

November 29, 2016
Birst Dishes Up Data Prep, ML Automation, and More

(Sergey Nivens/Shutterstock)
Groups of data scientists and regular users will be able to collaboratively prepare and share their data for analysis with the latest release of Birst’s analytics platform. Version 6 of the company’s suite also adds more automated smarts through tactical applications of machine learning, and extends the company’s advancements in lineage tracking.
Birst develops a well-regarded SQL-based analytics application that was developed from the beginning to run on multi-tenant cloud architectures. The software, which can be used on-premise or as a SaaS offering, stores data in column-oriented databases, such as Amazon Redshift, SAP HANA, or Exasol, while users interact with the data and create visualizations using Web and mobile interfaces.
As a full-stack data analytics vendor, one of the analytic tasks that Birst tackles is data prep. As you probably know, data prep is the scourge of data analytics, consuming upwards of 70% of analysts’ and scientists’ time. The ecosystem has responded with a slew of stand-alone data prep tools that can significantly reduce that time suck by automating many of the data cleansing and transformation steps through rules-based techniques or machine learning technology. Many of these tools run atop Apache Spark, which itself is a powerful, distributed tool for data prep.
These self-service tools have generally been well received by the market, which has been quite keen to move analytics away from the domain of the IT department and into the hands of the business users themselves. However, the success these vendors have had only serves to put targets on their backs that purveyors of full-stack analytic suites (like Birst) are only too happy to aim at.
Collaborative Data Preparation
It’s no great surprise, then, making data preparing easier and more productive was a big focus with Birst version 6. According to Birst CMO Carl Tsukahara, the company takes data prep a step farther by introducing the concept of collaborative, or networked, data preparation involving multiple active parties.

Version 6 introduces data preparation to the Birst platform
“The general feeling here is things in the industry have become way too siloed,” Tsukahara tells Datanami. “You buy a desktop analytics tool and maybe you can get some data prepared, but it gets stuck there. It becomes a physical element of data sitting on your individual machine.”
Birst claims its “networked” data prep approach offers better returns because multiple people can have a hand in prepping the data, which always resides in a centrally located server.
“Instead of being isolated to you as an analyst, [data prep with Birst] is something everybody in organization can plug into, to leverage the work that you’ve done, and not replicate things,” Tsukahara says. “You really have essentially this entire network of people and data able to share and enrich their insights together.”
Visualize Lineage Tracking
Specifically, Birst 6 brings several enhancements to the data prep stage. First, Birst has built better data connectors for bringing in data from sources like Marketo, Salesforce, Google Analytics, and Netsuite. Tsukahara says Birst has “smartened up” those connectors by eliminating the need for users to deal with low-level details and intricacies of individual data sources, which often require users to write additional SQL scripts.
Birst has also bolstered its “visual language” that analysts use while working in the drag-and-drop data prep component. Visual cues have also been added to help analyst during the data enrichment phase, such as when joining a tables from Marketo and Salesforce. “They see that happening as they’re preparing the data, which gives them much more confidence in what they’re doing,” Tsukahara says.
