

November 17, 2016
Yelp Open Sources Data Pipeline That Saved It $10M

Yelp today open sourced a key piece of code that helped it migrate from a monolithic code base to a distributed services-based architecture. Called Data Pipeline, the Python-based product saved the crowd-sourced review website $10 million by simplifying how more than a billion messages per day flows from MySQL through Kafka to big data destinations, such as Hadoop, Redshift, and Cassandra.
Yelp (NYSE: YELP) was formed in 2004 to help people share reviews about local businesses. The San Francisco-based company went public in 2012, and today enjoys revenue of $550 million, mostly by selling advertising that millions of users see across website pages that contain more than 100 million reviews.
Like many companies not formed in the last three years, Yelp had legacy IT considerations to contend with. Most notably, the company was totally reliant on a rather large monolithic app that consisted of about a million lines of code. Scaling the company’s Internet presence to tackle new markets meant scaling “yelp-main,” as the monolithic app was called, and that was neither easy nor inexpensive.
So in 2011, the company embarked upon a major IT engineering effort that would see that single monolithic app broke up into 150 individual production services. This migration to a services oriented architecture (SOA), ostensibly, would make it easier for the company to serve new markets by scaling the services individually. It would also reduce the amount of time required to get Yelp user insights into the hands of the sales team.
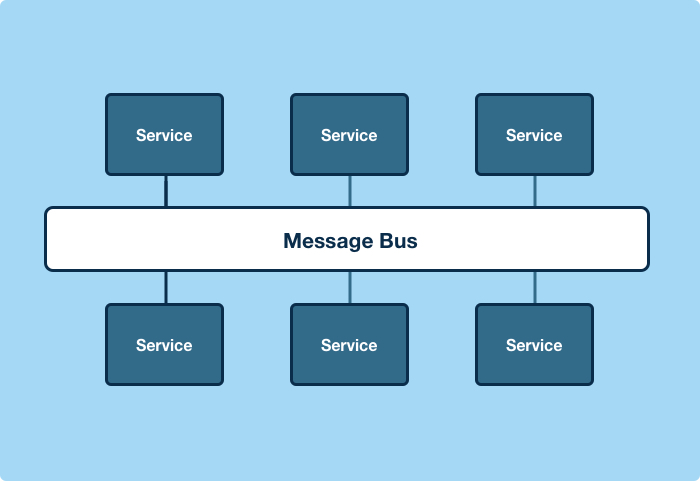
The message bus architecture provides Yelp elegant simplicity compared to a morass of RESTful HTTP connections
However, the move to SOA had its downsides. For starters, getting all those services to talk to one another was a daunting task, particularly if it was done using RESTful HTTP connections, which is largely viewed as a standard method to connect Web services in this day and age.
As Yelp engineer Justin Cunningham explained in a blog post, the math worked against them.
“Implementing RESTful HTTP connections between every pair of services scales poorly,” he wrote. “HTTP connections are usually implemented in an ad hoc way, and they’re also almost exclusively omni-directional. 22,350 service-to-service omni-directional HTTP connections would be necessary to fully connect Yelp’s 150 production services.”
If one were to compare this approach to how the Web works, one would need to create a direct link between your computer and the Web server every time one wanted to view a new website. “That’s woefully inefficient,” he wrote. Consistency was also a problem.
Yelp explored possible solutions. One involved using the bulk data APIs to facilitate the sharing of data. However, this solution shared some of the downsides of the original direct HTTP matrix approach. Plus, it was brittle, Cunningham wrote in the July blog post, titled “Billions of Messages a Day – Yelp’s Real-time Data Pipeline.”
The company finally settled on a solution to the problem in the form of a real-time streaming data platform. The company selected Apache Kafka to serve as the core underlying message broker, which would address scalability and consistency problems.
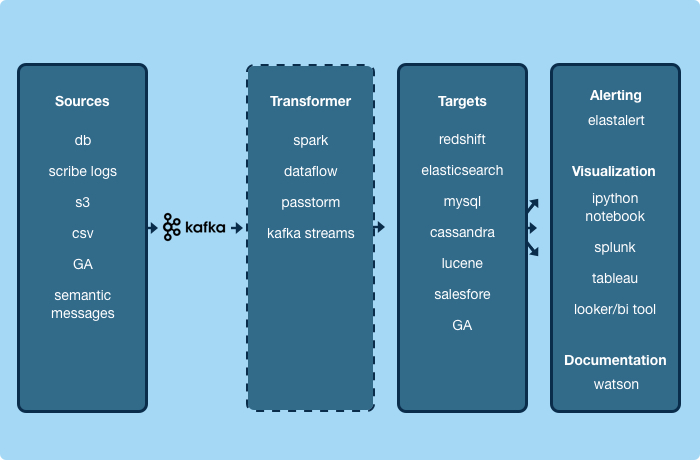
Yelp uses Data Pipeline atop Kafka to control the flow of messages downstream to consuming applications
Yelp also adopted Apache Avro to be the data serialization system. One of the nice features of Avro, Cunningham wrote, is that it supports schema evolution. The producer of data (such as a database) and the consumer of data (such as Redshift or Elasticsearch) don’t have to be on the same exact schema.
Yelp developed a product called the “Schematizer” to take advantage of this schema flexibility with its Avro-encoded data payloads. With Kafka providing guaranteed delivery of messages and consistency, and the Schematizer enabling schema-less Avro data to be sent across the wire as needed, the company had the makings of a real-time data pipeline that was relatively future-proof.
“Messages generated by our logging system are treated exactly the same as messages generated from database replication or from a service event,” Cunningham wrote. “Concretely, as a service author, it means that if you publish an event today, you can ingest that event into Amazon Redshift and our data lake, index it for search, cache it in Cassandra, or send it to Salesforce or Marketo without writing any code.”
