

January 30, 2017
Why Deep Learning, and Why Now

(TZIDO SUN/Shutterstock)
Deep learning is all the rage today, as companies across industries seek to use advanced computational techniques to find useful information hidden across huge swaths of data. While the field of artificial intelligence is decades old, breakthroughs in the field of artificial neural networks are driving the explosion of deep learning.
Attempts at creating artificial intelligence go back decades. In the wake of World War II, the English mathematician and codebreaker Alan Turning penned his definition for true artificial intelligence. Dubbed the Turing Test, a conversational machine would have to convince a human that he was talking to another human.
It took 60 years, but a computer finally passed the Turing Test back in 2014, when a chat bot developed by the University of Reading dubbed “Eugene” convinced 33% of the judges convened by the Royal Society in London that he was real. It was the first time that the 30% threshold had been exceeded.
Since then, the field of deep learning and AI has exploded as computers get closer to delivering human-level capabilities. Consumers have been inundated with an array of chat bots like Apple‘s Siri, Amazon‘s Alexa, and Microsoft‘s Cortana that use natural language processing and machine learning to answer questions.
Now, companies across all industries are looking to leverage their big data sets as a training ground to develop sharper AI programs that can interact with the world in ever-more natural ways, and extract useful information from it in ways that have never been done before. Researchers have found that the combination of advanced neural networks, ready availability of huge masses of training data, and extremely powerful distributed GPU-based systems have given us the building blocks for creating intelligent, self-learning machines that can begin to rival humans in their perception.
Understanding Is Key
As Google Fellow Jeff Dean explains, the rapid evolution in big data technologies over the past decade has positioned us well to now imbue machines with near human-level understanding.