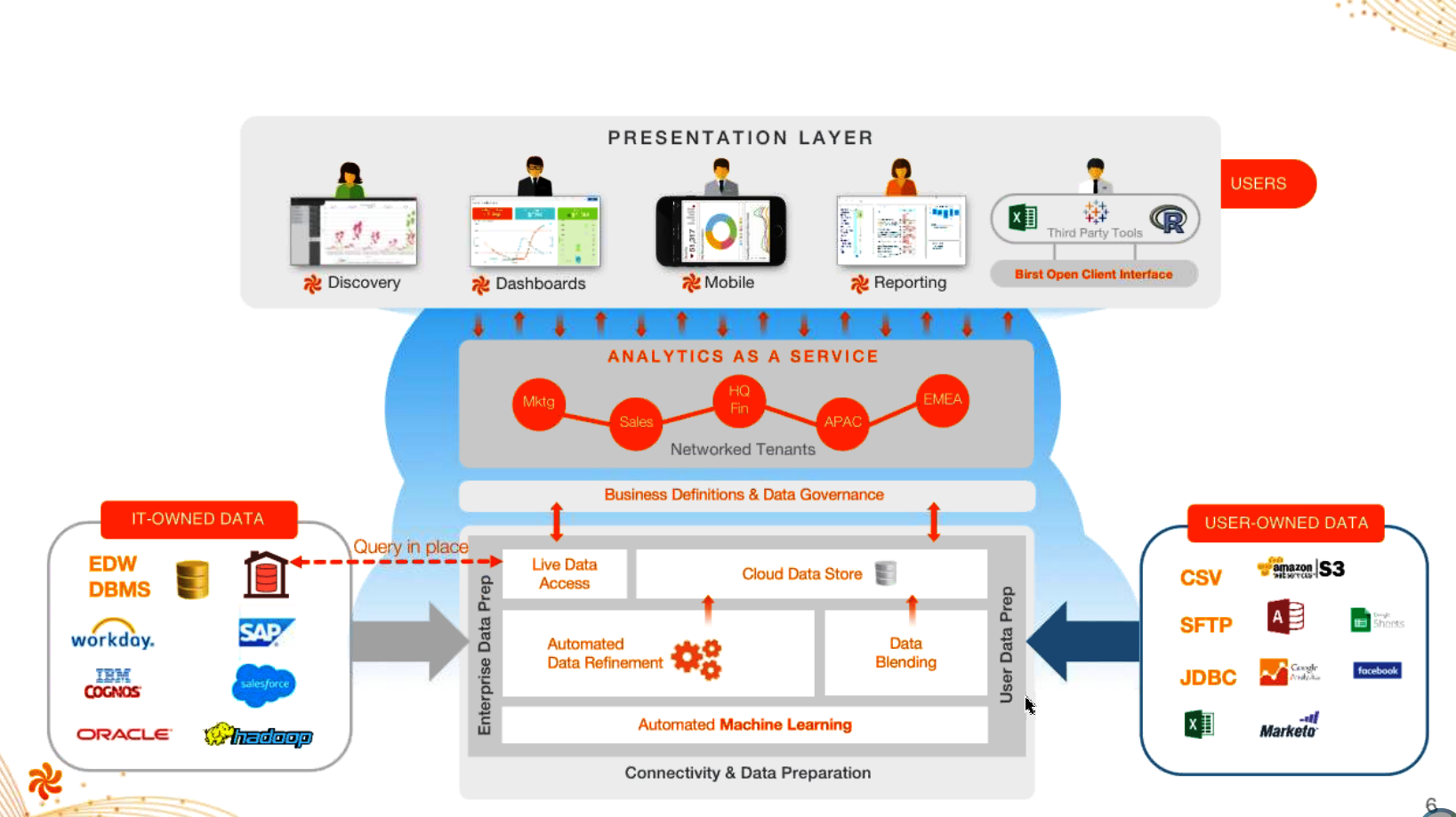
Birst’s full-stack analytic platform
The more data prep and enrichment work that analysts do in Birst, the smarter the software gets, Tsukahara says. “The system will actually show you, ‘Here’s some ways other users have joined these two tables together. Is that the right way for you?'” he says. “So it provides much smarter capability in helping people think through how they’re going to prepare the data in the Birst 6 environment.”
Birst has also bolstered its capabilities around data lineage tracking, which has become a big issue in big data, particularly in Hadoop environments where processing of unstructured and semi-structured data can turn into a mess. Birst isn’t a Hadoop-resident tool, but it has been lauded by Gartner for its “governed data discovery” capabilities.
The lineage of data should always be available, Tsukahara says. “So if somebody else wants to say, ‘Hey how did you get to that campaign performance metric?’ somebody else should be able to visualize how that metric got derived.”