What’s more, that same event can be consumed by any other service, or by any future application Yelp builds, without modification, he wrote. This became what Yelp internally called its Data Pipeline, which the company estimates saved it $10 million in hardware and engineering costs the first year it was active.
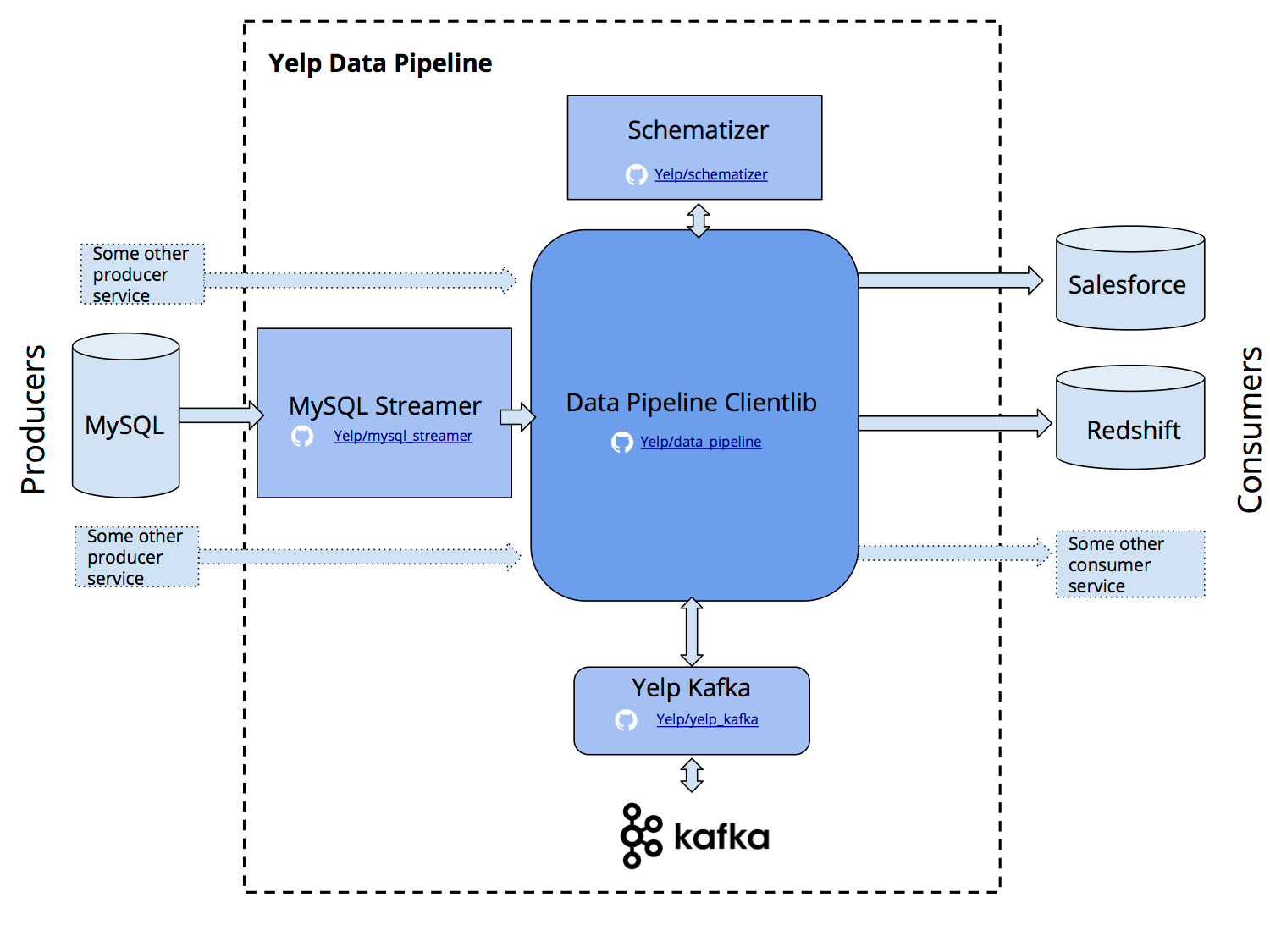
Yelp’s Data Pipeline encompasses several products
“Yelp’s Real-Time Data Pipeline is, at its core, a communications protocol with some guarantees,” Cunningham wrote. “In practice, it’s a set of Kafka topics, whose contents are regulated by our Schematizer service. The Schematizer service is responsible for registering and validating schemas, and assigning Kafka topics to those schemas. With these simple functions, we’re able to provide a set of powerful guarantees.”
Today the company announced via its blog that the Data Pipeline is now open source. In addition to the Schematizer, Yelp is releasing various related projects into open source, including:
- MySQL Streamer, which captures MySQL database changes (inserts, updates, deletes, and refreshes) and bundles them up as Kafka messages, with exactly once guarantees;
- Data Pipeline clientlib, which provides a user interface for producing and consuming Kafka messages;
- the Data Pipeline Avro utility package, which provides a Python-based interface for reading and writing Avro schemas;
- and the Yelp Kafka library, which extends the Python-based Kafka package.
The company decided to open source these components instead of keeping them to itself like a kid with a new toy, explains Yelp engineer Matt K. You might see some duplication in functionality with other products, like Confluent’s Schema Registry and Kafka Connect, which didn’t exist when Yelp started developing Data Pipeline, says Yelp engineer Chia-Chi Lin.
You can download the Data Pipeline and its subcomponents on Github at https://github.com/Yelp/data_pipeline.
Related Items:
The Real-Time Rise of Apache Kafka
The Real-Time Future of Data According to Jay Kreps
What’s Driving the Rise of Real-Time Analytics
Sectors:
Retail
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States