“We now have a pretty good handle on how to store and then perform computation on large data sets, so things like MapReduce and BigTable that we built at Google, and things like Spark and Hadoop really give you the tools that you need to manipulate and store data,” the legendary technologist said during last June’s Spark Summit in San Francisco.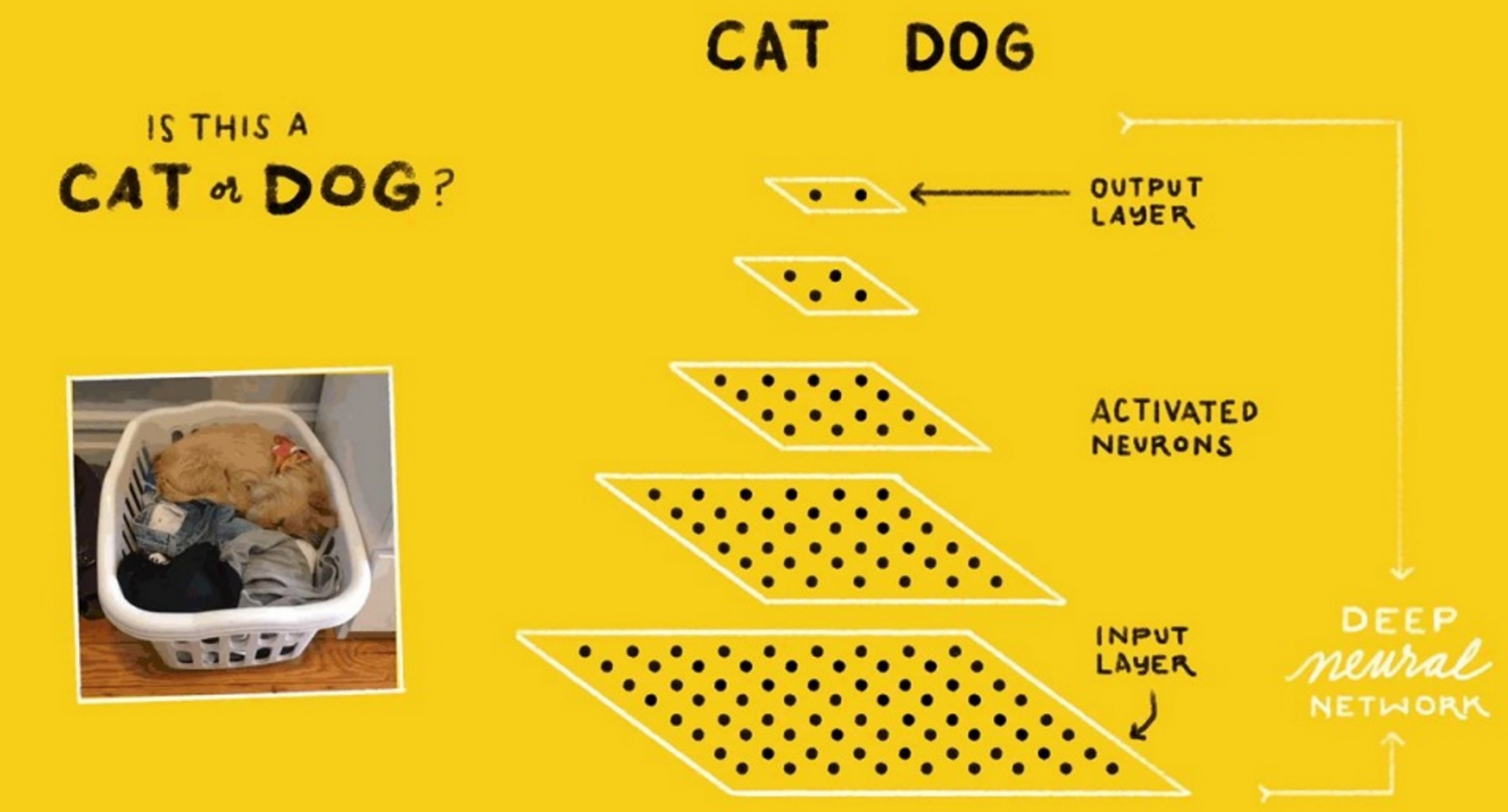
“But honestly, what we really want is not just a bunch of bits on disk that we can process,” Dean continues. “What we want [is] to be able to understand the data. We want to be able to take the data that our products or our systems can generate, and then built interesting levels of understanding.”
Much of the AI work taking place these days involves application in several specific areas where rule-based programming has proved insufficient, such as image recognition, speech recognition, and language understanding. TensorFlow, which Google open sourced in 2015, is a popular framework for developing these sorts of deep learning applications.
Reproducing these seemingly simple tasks in a computer has stymied the best computer scientists for decades. But now the combination of advanced neural networks, ready availability of huge masses of training data, and extremely powerful distributed GPU-based systems have given us the building blocks for cracking the code, and creating intelligent, self-learning machines that can start to rival human perception.
Deep Neural Networks
Most of the breakthroughs in machine learning have involved deep neural networks, which is closely associated with deep learning.
A neural network, in its simplest form, is composed of multiple layers of interconnected nodes that are arranged in a manner similar to neurons in the human brain. Training data, such as images of dogs, are fed into an input layer, which in turn feed the data into any number of hidden layers where pieces of the image are processed and weighted functions are applied.
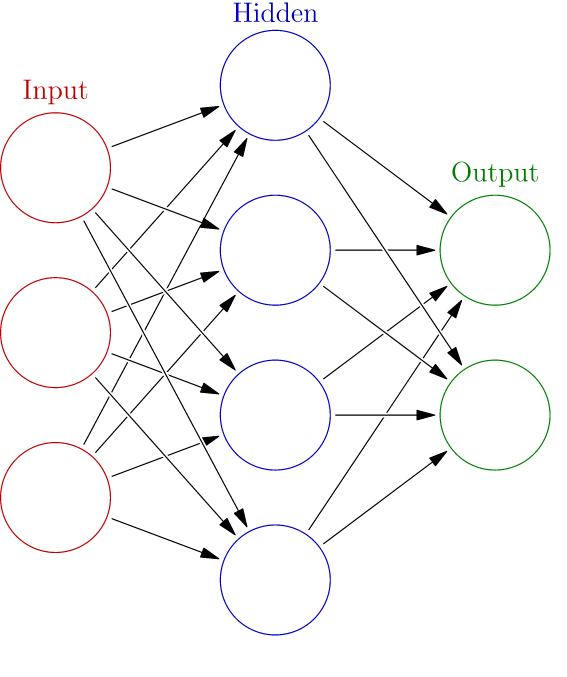
A basic neural network (image credit: Glosser.ca)
Networks can be fairly simple, with just two layers, or they can be complex, with many different layers and encompassing many nodes on a cluster. Single-layer perceptron networks are the simplest type of feedforward networks, and lack hidden layers, while multi-layer perceptron networks contain one or more hidden layers.