The benefits of this approach are magnified through the networked nature of the tool, and the fact that the system was designed to facilitate sharing of analytic insights, Tsukahara says. The use of desktop tools leads organizations to ship data and files around, which leads to inconsistencies and trust issues.
“That’s where the connected piece is so important,” he says. “We think this is a much more collaborative approach, and really a way to help organizations start to get much more long-term leverage over all this work they’re doing in analytics.”
Machine Learning Everywhere
We know how machine learning is eating the software world, and it’s no different at Birst. The company is using the technology in a variety of ways, including the building of complex models to do predictive analytics. While it’s yet not using machine learning for data preparation, it does have other uses planned for the powerful technology
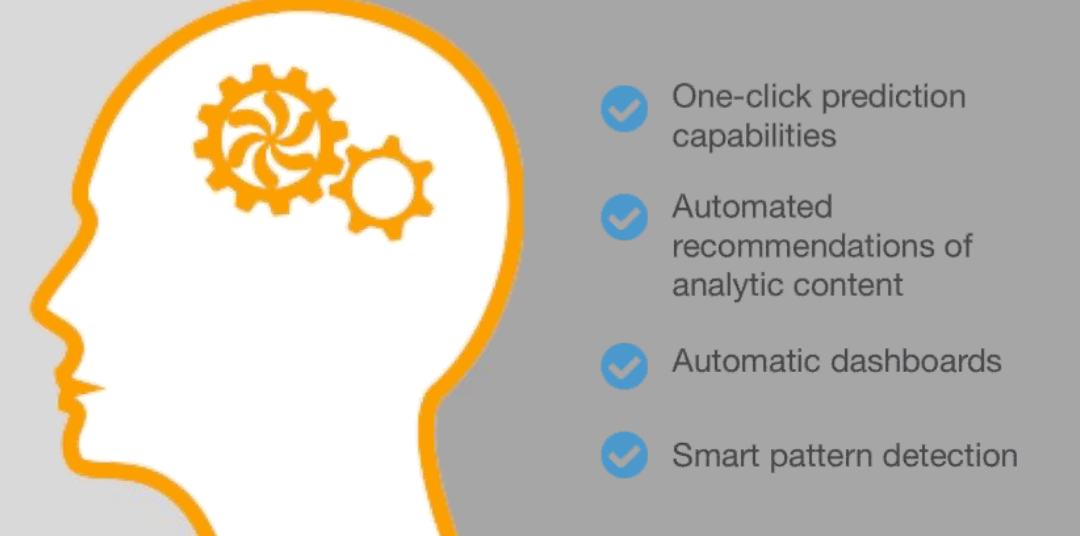
Birst sees multiple uses for machine learning
“In Q1 of next year and throughout 2017, we’ll be adding more machine learning into the product,” Tsukahara says, “not just predictive modeling, but other areas, where we give users more intelligence and recommendations on how to do things based on machine learning.”
That includes using machine learning algorithms to help customers pick the best machine learning algorithms to use for their models. “The reality is most organizations have historical data where certain variables have influenced a certain outcome against key operating metrics,” Tsukahara says. “The key thing is how do you start to make that a much more automated process where the system can start to predict the best fit model for a user case.
Instead of having a data scientists try 10 different models, the software will recommend one for him. “It will help him understand a vector machine is a really bad choice for this particular use case, because the data says that it is,” the Birst CMO says. “So it really helps the person or org figure out what the best fit is, and then over time helps with tuning. This has been part of Birst’s legacy for the past 10 years but we’re really exposing it more broadly because we think the time is now, so to speak, to bring machine learning and predictive modeling more into the business.”
With version 6, Birst has checked many of the right boxes– automated data prep, collaborative analytics, data lineage tracking, machine learning automation–that are pressing issues in big data right now. With the version 6 launch continuing into 2017, it would appear the San Francisco company should definitely be considered a contender among for organizations looking for full-stack solutions.
Related Items:
Tumultuous Times for BI and Analytic Tool Vendors
How Machine Learning Is Eating the Software World
Birst Knows Best for Data Visualization
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States