

December 14, 2016
CrateDB Tackles Machine Analytics with Scale-Out SQL Database

Developers who want to analyze big, fast-moving machine data without the complexity of a NoSQL database have another option in CrateDB, an open source, scale-out SQL database that just became generally available today.
The CrateDB project began two years ago when a group of German programmers felt dissatisfied with the database options available to them for storing and analyzing fast-moving machine data, including security log files and sensor data from the Internet of Things.
“There are a lot of SQL databases, like Postgres,” CrateDB CEO Christian Lutz says. “But you can’t scale Postgres very easily. It’s quite complicated. A normal SQL developer can’t just scale it into a cluster of 100 nodes that he would need to press the data that’s required, or even five nodes.”
Lutz and his colleagues liked the scalability that NoSQL databases, such as Apache Cassandra, Splunk, and Elasticsearch, could provide. But those databases each bring their own disadvantages, the primary one being the lack of a native SQL interface that most developers can easily work with. (The proprietary nature of Splunk was also a concern, as was the difficulty in managing large Cassandra databases, they said.)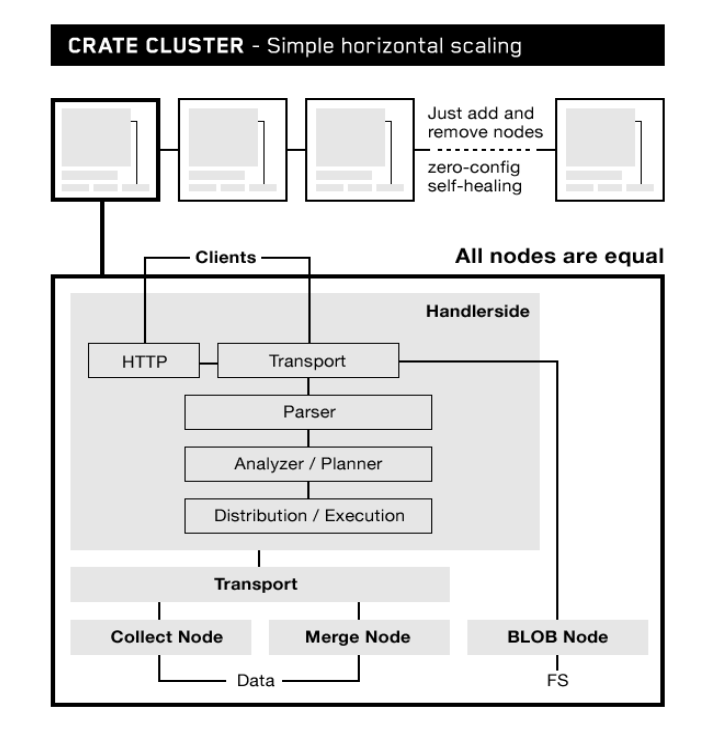
So instead, Lutz and company created CrateDB, which they say combines the natural scalability of NoSQL databases with the SQL interface of standard relational databases. “It allows millions of mainstream SQL developers to access this functionality with standard SQL commands, and hides the complexity of the cluster and issues of NoSQL database behind a SQL interface,” Lutz says.
CrateDB has checked a lot of the boxes that today’s prospective developer is looking for in a big data database. On the NoSQL front, CrateDB offers:
- An open source Apache 2.0 license;
- Scalability via a shared-nothing architecture, with sharding, load-balancing, and failure recovery baked into the code;
- Support for unstructured data, such as JSON objects, in additional to regular tabular data;
- Support for dynamic schemas, thereby enabling developers to evolve the database over time.
But CrateDB also has attributes of a regular relational database (i.e. SQL) database, including:
- Support for standard ANSI SQL queries;
- PostgreSQL wire protocol compatibility;
- Support for outer-joins, a rarity among scale-out databases.
CrateDB’s focus is squarely on machine data analytics. The database was developed to be able to ingest millions of records per second across tens of thousands of connections, and to run standard SQL queries across that data with latencies measured in the milliseconds.
Like NoSQL databases, CrateDB is eventually consistent. That is, it sacrifices a bit of consistency in the data in exchange for higher levels of availability and partition tolerance. The database does not support transactions, as most standard relational databases do. A bank would not use this for its core systems (although it might use it for IoT-related use cases).
The secrete sauce of CrateDB is the distributed query engine. “That’s the part that’s taking the SQL query, translating it to a execution plan that’s running this cluster and then executing it on the nodes,” CrateDB COO Jodok Batlogg tells Datanami. “To allow this, we are using various combinations of caches, columnar caches like you might use in a columnar database.”
CrateDB offers more scalability than other scale-out relational databases, which are often called NewSQL databases. Compared to MemSQL or VoltDB, which are in-memory NewSQL databases, CrateDB can handle much more data – measuring into the tens or hundreds of terabytes.
The typical customer runs CrateDB on a cluster of 10 to 100 standard X86 servers. While the software has been tested on a 1,000 node cluster in the Microsoft Azure cloud, CrateDB doesn’t expect that sort of scale to appeal to customers with machine analytics use cases.

CrateDB hopes to create a new machine data stack based on open source software
There is a bias towards reads in CrateDBs, as opposed to writes. While CrateDB can ingest data quickly and write it to disk, the database was really developed to enable very fast and efficient reads (or queries) on that data. In that sense, it
“Compared to other databases, ingest in CrateDB is slightly more expensive,” Batlogg explains. “But we have more advance indexing and also more advanced caching technologies to make queries faster. The sweet spot is where you have read and write at same time and the read acceleration [allows you to run] more complex queries–this is where we’re really good…We’re really for lots of small queries that have a random workloads across the data.”
CrateDB expects to compete against Apache Cassandra, which is backed by Datastax, only at the upper end of its scale.
“Cassandra is more efficient on writing than we are. But if you want to do a query that Cassandra hasn’t been optimized for, or if you want a dynamic cluster that you want to scale up and down, that’s a problem,” Batlogg says. “We’re much easier to handle and we’re more flexible. If Cassandra is a bulldozer, then we’re an off-road buggy.”
The software became generally available today, but more than 1,000 companies have started using it, including some in production. One of those is SkyHigh Networks, which offers security analytics on log data for hundreds of Fortune 500 companies. According to CrateDB, SkyHigh replaced a combination of MySQL and Elasticsearch database with CrateDB, and got 20x better improvement with 75% fewer servers.
Space-Time Insights, a big data analytics company that we have profiled at Datanami, is another early adopter of CrateDB. The company is using CrateDB to house weather-related data arriving at the speed of 200,000 rows per second. Space-Time Analytics then uses Spark-based machine learning algorithms developed in Scala to analyze the data on behalf of its clients.
You can expect to hear more from CrateDB, which recently moved its headquarters to San Francisco, in 2017. Like other commercial open source vendors, the company will offer technical support subscriptions. And there will also be proprietary add-ons that enterprise customers can purchase to extend the database. At the top of the list are features like security, monitoring, and cross data-center replication, just like Cassandra has.
Related Items:
A Virtual Reality Lens for Big Data Visualization
Elastic Stack Searches for Bigger Data Problems
Forrester’s Crowded NoSQL Wave Shows Abundant Options
Technologies:
Middleware
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States