After processing a piece of data through all the various nodes, the neural network spits out an answer through the output layer. If the answer is accurate, such as by accurately identifying a dog from an image, then the nodes won’t need many changes. However, if the answer is wrong based on pre-identified training data, the network will automatically make small changes to its weights.
This is referred to as the backpropagation of errors in a supervised learning environment. The backprop and subsequent changing of the weighting factors can be handled either by a human operator, or handled automatically by an algorithm. As the network is fed with more data over more training cycles, it “learns” from its mistakes and gets better at approximating the outcome.
Abstracted Reality
More advanced forms of neural networks include recurrent neural networks, where data is cycled within the hidden layers and backprop is handled automatically by algorithms. With the advent of complex multi-layered neural networks running on distributed GPU, deep learning has opened up new possibilities for AI.

The most advanced recurrent neural networks are able to determine what features matter the most for a given job, like identifying dogs in pictures
The ultimate source of deep learning’s power is how it enables computers to break down the input into elemental bits and then build an abstraction layer above it that corresponds with our perception of reality.
“These systems work because they’re very powerful and they build these layers of abstraction automatically in the course of trying to learn to accomplish this task, which is to learn this function that you’re trying to train it to do,” Dean says. “They can learn really complicated functions from data, and by functions, I don’t mean y(x) squared. I mean something very different, like you take in raw pixels and you can output a word–that is, what is in that image.”
This isn’t much different than how humans learn. As babies, we learn to associate the word “dog” with an image of a dog. As we grow up, we build more advanced models of reality upon those base understandings. Neural nets work the same way, and are able to improve their accuracy as they’re trained on ever bigger data sets.
“A really nice property that neural nets have is the results tend to get better if you train them on more data, and use a bigger model, and that generally requires more computation,” he says. “But if you do that, you can get really amazing results.”
New Frontiers
The field of deep learning is exploding as researchers and developers seek to find fine-tune their approaches and find innovative and creative new ways to apply their new-found capabilities. It’s got the attention of IBM, which recently declared that it’s the Red Hat of deep learning, while Intel is basing its future chip strategy on its ability to attract AI workloads to the X64 architecture.
Much of the most cutting-edge research in applied deep learning is taking place at the Web giants. Facebook, for instance is researching how to build intelligent machines that can help people in their daily lives, such as a program that can help blind people by detecting objects it sees in a photo and narrating the results to the user, all through a smart phone.

Hyperscale data centers are powering the most complex deep learning models
“What makes us intelligent is our ability to learn, and this is what we’re trying to reproduce in machines,” says Lecun, who is director of Facebook AI Research. “What we can do with current technology is build networks of simulated neurons, on the order of magnitude of the brain of a mouse.”
Amazon is also using deep learning techniques with Echo, it’s smart home interface, while Microsoft has continued to push the accuracy levels of the speech recognition technology used in Bing to new heights. Google itself uses deep learning with its voice-enabled search functions and its DeepMind group’s WaveNet program , which can understand what people are saying with ever more accuracy thanks to training on the raw waveforms of billions of utterances from people.
It takes a lot of computer horsepower to train a neural network to accurately understand what a person is saying or to identify a dog, Dean says. “It’s a very computationally intensive process,” he says. “These models have lots and lots of floating point operations involved in them. But ultimately they can do pretty powerful things.”
Related Items:
GPU-Powered Deep Learning Emerges to Carry Big Data Torch Forward
Deep Neural Networks Power Big Gains in Speech Recognition
Applications:
Artificial Intelligence
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States