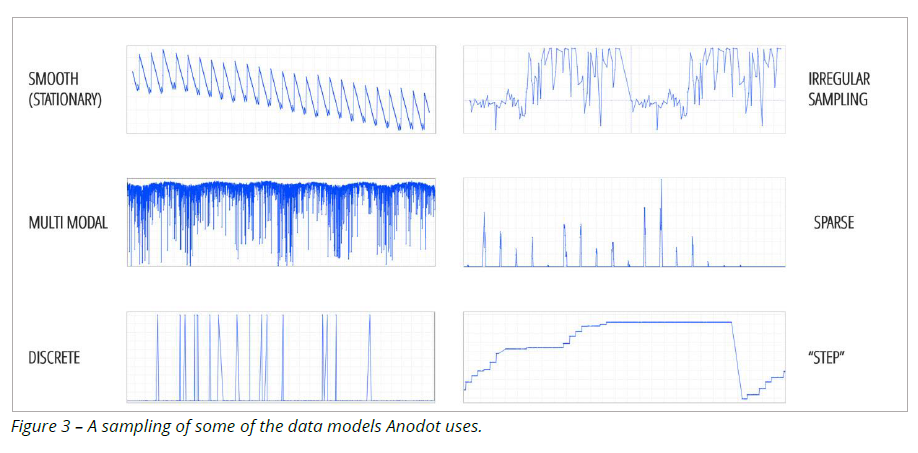
The wide variety of patterns in time-series data requires Anodot to be flexible with its data models
Anodot uses a hybrid method that combines univariate and multivariate anomaly detection techniques, which allows the company to “tune” the models to specific data types (a feature of univariate techniques), but still allows the different models to work together on similar types of data (which is associated with multi-variate techniques). Similarly, it uses semi-supervised learning, which allows the company to leverage the accuracy of supervised learning as well as the ability to spot unusual phenomenon that’s inherent in unsupervised learning.
Anomalies will sometimes surface across multiple groups of time-series data (some customers have millions of metrics they’re tracking). To get a handle on this situation, Anodot uses a modified version of the Latent Dirichlet Allocation (LDA) algorithm. “LDA clusters things in such a way that they can belong to more than one group, i.e. ‘soft’ clustering, as opposed to ‘hard’ clustering,” the company says in its white paper.
All told, Anodot uses about 30 different algorithms in its system, according to Cohen. They’re not all used for each use case – in fact, some of the algorithms are used only to decide which other algorithms should be used. This approach, combined with its behavioral topology learning approach, lets the company focus its customers’ time on only the most anomalous events.
Resetting Normal
Anodot developed its own ways of dealing with peculiarities of time-series data, including the fact that what’s “normal” tends to shift with time, and the ever-troublesome topic of seasonality. According to its white paper, Anodot uses established techniques, like Fourier transforms, to help separate anomalies from regular variations.
The phased approach lets Anodot separate normal from anomalous data
Beyond Fourier, Anodot has incorporated the autocorrelogram (ACF) technique into its system, which correlates the signal with itself at different points in time. ACF has proven more accurate than Fourier, but the drawback is that it’s computationally expensive.
It created its own algorithm called Vivaldi that implements the ACF method but uses sampling to overcome the computational expense and complexity. Anodot has a patent pending on Vivaldi. “The method has been proven to be accurate both theoretically and empirically, while very fast to compute,” the company says in its white paper.
Anodot uses an adaptive learning approach to keep the algorithms tuned to signal on the true anomalies. When Anodot sees anomalies, it adapts the learning rate by giving the anomalous data points a lower weight.
“If the anomaly persists for a long enough time, we begin to apply higher and higher weights until the anomalous data points have a normal weight like any other data point, and then we model to that new state,” the company says in its white paper. Users can also use the “significance slider” to manually adjust the weights.
All this is handled in Anodot’s proprietary cluster, Cohen says. “A data point comes in, it immediately gets compared to existing models in memory, and then updates the model as necessary, because things change all the time,” he says.
Business Model
Anodot is a clustered SaaS application that’s hosted on Linux servers in the AWS cloud. Much of the application was built with open source software, including Cassandra, which is used as the real-time data store, and Kafka, which is used to feed data into the system. ElasticSearch is used to index the data and power search, while a Hadoop cluster equipped with Hive and Spark engines is used for offline learning. Archival data is stored in Amazon S3.

Anodot’s architecture, according to its white paper
Anodot is currently in production at a number of customers, including Credit Karma; the media company PMC; the clothes conglomerate VF; and the Rubicon Project, an ad exchange. About 40% of Anodot customers are publicly traded companies, including one major social media network that’s an Anodot customer, as well as Microsoft, which uses it to track mobile usage of Office 365 customers. The company currently analyzes 5.2 billion data points per day on behalf of its customers.
“The team we sold to was a team of data scientists,” Cohen says of Microsoft. “They were tasked with [building the real-time anomaly detection system], but they had a lot of additional things they could work on that are even more core to being in business for Office.”
The biggest competitor to Anodot is the roll-your-own approach, says Cohen. However, it would take a team of about 15 experienced data professionals three years to cobble together their own product that does what Anodot does.
For that reason, don’t expect Anodot to open source its intellectual property any time soon.
Related Items:
Hadoop at Strata: Not Exactly ‘Failure,’ But It Is Complicated
Data Science Operationalization in the Spotlight at Leverage Big Data ’16
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States