

January 24, 2017
Kinetica Aims to Broaden Appeal of GPU Computing

(sakkmesterke/Shutterstock)
Kinetica today unveiled a new iteration of its in-memory, GPU-accelerated database that it says will help to democratize data science and traditional business intelligence by simultaneously running SQL-based queries and machine learning/deep learning workloads on the same data.
The San Francisco company says it accomplished the feat by delivering new user defined functions (UDFs). The UDFs have direct access to the CUDA APIs that the Kinetica database uses, and can receive data, do arbitrary functions, and save output to a global table in a distributed manner, the company says. This will allow SQL-loving data analysts to access the processing power of Kinetica clusters through simple API calls that wrapper the SQL queries, it says.
The new UDFs also open the door to supporting any deep learning or machine learning models developed using libraries like Torch, Caffe, BiDMach, and TensorFlow, the company says. These models will be automatically be able to leverage the full parallel processing capability available through Kinetica. These capabilities will be available to data scientists (who will want to have their hands on the code to tweak it), as well as data analysts who are accessing data and processes in Kinetica via APIs.
“We kind of call this the democratization of data science,” says Eric Mizell, vice president of global solutions engineering for Kinetica. “We say, let the data scientists decide the best algorithms to use and do the research. They’re going to find the insight…But if I can take the common algorithms that people are familiar with–Monte Carlo, linear regression, random forest..and if I can enable them to make API calls with the data that’s in Kinetica, then I can give them advanced analytics that they just don’t have today. That’s the basis of why we’re doing this.”
Centralizing the hard-core data science work that involves machine learning as well as the business intelligence work that involves SQL, on a centralized platform helps to eliminate the need to move data from data warehouses or data lakes to GPU-equipped HPC clusters, which is where Kinetica runs.
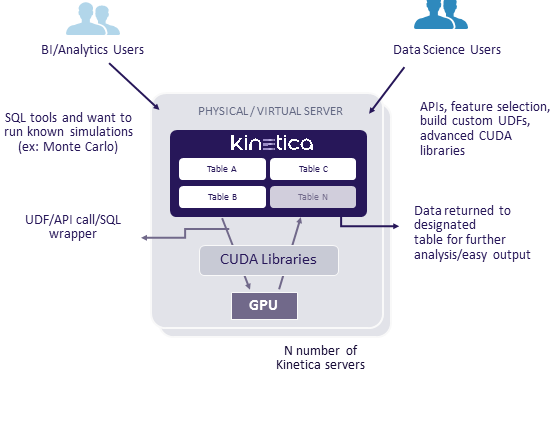
Kinetica envisions its GPU-powered database being used by SQL-loving BI power users as well as ML algorithm-wielding data scientists.
“There’s a lot of data movement. You need to take your data a different group that does data science that understands that to run these libraries takes a lot of code,” Mizell tells Datanami. “You need to be a data scientist to write Java, Python, C, or CUDA for that as well. And typically the business users don’t know those types of languages, so if we can bring it to them as an API call or a SQL wrapper, then they can take advantage of it on their own without having to write the code.”
The idea behind the UDFs is to let the data scientists continue to write the code, to register the code in the Kinetca database, and then enable data analysts to call that code. That eliminates the need to move lots of data or to orchestrate logic to make it run, Mizell says. Currently, the UDFs support API bindings in C, C++, and Java. Support for Python is in the works.
The company, which was formerly called GIS Federal, has also updated its front-end visualization. The company has always utilize the power of GPUs to help render the user interface, but the old HTML5- and JavaScript-based interface lacked the sophistication to enable much interactivity on the data.
The new visualization framework, dubbed Reveal, enables Kinetica users to visualize and analyze billions of data points in an interactive and instantaneous manner. Users can create dashboards in drag-and-drop fashion, and utilize an array of widgets to build sophisticated capabilities into their visualizations.
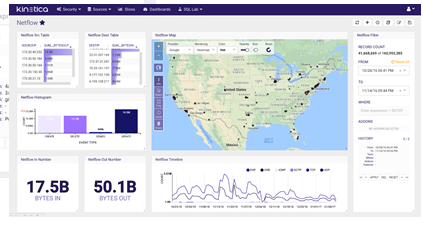
Kinetica’s new Reveal visualization framework lets users work with data more interactively
Reveal gives users access to map data from their provider of choice, including Esri, Google, Microsoft Bing, and MapBox. Reveal is based on Caravel, an open-source visualization tool that Airbnb developed on top of the D3 framework. “It’s a great framework to build on versus what we had before, which was a dumb old UI,” Mizell says.
Lastly, the company has delivered a performance boost through utilization of video memory, or VRAM. The company’s database resides in regular RAM, but it’s discovered it can get a speedup by pinning some data in VRAM, and thereby bypassing the need to send data down the PCI bus.
Mizell says Kinetica developed the capability in response several customers who were using the GPU-powered database to serve up location-based analytics, and wanted the queries to move a little faster. “They’ve got this great UI they built, their own custom UI,” he says. “It serves up 20 little dashboards and they wanted it to respond in under a second. So we needed every query to be 30 milliseconds.”
The VRAM boost will help tie the company over until the NVLink communication protocol being developed by NVIDIA is in full production. NVLink will deliver a 4X performance boost over the PCI bus, increasing data delivery speeds from about 20GBps to 80GPps.
“The idea eventually is the system RAM will be used for both GPU and CPUs,” Mizell says. “So that will solve that bottleneck. But having that VRAM boost helps with specific SLA and certain data sets.”
Related Items:
GPUs Seen Lifting SQL Analytic Constraints
How GPU-Powered Analytics Improves Mail Delivery for USPS
GPU-Powered Terrorist Hunter Eyes Commercial Big Data Role
Applications:
Artificial Intelligence
Tags:
analytics, big data, Caffe, deep learning, Fast analytics, fast data, GPU, machine learning, TensorFlow, Torch
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States